データマイニングとは、有用な情報を得るために大量のデータを分析するプロセスです。学術研究やビジネスの分野で非常に多様な用途があります。研究者はデータ マイニングを使用して計算研究の問題に対する新しい解決策を推測しますが、企業はビジネス収益で優位に立つためにデータ マイニングに依存しています。 Amazon などの企業は、さまざまなデータ マイニング技術を利用して製品レコメンデーション エンジンを改善しています。Google や Microsoft などの検索大手は、それらを活用して検索エンジンの結果を効果的にランク付けしています。一般的にデータ サイエンスに対する需要が高まっているおかげで、Linux 用の強力なデータ マイニング ソフトウェアが過去数十年にわたって数多く出荷されてきました。トップ 20 の Linux データ マイニング ソフトウェアの詳細については、こちらをご覧ください。
機能豊富なデータ マイニング ソフトウェア
データ マイニングは、データの収集、統計分析、人工知能の概念、そしてもちろんプログラミングなど、多くのデータ サイエンスのトピックをカバーしています。ドメインが巨大であるため、データ マイニング ツールにはさまざまな種類があり、さまざまなことを実行するために開発されています。したがって、当社の専門家は、創造的に使用され、現代のデータ エンジニアの要件に完全に対応できる Linux 用の汎用性の高いデータ マイニング ソフトウェアを選択しました。
1.ラピッドマイナー
最新の Linux データ マイニング ソフトウェアの頂点である Rapid Miner は、信頼できるデータ マイニング プラットフォームについて議論するときはいつでも、他をはるかに凌駕しています。以前は YALE として知られていた、強力で柔軟なデータ マイニング スイートであり、マイニング スキルを次のレベルに高めるための堅牢な機能を数多く備えています。 Rapid Miner は Java プログラミング言語の上に開発されており、その名前が示すとおり正確に機能し、データ マイニング プロジェクトを強化します。
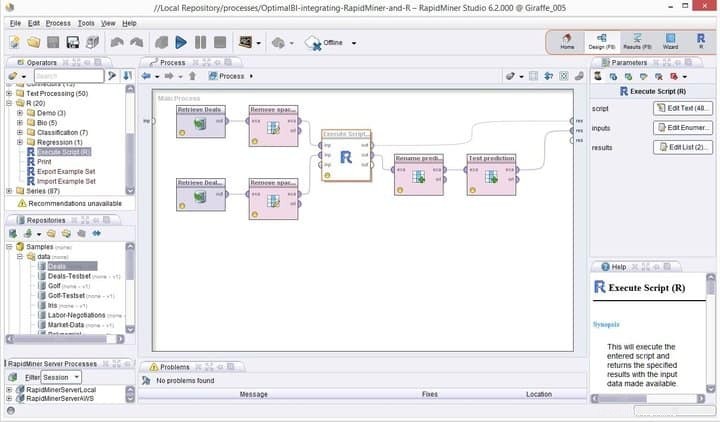
Rapid Miner の機能
- Rapid Miner には、最小限でありながら直感的な GUI インターフェースが付属しており、端末マニア向けのコマンドライン バージョンが追加されています。
- この堅牢で柔軟な予測分析用ビジュアル環境により、ユーザーは明示的なプログラミングなしでビッグデータを分析できます。
- 柔軟な拡張機能の膨大なリストが利用可能で、初回インストール時に取得したものから追加機能を利用できます。
- この Linux 用の強力なデータ マイニング ソフトウェアは、パーソナライズされたデータ マイニング プロジェクトに非常に簡単に統合できます。
2. R
R は、プログラミングの十分な知識を持つ CS の卒業生にとって馴染みのある名前かもしれません。しかし、データ サイエンティストにとっては、はるかに価値があります。簡単に言えば、R はデータとグラフィックスの統計分析のための完全な環境です。これは、モデリング、統計テスト、時系列分析、分類、クラスタリングなどの強力な分析手法を提供する非常に柔軟なデータ マイニング プラットフォームです。あなたが優れたプログラミング スキルを持つプロであれば、R は最強の武器になるかもしれません。
R の機能
- R は、大量の企業データを保存および処理するための堅牢で効果的なソリューションを提供します。
- 豊富な組み込みの一貫したデータ分析ツールにより、エンジニアは幅広いデータ マイニング プロジェクトに R を活用できるようになります。
- R の堅牢なエラー再生機能により、既存のデータ マイニング プロジェクト内の問題を簡単にデバッグできます。
- R は大規模なデータ マイニング プロジェクトに広く採用されており、オープンソース愛好家によって作成済みの膨大な数のソリューションが提供されています。
3.オレンジ
CS のバックグラウンドを持つデータ サイエンティストであれば、Orange については既にご存知かもしれません。それ以外の方は、Python の上に構築された Linux 用の堅牢なデータ マイニング ソフトウェアと考えてください。一般に、Orange は、分類、モデリング、回帰、クラスタリングなどの最新のデータ マイニング技術を、データの視覚化と前処理のためのツールとともに処理できる、柔軟で価値のある一連の Python ライブラリを提供します。
オレンジの特徴
- Orange Canvas と呼ばれる強力なビジュアル プログラミング ツールにより、初心者は生産的なワークフロー管理機能を使用して迅速なデータ マイニング ソリューションを構築できます。
- デシジョン ツリー、属性サブセット、バギング、ブースティングなどのための堅牢なプレミアム ビジュアライゼーション ツールのセットが付属しています。
- 彼らの要件に従って、Orange は GNU GPL ライセンスの下にあるため、プログラマーはこの無料のデータ マイニング ソフトウェアを変更またはカスタマイズできます。
- 今すぐ Orange を選択して既存のデータ マイニング プロジェクトと統合し、100 を超えるビルド済みウィジェットを含む追加機能を利用できます。
4.モア
Massive Online Analysis の略である MOA は、まさにその名前が示すとおりのことを行います。これは、大規模なデータ ストリームのマイニングに重点を置いた、Linux 用の革新的なデータ マイニング ソフトウェアです。 MOA は、意欲的なデータ サイエンティストに強力かつ柔軟なデータ マイニング プラットフォームを提供することを目的としています。これにより、継続的に進化するデータ ストリームでさまざまなデータ マイニング アルゴリズムを効果的にテストできます。 MOA には、分類、回帰、クラスタリング、外れ値検出、推奨システムなど、標準的な機械学習手法の堅牢なコレクションが付属しています。
MOAの特徴
- MOA では、GUI インターフェース、コンソール ベースのインターフェース、オンライン統合用の柔軟な Java ベースの API など、3 つの異なるインターフェース オプションを提供しています。
- 柔軟な変更検出アルゴリズムをパッケージ化して、リアルタイムのデータ ストリームから可能な限り多くの情報を判断します。
- このオープンソースのデータ マイニング ソフトウェアは、マイニング プロセスにリアルタイム データを活用したい人に適しています。
- MOA はオープン ソースの GNU GPL ライセンスを特徴としているため、カスタマイズや変更に法的な手続きは必要ありません
5.ルート
CERN が開発したデータ マイニング プラットフォームに頼ることができますね。 ROOT は、非常に強力な Linux データ マイニング ソフトウェアであり、膨大な量の高エネルギー物理データを含む現実世界の課題を解決します。すぐにさまざまな分野で働くデータ サイエンティストの間で人気を博し、現在ではデータ マイニングや天文データ分析に広く使用されています。あなたが素粒子物理学に深い関心を持つ科学の卒業生であれば、これはあなたにとって真のプラットフォームです。
ルートの特徴
- ROOT は、非常に柔軟なヒストグラム作成機能とグラフ作成機能を使用して、データ分布とマイニング アルゴリズムを非常に便利に視覚化できます。
- この Linux 用データ マイニング ソフトウェアでは、線、多角形、矢印、プロット、ヒストグラムなどの 2D オブジェクトを 3D グラフィック オブジェクトと一緒に分析できます。
- ROOT は、実世界のデータセットを実際に分析するための 4 ベクトル計算ツールと画像操作機能をいくつか提供します。
- ソフトウェアは主に C++ で作成されていますが、Python と R を利用してデータ マイニング機能を最大限に活用しています。
6.データメルト
研究者にもエンジニアにも最適な Linux データ マイニング ソフトウェアの 1 つである DataMelt は、大規模なデータセットを分析するための強力で柔軟な機能の包括的なセットを提供します。これは間違いなく、データ サイエンスのキャリアを後押しすることを楽しみにしている初心者にとって最も便利なデータ マイニング プラットフォームの 1 つです。以前は SCaVis として知られていたこの謎めいたデータ マイニング ソフトウェアは、膨大なオープンソース ソフトウェア パッケージを一貫したインターフェイスにバインドします。
DataMelt の機能
- DataMelt は、Java で大量のデータ操作ツールとプロット ツールを実装し、スクリプト作成のために Jython を利用しています。
- 強力な Python マクロを使用して、データ サイエンティストが実際のデータ、ヒストグラム、3D 構造を視覚化できるようにしています。
- 組み込みの統合開発環境 (IDE) は、柔軟な JAIDA FreeHEP ライブラリを利用し、構文の強調表示、コード補完、プログラム アナライザー、および Jython シェルを可能にします。
- この Linux 用データ マイニング ソフトウェアのオープン ソース ライセンスにより、データ サイエンティストは必要に応じてソフトウェアを拡張できます。
7.ガラガラ
Rattle (簡単に学習できる R 分析ツール) は、R のデータ マイニングおよびバイナリ分類機能への強力なインターフェイスを提供する無料のデータ マイニング ソフトウェアです。また、企業やデータ サイエンティストの専門家向けに、RStat と呼ばれる便利なビジネス インテリジェンス スイートも提供します。 Rattle を使用すると、ユーザーは CSV ファイルまたは ODBC からデータセットをインポートして探索し、データ マイニング ソリューションをモデル化できます。
ガラガラの特徴
- Rattle を使用すると、データ サイエンティストは複雑なデータ モデルを開発および分析し、それらを PMML (予測モデリング マークアップ言語) またはスコアとしてエクスポートできます。
- これは本格的な Linux データ マイニング ソフトウェアであり、企業、政府、研究機関による大規模なデータ マイニングに容易に使用できます。
- CSV、TXT、Excel、ARFF、ODBC、RData ファイル、コーパス、スクリプトなど、膨大な数のソースからデータを読み込むことができます。
- このデータ マイニング プラットフォームの機械学習技術には、決定木、ランダム フォレスト、サポート ベクター マシン、ロジスティック回帰、ニューラル ネットワークなどがあります。
8.エルキ
ELKI は、Java プログラミング言語で書かれた非常に強力な Linux データ マイニング ソフトウェアです。これは、プロのデータ サイエンス認定資格を持っていない人がデータ マイニングにアクセスできるようにすることを目的としています。堅牢なデータ マイニング機能の印象的なコレクションにより、研究および教育機関で最も使用されているデータ マイニング プラットフォームの 1 つです。 ELKI には、クラスタリング、分類、データベース インデックスの管理、外れ値検出など、一般的なほぼすべてのデータ マイニング アルゴリズムのサポートが組み込まれています。
ELKIの特徴
- ELKI には、最小限でありながら洗練されたユーザー インターフェースが付属しており、必要なナビゲーション機能をほぼ備えています。
- 可視化機能には、ヒストグラム、ROC 曲線、OPTICS プロット、平行座標、ボロノイ セル、アルファ形状などが含まれますが、これらに限定されません。
- ELKI は、効果的にインデックスを構築するために、いくつかの R ツリー分割および一括読み込み戦略を採用しています。
- この Linux 用データ マイニング ソフトウェアにより、データ サイエンティストは、堅牢な空間異常値検出機能を使用して地理データを調査および評価できます。
9. KNIME
KNIME は、間違いなく、私たちが実践できる最も革新的なオープン ソース データ マイニング ソフトウェアの 1 つです。非常に包括的で柔軟なデータ マイニング プラットフォームを提供し、データの統合、処理、分析、レポート、および評価タスクのための一貫した機能を誇っています。 KNIME を使用すると、パイプラインと呼ばれる視覚的なワークフローを作成して、データ サイエンティストが複雑なリアルタイム データセットを調査できるようになります。ソフトウェア自体は拡張性が高く、将来のプロジェクトに何の障害もなく統合できます。
KNIMEの特徴
- この無料のデータ マイニング ソフトウェアの GUI インターフェースは非常に直感的で、現代のデータ マイニングに必要な特定のナビゲーション機能を備えています。
- KNIME は Eclipse インタラクティブ開発環境の上にあり、その堅牢な API を活用してオープンソース愛好家に拡張性を提供します。
- 自動化されたスクリプトによるバッチ実行を可能にする、便利なコンソール ベースのユーザー インターフェースが付属しています。
- KNIME は、クラスタリング、ルール誘導、アソシエーション ルール、ベイジアン ネットワーク、ニューラル ネットワークなど、さまざまなデータ マイニング技術をサポートしています。
10.ウェカ
Weka (Waikato Environment for Knowledge Analysis の略) は、Linux 用の強力なデータ マイニング ソフトウェアです。ディシジョン ツリー、サポート ベクター マシン、インスタンス ベースの分類器、クラスタリング、ベイズ ネット、ニューラル ネットワークなどの従来のデータ マイニング手法のアルゴリズムを含む、Java で記述された広範な機械学習ソフトウェアのセットを提供します。 Weka には MOA との双方向統合機能が付属しているため、リアルタイム データ ストリームの処理が必須の分野で頻繁に使用できます。
Wekaの特徴
- Weka の強力なデータ視覚化および処理機能により、大規模なデータセットの評価が、ほとんどの無料のデータ マイニング ソフトウェアよりもはるかに簡単になります。
- 組み込みのグラフィカル ユーザー インターフェース (GUI) は非常に直感的で、機械学習アルゴリズムを比較的快適に適用できます。
- 柔軟な API により、Weka を既存または将来のデータ マイニング プロジェクトに簡単に組み込むことができます。
- Weka’s robust environment allows rewarding data preprocessing abilities to make the most out of industrial or research data.
11. KEEL
KEEL stands for Knowledge Extraction based on Evolutionary Learning, and as the name implies, it is a Linux data mining software for assessing evolutionary algorithms. It is a powerful data mining platform that provides advanced functionalities to help engineers bring new data mining solutions while providing researchers with a mesmerizing platform for scientific undertakings. KEEL is written using the powerful interpreted programming language Java and ships with an open-source GNU GPL license.
Features of KEEL
- The user interface of KEEL is simple in visual, yet it provides all the navigational power required to manage the software effectively.
- It comes with a pre-built set of extensive evolutionary algorithms to predict models, preprocessing methods, and postprocessing procedures.
- KEEL offers over 100 different algorithms for data transformation, discretization, feature selection, noise filtering, and many more.
- It’s among those few data mining software for Linux that comes with extremely accurate data reduction methodologies, alongside functions for extracting rules based on patterns.
12. Apache Mahout
Apache Mahout is one of the most used data mining platforms by professional data scientists due to its substantial empowering features. It is primarily an open source collection of frequently used machine learning techniques and their implementations to help cluster, classify, and frequent pattern recognition in large-scale datasets. Many notable tech giants leverage Apache Mahout for real-time data mining, including Adobe, AOL, Drupal, and Twitter, due to the flexibility it offers.
Features of Apache Mahout
- This data mining software for Linux integrates to the Apache Hadoop stack very well, thus offering an excellent platform for people looking for distributed data mining solutions.
- Data scientists can leverage Mahout on top of Apache Spark as the back-end for implementing flexible and highly scalable data mining projects.
- Mahout comes with native support for CPU/GPU/CUDA acceleration, thus allowing you to leverage the maximum processing power you could get.
13. Sisense
Sisense is arguably among the best data mining software for Linux beginners. It provides data scientists with the specific features they require for diving into massive datasets and discover crucial insights like customer’s shopping habits, search rankings, and other business analytics. Sisense offers a compelling dashboard, making it reasonably straightforward to explore and visualize large amounts of unprocessed data. If you’re coming into data mining from a non-technical background, Sisense might be the best data mining platform for you.
Features of Sisense
- Sisense allows data science professionals to connect with any number of data sources – both structured and unstructured.
- The user interface is very intuitive, and the dashboard provides a highly interactive workflow for visualizing large-scale disparate data sources.
- Sisense can be readily employed in enterprises, government institutions, healthcare management, supply chains, manufacturing, and other types of corporations.
- Sisense allows for a handy drag-and-drop feature empowering data scientists in managing their projects with superior productivity.
14. Databionic
The Databionic ESOM tools offer a plethora of rewarding and flexible data mining techniques such as clustering, visualization, and classification with Emergent Self-Organizing Maps (ESOM) that enable data scientists to analyze large-scale data for business analytics. Developed in Germany, Databionic provides almost every necessary functionalities you’d look for in a modern-day Linux data mining software. It comes under a free and open source GNU GPL license and encourages professionals to tweak the software as they see fit.
Features of Databionic
- This data mining software for Linux is written using the Java programming language and offers maximum portability and extensibility.
- A compelling set of pre-built initialization methods and training algorithms are shipped with Databionic to ease your data mining projects.
- Databionic enables you to effectively visualize high-dimensional and disparate datasets with U-Matrix, P-Matrix, Component Planes, and SDH.
- Users can quickly build personalized ESOM classifiers for automating their data mining tasks with Databionic.
15. Anaconda
Anaconda is an extremely innovative, powerful, and open source data mining software powered by Python, the holy grail of data science programming languages. Industry leaders, including CISCO, Bloomberg, and BMW, utilize this awe-inspiring data mining platform to stay on top of their fellow competitors and curate new analytics solutions. Anaconda is often a mandatory requirement for companies hiring data scientists due to its extensive usage in the field.
Features of Anaconda
- Anaconda allows data scientists to harness the might of data science, machine learning, and AI – all from a single platform and deploy projects with a single click of the mouse.
- This free data mining software comes with an extensive set of pre-built data science packages for Python, R, and Scala.
- Anaconda ships with a BSD license, allowing developers to leverage it to build robust data mining solutions without any legal hassle.
- It is relatively simple to integrate this modern-day data mining software for Linux with other data science software in your arsenal.
16. Shogun
Shogun is, as the developers call it – a unified and efficient machine learning library aimed at solving real-world problems involving big data, and of course – data mining. It is one of the best data mining software for Linux that provides top-notch functionalities and makes sure they can be leveraged as the users want them to. If you’re looking for robust open source data mining software, Shogun might be the perfect tool for you.
Features of Shogun
- Shogun features an extensive range of data mining features, including but not limited to classification, regression, dimensionality reduction, support vector machines, and such.
- It offers a full-fledged implementation of powerful hidden Markov models for enhancing your data mining capabilities right out of the box.
- The user interface is fully hackable and can integrate with futuristic projects too well, thanks to its robust APIs.
- Shogun performs relatively much better than regular Linux data mining software, owing to its gratitude to C++.
17. GNU Octave
GNU Octave is an extremely powerful yet user-friendly scientific computing solution that features a robust high-level programming language similar to MATLAB in many ways. It has widespread usage in the areas of numerical computing and syncs perfectly with most MATLAB implementations. Data scientists can leverage this mesmerizing data science platform for analyzing diverse ranges of real-time data and dig out potentially rewarding insights from them.
Features of GNU Octave
- GNU Octave aims primarily at solving linear and nonlinear numerical problems and runs seamlessly on Linux, macOS, BSD, and Windows.
- The syntax of its high-level programming language is very identical to MATLAB and can operate on both vectors and matrices.
- The powerful mathematics-oriented data visualization capabilities of this Linux data mining software helps in analyzing large amounts of data without requiring external tools.
- The software comes with a GUI interface and a command-line variant for enhancing productivity to the highest level.
18. Apache UIMA
Apache UIMA is highly modular informatics management and analysis system that has gained immense popularity among data scientists due to its compelling data mining functionalities. UIMA stands for Unstructured Information Management Architecture and, as the name already suggests, is an analytic tool for exploring unstructured data. This data mining software for Linux provides a select set of flexible features to discover useful insights from large volumes of disparate data.
Features of Apache UIMA
- It is a Java-based data mining framework for analyzing and evaluating massive datasets involving real-time unstructured data.
- UIMA is hugely scalable and can be used as network services and processing pipelines.
- This Linux data mining software facilitates the analysis of multimedia contents such as audio and video data.
- The software suite comes under an Apache license and is thus free to use and modify by users.
19. Turi Create
Turi is arguably among the most excellent data mining software for Linux we’ve tested during our compilation of this guide. Known previously as Graphlab Create, Turi offers a plethora of robust data science functionalities to build highly modular, scalable data mining solutions. Turi boasts a wide range of diverse, high-performance, distributed computation features and can greatly simplify the development of custom data-mining programs.
Features of Turi Create
- This Linux data mining software is based on graphs and focuses more on tasks than algorithms.
- Although the software doesn’t require any external graphic processing unit (GPU), using one can significantly boost performance.
- Apart from standard text and image data, Turi has built-in support for audio, video, and sensor data.
- It is written using the C++ programming language and is one of the fastest data mining software we’ve tested.
20. ROSETTA
Marketed by the devs as a rough set toolkit for analysis of data, ROSETTA is a general-purpose tool for discernibility-based modeling, with very compelling use cases in the field of data mining. It is a powerful framework for analyzing tabular data and offers some very robust knowledge discovery functionalities. You can utilize ROSETTA in preprocessing large-scale datasets, computing attribute sets, generating rules, and many more.
Features of ROSETTA
- This data mining software for Linux comes with an incredibly intuitive GUI interface with very productive navigational abilities in place.
- Users can integrate this data mining platform with database management systems (DBMSs) via ODBC relatively easily.
- ROSETTA comes with in-built support for both unsupervised and supervised machine learning models.
- The robust set of advanced filtering methods make postprocessing reasonably simple.
結末
Due to its diverse application in real life, data mining software for Linux tends to vary in flavor and functionality. Some of the most popular data mining tools include Rapid Miner, R, Orange, ELKI, MOA, Weka, ROOT, and DataMelt. So, when selecting the right Linux data mining software, you’ve to choose programs that meet your requirements. Hopefully, we could provide you the essential insights on some of the most widely used data mining tools. You should now be able to select the one that does the job for you perfectly. Thanks for your patience, and don’t forget to check us out for regular posts on exciting Linux software and tutorials.