はじめに
gawk command は awk の GNU バージョンです。 gawk は、多くの機能と実用的な用途を備えた強力なテキスト処理およびデータ操作ツールです。
このガイドでは、Linux gawk の使い方を説明します。 コマンドと例。

前提条件
- Linux を実行するシステム。
- ターミナルへのアクセス
- テキスト ファイル。このチュートリアルでは、ファイル people を使用します 例として。
gawk Linux コマンド構文
基本的な gawk 構文は次のようになります:
gawk [options] [actions/filters] input_file
このコマンドは、引数なしでは実行できません。オプションは必須ではありませんが、gawk の場合です。 出力を生成するには、少なくとも 1 つのアクションを割り当てる必要があります。アクションとフィルターは、gawk を有効にする別のサブコマンドと選択基準です。 入力ファイルからのデータを操作します。
注意 :オプションとアクションを一重引用符で囲みます。
gawk オプション
gawk コマンドは、その多数の引数のおかげで用途の広いツールです。 gawk で awk の GNU 実装です 、長い、GNU スタイルのオプションが利用可能です。各長いオプションには、対応する短いオプションがあります。
一般的なオプションを以下に示します:
| オプション | 説明 |
|---|---|
-f program-file 、 --file program-file | 端末の最初の引数の代わりに、スクリプトとして機能するファイルからコマンドを読み取ります。 |
-F fs 、 --field-separator fs | 定義済みの変数 fs を使用します 入力フィールド区切りとして。 |
-v var=val 、 --assign var=val | スクリプトを実行する前に変数に値を割り当てます。 |
-b 、 --characters-as-bytes | すべてのデータを半角文字として扱います。 |
-c 、 --traditional | gawk を実行 互換モードで。 |
-C 、 --copyright | GNU 著作権メッセージを表示します。 |
-d[file] 、 --dump-variables[=file] | 変数、その型、および値のリストを表示します。 |
-e program-text 、 --source program-text | ライブラリ関数とソース コードを混在させることができます。 |
-E file 、 --exec file | 端末変数の割り当てをオフにします。 |
-L [value] 、 --lint[=value] | 他の AWK 実装に移植できないコードに関する警告メッセージを出力します。 |
-S 、 --sandbox | 実行 gawk サンドボックス モードで。 |
gawk 組み込み変数
gawk コマンドには、値を保存してコマンドに追加するために使用される組み込み変数がいくつか用意されています。変数は端末から操作され、ユーザーが変数に値を割り当てたときにのみプログラムに影響を与えます。いくつかの重要な gawk 組み込み変数は次のとおりです:
| 変数 | 説明 |
|---|---|
ARGC | 端末引数の数を表示します。 |
ARGIND | ARGV ファイルのインデックスを表示します。 |
ARGV | 端末引数の配列を提示します。 |
ERRNO | システム エラーを説明する文字列が含まれています。 |
FIELDWIDTHS | 空白で区切られたフィールド幅のリストを表示します。 |
FILENAME | 入力ファイル名を出力します。 |
FNR | 入力レコード番号を表示します。 |
FS | 入力フィールド区切りを表します。 |
IGNORECASE | 大文字と小文字を区別する検索をオンまたはオフにします。 |
NF | 入力ファイルのフィールド数を出力します。 |
NR | 現在のファイル行数を出力します。 |
OFS | 出力フィールド区切りを表示します。 |
ORS | 出力レコード区切りを表示します。 |
RS | 入力レコード区切りを出力します。 |
RSTART | 最初に一致した文字のインデックスを表します。 |
RLENGTH | 一致した文字列の長さを表します。 |
gawk の例
gawk の使用 パターンマッチングと言語処理機能が充実しています。この記事は、ユーザーが gawk ユーティリティの使い方を学ぶための実用的な例を提供することを目的としています。
重要: gawk コマンドは大文字と小文字を区別します。 IGNORECASE を使用 大文字と小文字を区別しない変数。
ファイルを印刷
デフォルトでは、gawk print で 引数は、指定されたファイルのすべての行を表示します。たとえば、people に対して cat コマンドを実行すると、 テキストファイルは以下を出力します:

gawk コマンドは同じ結果を表示します:
gawk '{print}' people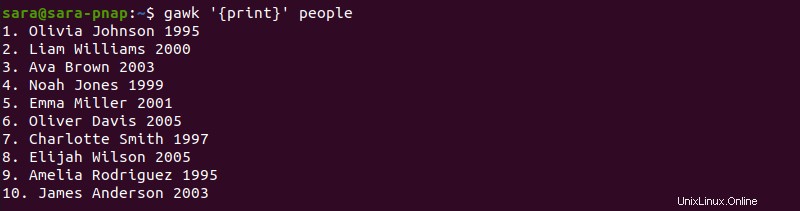
コラムを印刷する
テキスト ファイルでは、スペースは通常、列の区切り記号として使用されます。 人々 ファイルは 4 つの列で構成されています:
- 序数。
- 名
- 姓
- 生年。
gawk を使用 端末の特定の列のみを表示します。例:
gawk '{print $2}' people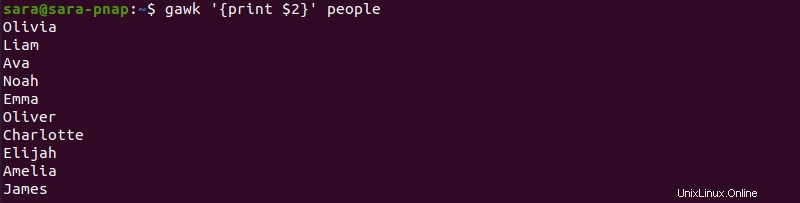
このコマンドは、2 列目のみを出力します。 1 列目 (序数) と 2 列目 (名前) のように複数の列を印刷するには、次のコマンドを実行します:
gawk '{print $1, $2}' people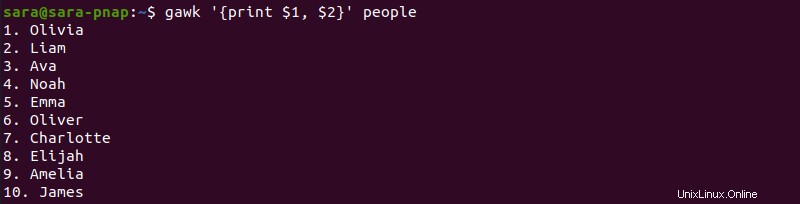
gawk コマンドは $1 の間にコンマがなくても機能します と $2 .ただし、出力の列間にスペースはありません:
gawk '{print $1 $2}' people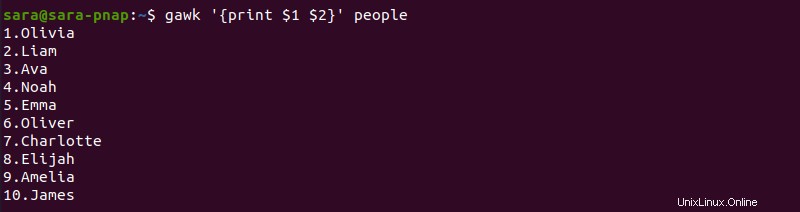
列をフィルタ
gawk コマンドは、追加のフィルタリング オプションを提供します。たとえば、大文字 O を含む行を出力します と:
gawk '/O/ {print}' people
文字 O を含む行のみを表示するには または A 、パイピングを使用:
gawk '/O|A/ {print}' people
このコマンドは、大文字 O の単語を含むすべての行を出力します または A .一方、論理 AND を使用する (&& ) O の両方を含む行を表示する そして年 1995 :
gawk '/O/ && /1995/' people
フィルターは数値でも機能します。たとえば、1990 年代生まれの人のみを表示:
gawk '/199*/ {print}' people
出力には、4 列目に値 199 が含まれる行のみが表示されます .
前述のオプションを組み合わせて、出力をさらにカスタマイズします。たとえば、1995 生まれの人の姓名のみを出力します。 または 2003 と:
gawk '/1995|2003/ {print $2, $3}' people
このコマンドは、{print $2, $3} に記載されているように、2 列目と 3 列目を出力します。 部。出力には、数字 1995 を含む行のみが表示されます そして2003年
gawk このコマンドを使用すると、論理 NOT で指定された文字列を含む行を除くすべてを出力することもできます。 (! )。たとえば、文字列 19 を含む行を省略します 出力:
gawk '!/19/' people
行番号を追加
人々 ファイルには、最初の列に行番号が含まれています。ユーザーが行番号のないファイルで作業している場合、gawk それらを追加するオプションを提示します。
たとえば、人間 ファイルに序数が含まれていません:
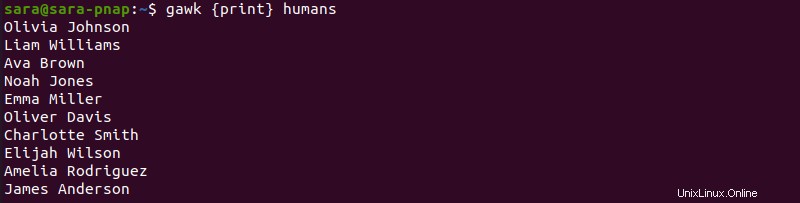
行番号を追加するには、gawk を実行します FNR で そして next :
gawk '{ print FNR, $0; next}' humans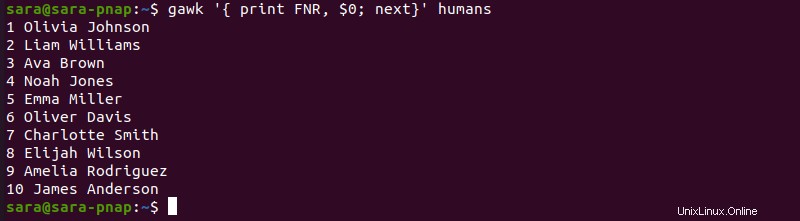
このコマンドは、各行の前に行番号を追加します。 NR でも同じ結果が得られます 変数:
gawk '{print NR, $0}' mobile.txt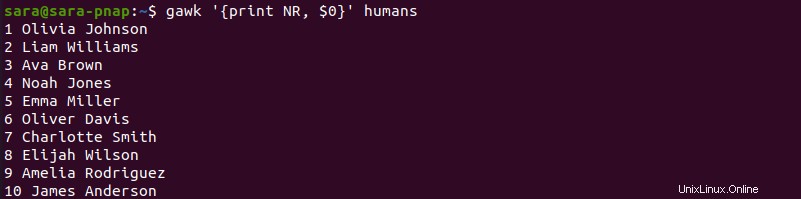
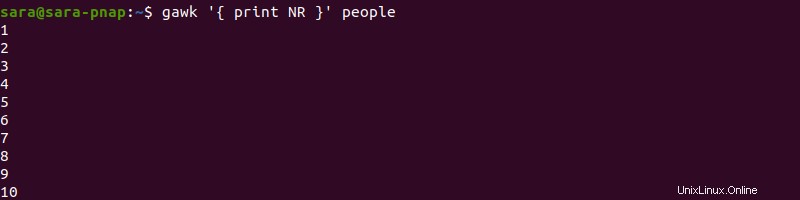
行数を調べる
ファイル内の合計行数をカウントするには、END を使用します ステートメントと NR gawk の変数 :
gawk 'END { print NR }' people
コマンドは各行を読み取ります。一度 gawk END に到達 、NR の値を出力します - 行の総数が含まれています。 END なしで同じコマンドを実行する ステートメントは NR の値のみを出力します - 行数:
長さに基づいて行をフィルタリングする
20 文字を超える行のみを印刷するには、次のコマンド オプションを使用します:
gawk 'length>20' people
複数の引数でも機能します。たとえば、17 よりも長い行を表示します ただし 20 未満 文字:
gawk 'length<20 && length>17' people
ちょうど 20 文字の長さの行を表示するには、以下を実行します:
gawk 'length==20' people
条件に基づいて情報を印刷
gawk コマンドでは、if-else ステートメントを使用できます。たとえば、1999 以降に生まれた人だけをフィルタリングする別の方法 単純な if ステートメントを使用:
gawk '{ if ($4>1999) print }' people
if ステートメントは、列 4 のエントリが 1999 より大きい必要があるという条件を設定します .出力には、条件を満たすエントリのみが表示されます。コマンドを if-else ステートメントに展開して、元の条件を満たさない行を出力します。
gawk '{if ($4>1999) print $0," ==>00s"; else print $0, "==>90s"}' people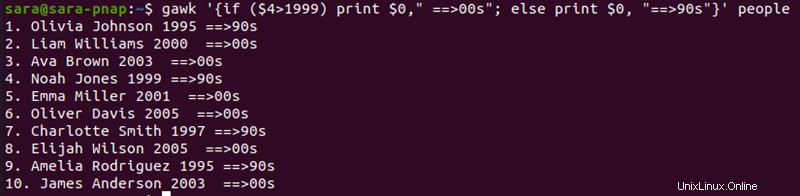
コマンドには以下が含まれます:
- If ステートメント。 条件が満たされた場合、
gawk文字列「==>90s」を追加します " 出力行に - Else ステートメント。 行が条件を満たさない場合、
gawk出力にその行を出力し、「==>00s」を追加します " 文字列を出力します。
ヘッダーを追加
END と同じ方法で このステートメントにより、ユーザーはファイルの末尾にある BEGIN の出力を変更できます。 ステートメントはデータを最初にフォーマットします。
awkで使用する場合 、BEGIN セクションは常に最初に実行されます。その後、awk 残りの行を実行します。 BEGIN を使用する 1 つの方法 ステートメントは、出力にヘッダーを追加することです。
次のコマンドを実行して、awk の上にセクションを追加します。 出力:
gawk 'BEGIN {print "No/First&Last Name/Year of Birth"} {print $0}' people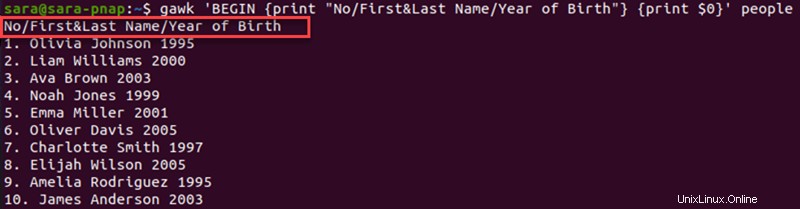
最長の行の長さを見つける
前の引数を if と組み合わせる と END 人々 で最も長い行を見つけるステートメント ファイル:
gawk '{ if (length($0) > max) max = length($0) } END { print max }' people
フィールド数を求める
gawk コマンドを使用すると、ユーザーは NF でフィールド数を表示することもできます 変数。フィールド数を表示する最も簡単な方法は、読みにくい出力を出力します:
gawk '{print NF}' people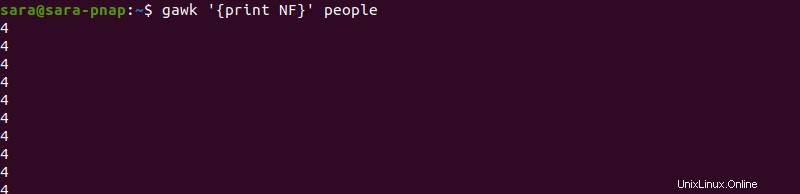
このコマンドは、追加情報なしで 1 行あたりのフィールド数を出力します。出力をカスタマイズして人間が読みやすいようにするには、最初のコマンドを調整します:
gawk '{print NR, "-->", NF}' people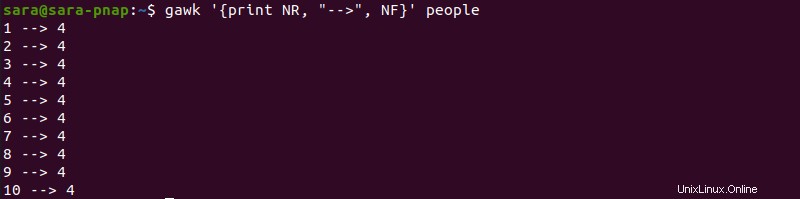
コマンドには以下が含まれるようになりました:
NR各出力行に行番号を追加する変数-->行番号とフィールド番号を区切る文字列
人物に行番号とフィールド番号を表示する別の方法 ファイルは NF で列を印刷することです . 人々 ファイルには、1 列目に序数が含まれています。したがって、NR 変数が省略されています:
gawk '{print $0, "-->", NF}' people
最後に、フィールドの総数を出力するには、次を実行します:
gawk '{num_fields = num_fields + NF} END {print num_fields}' people
ファイルには 10 行と 4 列があります。したがって、出力は正しいです。
結論
このチュートリアルを完了すると、gawk の使い方がわかります。 高度なテキスト処理とデータ操作用。
文字列、単語、パターンを検索するための強力な Linux ツールである grep の使用も検討してください。