過去 5 年間で、データ サイエンス業界は爆発的に拡大し、データ サイエンスの仕事は豊富で高給です。しかし、データ サイエンスを始めるのは難しい場合があります。最大の障害の 1 つは、コンピューターに適切なツールと環境をセットアップすることです。 Anaconda のインストール方法と、それをデータ サイエンスに使用する方法がわからない限り、そうではありません。
Anaconda は強力なデータ サイエンス プラットフォームであり、データ分析、モデリング、視覚化を始めるのに最適な方法です。このチュートリアルでは、Ubuntu Linux に Anaconda をインストールする手順と、いくつかの基本的なデータ操作と視覚化タスクについて説明します。
準備? Linux で Anaconda を使用してデータ サイエンスを始める方法を学びましょう!
前提条件
このチュートリアルは実践的なデモンストレーションです。先に進みたい場合は、少なくとも 4 GB の RAM と 5 GB の空きディスク容量を備えた Ubuntu Linux マシンがあることを確認してください。
Anaconda のインストールに必要な最小ディスク容量は 5 GB ですが、本格的なデータ サイエンス作業を実行するには、さらに多くの空き容量が必要です。データ サイエンスの作業には、データ セットをダウンロードして保存する必要があるため、多くのディスク領域が必要です。マシンに 50 GB の空き容量があれば、データ サイエンスに取り組むには十分です。
Anaconda インストーラー Bash スクリプトのダウンロード
データ サイエンスの初心者でも経験豊富な専門家でも、Anaconda はデータ分析とモデリングのニーズに最適なプラットフォームです。ただし、まず、マシンに Anaconda をインストールする必要があります。
Anaconda をインストールするには、Anaconda の Web サイトから Bash スクリプトのインストーラーをダウンロードする必要があります。執筆時点での最新バージョンは Anaconda3-2021.11-Linux-x86_64.sh です。
1. ターミナルを開き、以下のコマンドを実行して、Anaconda のインストーラ Bash スクリプトをダウンロードし、/tmp に保存します。 ディレクトリ。
cd /tmp
curl -O https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh
2. 次に、以下の sha256sum コマンドを実行して、ダウンロードしたファイル (Anaconda3-2021.11-Linux-x86_64.sh) の SHA-256 暗号化ハッシュを生成します。このコマンドは、MD5 または SHA256 を使用してインストーラ Bash スクリプトの整合性を検証する方法を提供します。
インターネットからファイルをダウンロードすると、転送中にファイルが改ざんされたり破損したりするリスクが常に伴います。インストーラーの Bash スクリプトの整合性を検証することは、Anaconda が最初に公開したファイルと同一のコピーを受け取ったことを確認するために重要です。
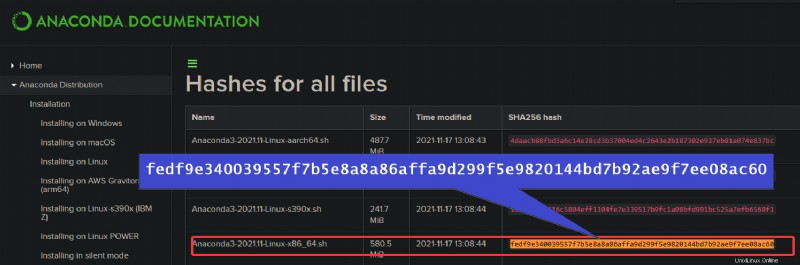
sha256sum Anaconda3-2021.11-Linux-x86_64.shファイルのハッシュを書き留めて、Anaconda の Web サイトで入手できるものと比較します (ステップ 3)。

3. 最後に、お気に入りの Web ブラウザーを開き、Anaconda のハッシュのリストに移動します。
ダウンロードしたインストーラー Bash スクリプトの名前を探します (Anaconda3-2021.11-Linux-x86_64.sh)。見つかったら、ステップ 2 で書き留めたハッシュが Anaconda の Web サイトにリストされているものと一致することを確認してください。
ハッシュが一致しない場合は、手順 1 から 3 を繰り返してハッシュを再確認してください。
Ubuntu への Anaconda のインストール
Bash スクリプトをダウンロードしてその整合性を確認したので、Anaconda をインストールする準備が整いました。インストーラーの Bash スクリプトには必要なインストール コマンドがすべて含まれているため、実行するだけで済みます。
1. 次のコマンドを実行して、マシンに Anaconda をインストールします。 Anaconda3-2021.11-Linux-x86_64.sh を、ダウンロードした Bash スクリプト ファイルの名前に置き換えてください。
シェルに関係なく、bash コマンドを含める必要があることに注意してください。
bash Anaconda3-2021.11-Linux-x86_64.sh2. Bash スクリプトを実行した後、プロンプトが表示されたら、Enter キーを押してエンド ユーザー ライセンス契約 (EULA) を表示します。 Enter キーを押し続けて、EULA の最後までお読みください。
3. EULA を読んだ後、yes と入力して Enter キーを押し、以下に示すようにライセンス条項に同意します。

4. Enter キーを押して、Anaconda のデフォルトのインストール場所を受け入れます。好きな場所を選択できますが、簡単にアクセスできるように、ホーム フォルダー内のディレクトリを選択することをお勧めします。
5. Anaconda3 の初期化を求めるプロンプトが表示されたら、yes と入力して Enter キーを押します。この conda init コマンドにより、マシンにログインするたびに端末から conda コマンドを使用できるようになります。
6. 次に、以下のコマンドを実行して、シェル環境に変更を適用します。
source ~/.bashrc以下に示すように、現在のシェルが base に変わり、Anaconda3 が正常にインストールされたことを示します。 base は、データ サイエンスに必要なすべてのコア Python ライブラリとツールを提供する Anaconda のデフォルトのシェル環境です。
基本シェル環境には、conda、anaconda プロンプト、Jupyter Notebook などの強力なコマンドライン ツールが含まれています。

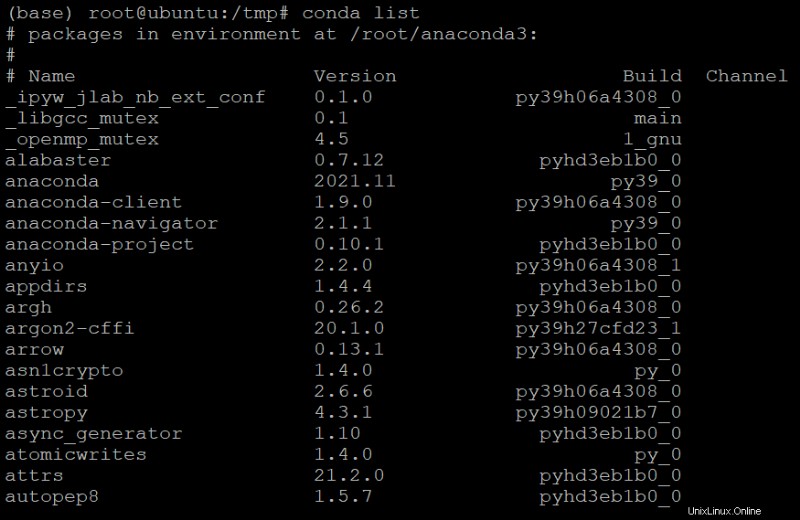
7. 以下の conda list コマンドを実行して、Anaconda が正しくインストールされていることを確認します。
conda list 以下に示すように、現在ベース環境の一部として含まれているすべてのパッケージとバージョンのリストが表示されます。
8. 最後に、以下の conda activate コマンドを実行して、anaconda セッションを閉じます。
conda deactivate
conda activate および conda deactivate コマンドは、conda 4.6 以降のバージョンでのみ機能することに注意してください。 4.6 より前のバージョンの conda の場合は、代わりに次のコマンドを実行します:source activate または source deactivate
Anaconda 環境の設定
マシンに Anaconda をインストールしましたが、Anaconda をデータ サイエンスに使用する前に、環境をセットアップする必要があります。環境は、異なるバージョンの Python とパッケージをインストールできるファイル システム上の個別の場所です。
このセットアップは、異なる Python またはパッケージ バージョンを必要とする複数のプロジェクトで作業する必要がある場合に便利です。
この時点からチュートリアル全体を通して、環境とファイルに任意の名前を付けることができます。
Anaconda 環境をセットアップするには:
1. 以下の conda create コマンドを実行して、Python3 (python=3) を実行する my_env という名前の新しい環境を作成します。
conda create --name my_env python=3
2. 次に、環境の作成を続行するかどうかを選択するプロンプトが表示されたら、y を入力して Enter キーを押します。
3. 環境が作成されたら、以下の conda activate コマンドを実行して、新しい環境 (my_env) をアクティブにします。
conda activate my_env
4. 次に、以下の conda create を実行します data_env のデータ サイエンスに必要な以下のコア Python ライブラリとツールをすべてインストールするコマンド 環境:
scipy– データ分析タスクを実行する科学計算用の一般的な Python ライブラリ。
numpy – 多次元配列を操作するためのライブラリ。
pandas– 表形式のデータを操作するための強力で直感的な方法を提供する、データ分析用の便利なライブラリ
matplotlib– データの洗練された視覚化を作成するために使用されるプロット ライブラリ
conda create --name data_env python=3 numpy scipy pandas matplotlib
5. y を入力して Enter キーを押し、data_env 環境の作成を続行します。
6. 最後に、次の conda env コマンドを実行して、使用可能な環境のリストを確認します。
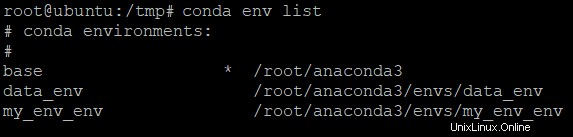
conda env list以下に示すように、ベース環境を含む、マシン上に作成されたすべての環境が表示されます。
初めての Python プログラムの実行
これで、環境が実行されました。これは素晴らしいことです。しかし、プログラムを書かない限り、環境は今のところあまり機能していません。このチュートリアルでは、環境を使用して、簡単な年齢計算 Python プログラムを作成して実行します。
環境で Python プログラムを作成するには:
1. 以下のコマンドを実行して、環境 (my_env) を有効にします。
conda activate my_env
2. 次に、以下のコマンドを実行して Python インタープリターを開きます。 Python インタープリターは、Python コードを対話的に記述して実行できる REPL (read-evaluate-print loop) 環境です。
python3
3. 次のコードをコピーしてインタープリターに貼り付け、Enter キーを押します。
このコード ブロックは、1900 年生まれで 1970 年に減少した人の死亡年齢を計算して出力します。
birth_year = 1900
death_year = 1970
age_at_death = death_year - birth_year
print(age_at_death)以下では、端末に表示された出力 70 を見ることができます。これは、その人が亡くなったときに 70 歳だったことを示しています。
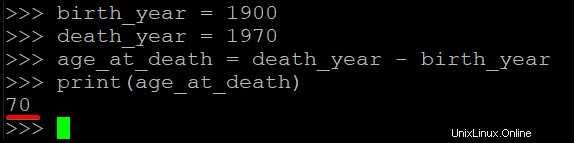
4. 次に、以下の exit() コマンドを実行して Python インタープリターを終了します
exit()
5. 最後に、以下のコマンドを実行して、my_env 環境のセッションを閉じて終了します。
conda deactivate
最初のデータ サイエンス プロジェクトの構築
これまで、環境を使用して簡単な Python プログラムを実行する方法を見てきました。今回は、最初のプロジェクトを作成して、データ サイエンス ゲームを強化します。通常、データ サイエンス プロジェクトには、特定のビジネス ニーズや問題に対処するためのデータの収集、調査、分析、視覚化が含まれます。
最初のデータ サイエンス プロジェクトを構築するには、matplotlib ライブラリを使用して、ライト (X, Y) 散布図でデータをプロットします。
1. 以下の conda activate コマンドを実行して、data_env という環境をアクティブ化します。
conda activate data_env
2. 次に、scatter.py という名前の Python ファイルを作成します。 お好みのテキスト エディタを使用してください。
nano scatter.py3. 次のコードを scatter.py に入力します ファイルを開き、変更を保存してエディターを閉じます。このコード ブロックは、それぞれ 12 の要素を持つ 2 つの配列を作成し、データ ポイントをプロットして表示します。
# Imports matplotlib.pyplot to visualize the plot
import matplotlib.pyplot as plt
# Contains an array of numbers (cars ages) to x.
x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
# Contains an array of nunbers (cars speeds) to y.
y = [99,86,87,88,111,86,103,87,94,78,77,85,86]
# Plot the data points
plt.scatter(x, y)
# Show the plotted data points
plt.show()4. 最後に、以下のコマンドを実行して、画面にプロットを表示する Python ファイル (scatter.py) を実行します。
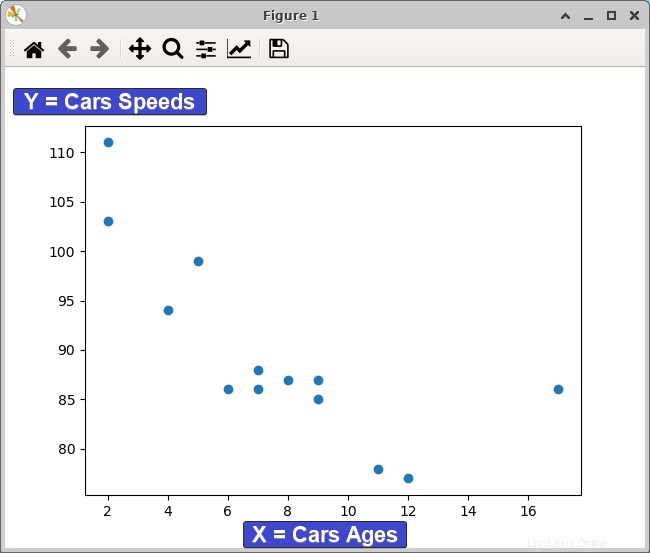
python scatter.py以下に示すように、グラフにプロットされたデータ ポイントが表示されます。車の年数と速度の関係は明確であり、車両の性能を維持または向上させる方法を決定するのに役立ちます。
明らかな関係は、車の使用年数が上がるにつれて、走行速度が低下することです。
また、使用年数と速度の間にわずかな正の相関関係があることに気付くかもしれません。車の使用年数が上がるにつれて、速度もわずかに上昇する傾向があります。この関係は、パフォーマンスと効率のために車両を最適化したい自動車メーカーにとって役立ちます。
そこにあります! Linux に Anaconda を正常にインストールし、最初のデータ サイエンス プロジェクトを作成しました。
環境の削除
環境はストレージを消費します。特に、もう何の役にも立たない環境を保持している場合はなおさらです。それらを削除しないのはなぜですか? conda env remove 削除する環境の名前がわかっている限り、トリックは実行されます。
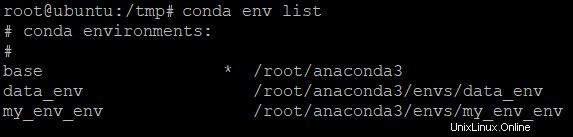
以下のコマンドを実行して、すべての環境を一覧表示します。
conda env list
削除する環境の名前を書き留めます。
次に、次のコマンドを実行して remove にします 名前が付けられた環境 (-n ) data_env . data_env を置き換えます を、削除するターゲット環境の名前に置き換えます。
conda env remove -n data_env

または、パス (-p) を指定して以下のコマンドを実行することもできます。 ) 環境が配置されている場所 (/root/anaconda3/envs/data_env ).
conda env remove -p /root/anaconda3/envs/data_env

結論
このチュートリアルでは、Ubuntu Linux に Anaconda をインストールし、データ サイエンス用の Python 3 環境を作成する方法を学習しました。最初のプログラムを作成し、matplotlib を使用してデータをプロットしました。
この時点で、これらのスキルを備えたデータ サイエンティストとしての旅を始める準備が整いました!
Anaconda Navigator でデータ サイエンスの旅を始めてみませんか?自分のプロジェクトのために、データの探索、分析、視覚化を始めましょう!