Python で統計プロットを作成するのは、特に手動で生成する場合は面倒です。しかし、Seaborn Python データ視覚化ライブラリの助けを借りて、作業を簡素化し、美しいプロットをより少ないコード行ですばやく作成できます。
Seaborn を使用すると、データの美しい統計プロットを簡単に作成できます。このガイドでは、実際の例を通してこの強力なライブラリの使用方法を紹介します。
前提条件
このチュートリアルは実践的なデモンストレーションです。フォローしたい場合は、次のものが揃っていることを確認してください:
- Python と Anaconda がインストールされた Windows または Linux コンピュータ。このチュートリアルでは、Windows 10 PC 上の Python 3.9 で Anaconda 2021.11 を使用します。
Seaborn Python ライブラリとは?
Seaborn Python ライブラリは、Matplotlib ライブラリに基づいて構築された Python データ視覚化ライブラリです。 Seaborn は、統計チャートとプロットを作成するための高レベル ツールの豊富なセットを提供します。 Pandas Dataframe オブジェクトと統合する Seaborn の機能により、データをすばやく視覚化できます。
DataFrame は、表、スプレッドシート、またはカンマ区切り値の CSV ファイルにあるような表形式のデータを表します。
Seaborn は Pandas DataFrame と連携し、内部のデータを Matplotlib が理解できるコードに変換します。
多くの高品質のプロットが利用可能ですが、このチュートリアルでは、最も一般的な 3 つの組み込みの Seaborn プロット ファミリについて学び、作業を開始するのに役立ちます。
- リレーショナル プロット。
- 分布図。
- カテゴリープロット。
Seaborn にはさらに多くのプロットが含まれており、このチュートリアルですべてをカバーすることはできません。 Seaborn API ドキュメントとチュートリアルは、さまざまな種類の Seaborn プロットをすべて理解するための優れた出発点です。
新しい JupyterLab と Seaborn Python 環境のセットアップ
Seaborn の旅を始める前に、まず Jupyter Lab 環境をセットアップする必要があります。また、例との一貫性を保つために、このチュートリアルでは特定のデータセットに取り組みます。
JupyterLab は、コード、リッチ テキスト、プロット、およびその他のメディアを 1 つのドキュメントに結合できる Web アプリケーションです。ノートブックを他のユーザーとオンラインで共有したり、実行可能なドキュメントとして使用したりすることもできます。
環境のセットアップを開始するには、次の手順に従います。
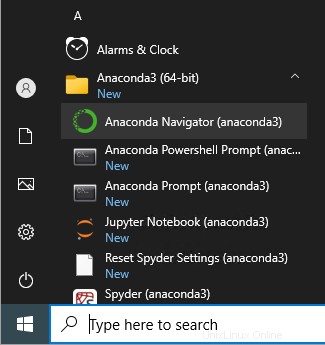
1. Anaconda Navigato を開きます
を。 Windows パソコンの場合:[開始] をクリックします。 —> アナコンダ3 —> アナコンダ ナビゲーター .
b. Linux コンピューターの場合:anaconda-navigator を実行します。 ターミナルでコマンドを実行してください。
2. Anaconda Navigator で、JupyterLab を探します。 アプリケーションを開き、[起動] をクリックします .これにより、Web ブラウザーで JupyterLab のインスタンスが開きます。

3. JypyterLab を起動したら、File Browser サイドバーを開き、ATA_Seaborn という名前の新しいフォルダーを作成します。 プロファイルまたはホーム ディレクトリの下。この新しいフォルダーがプロジェクト ディレクトリになります。
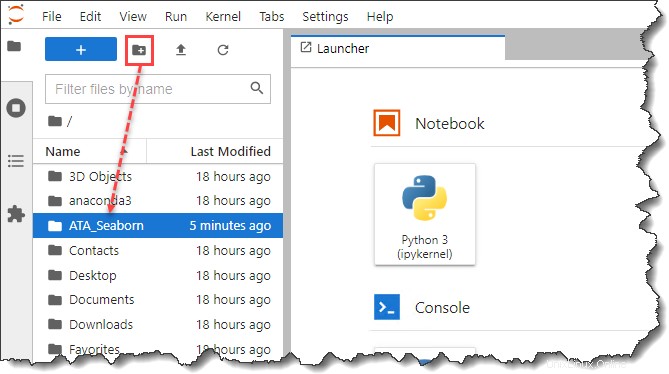
4. 次に、新しいブラウザ タブを開き、Pokemon をダウンロードします。 データセット。 ata_pokemon.csv を必ず保存してください この例では、ATA_Seaborn です。 .
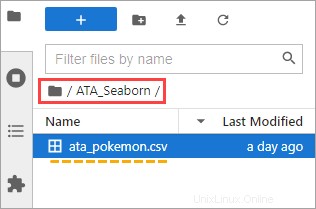
5. JupyterLab に戻り、ATA_Seaborn をダブルクリックします。 フォルダ。 ata_pokemon.csv が表示されます。 そのフォルダの下。
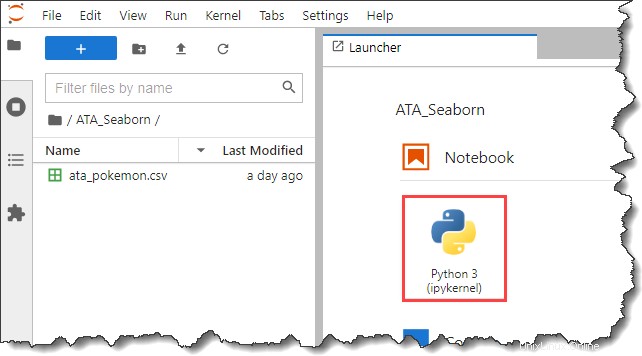
6. 次に、Python 3 をクリックします。 ノートブックの下のボタン ランチャーのセクション タブをクリックして、新しいノートブックを作成します。
7. 次に、新しいノートブック Untitled.ipynb をクリックします。 F2を押します ファイルの名前を変更します。ファイル名を ata_pokemon.ipynb に変更します .

8. 次に、ノートにタイトルを追加します。この手順はオプションですが、プロジェクトをより識別しやすくするために推奨されます。
ノートブックのツールバーで、[コード] というドロップダウン メニューをクリックします。 [マークダウン] をクリックします。
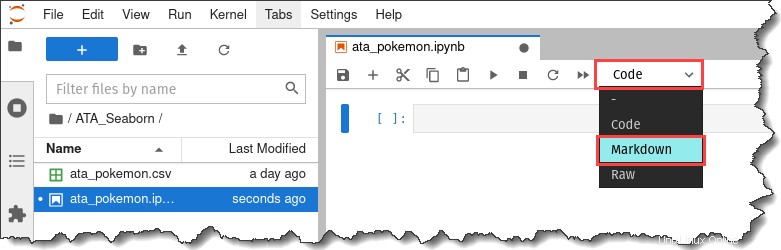
9. マークダウン セル内に「#ポケモン データ可視化」というテキストを入力し、Shift + Enter キーを押します。
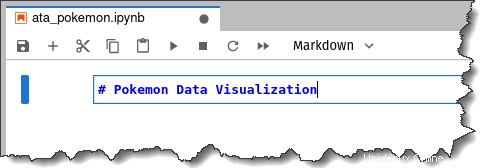
セル タイプの選択が自動的に コード に変わります。 ノートブックのタイトルは Pokemon Data Visualization になります 頂点で。
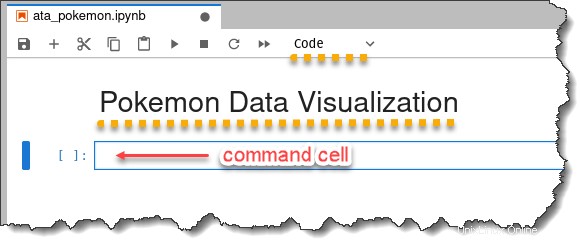
10. 最後に、Ctrl + S キーを押して作業を保存します。
作業内容を頻繁に保存してください。インターネット接続に問題が発生した場合に何かが失われないように、作業内容を頻繁に保存する必要があります。変更するたびに
CTRL+Sを押します 進行状況を保存します。ツールバーの [保存] ボタンをクリックすることもできます。
Pandas および Seaborn Python ライブラリのインポート
Python コードは通常、必要なライブラリをインポートすることから始まります。このプロジェクトでは、Pandas および Seaborn Python ライブラリを使用します。
Pandas と Seaborn をインポートするには、以下のコードをコピーして、ノートブックのコマンド セルに貼り付けます。
覚えておいてください — コマンド セルでコードまたはコマンドを実行するには、Shift + Enter キーを押します。
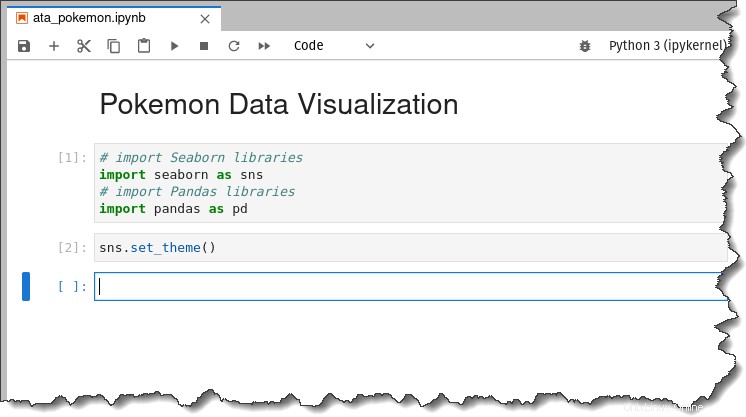
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pd次に、以下のコマンドを実行して、生成するプロットに Seaborn のデフォルト テーマの美学を適用します。
sns.set_theme()
Seaborn には 5 つの組み込みテーマが用意されています。 darkgrid です (デフォルト)、whitegrid 、dark 、white 、および ticks .
サンプル データセットのインポート
JupyterLab 環境をセットアップしたので、データセットから Jupyter 環境にデータをインポートしましょう。
1. pd.read_csv() を実行します コマンドをセルに入力して、データをインポートします。データセットのファイル名は、二重引用符で囲まれたインポートするファイルを示すために、括弧内にある必要があります。
以下のコマンドは ata_pokemon.csv をインポートします データセットを pokemon に保存します 変数。
pokemon = pd.read_csv("ata_pokemon.csv")
2. pokemon.head() を実行します コマンドを使用して、インポートされたデータセットの最初の 5 行をプレビューします。
pokemon.head()次の出力が得られます。
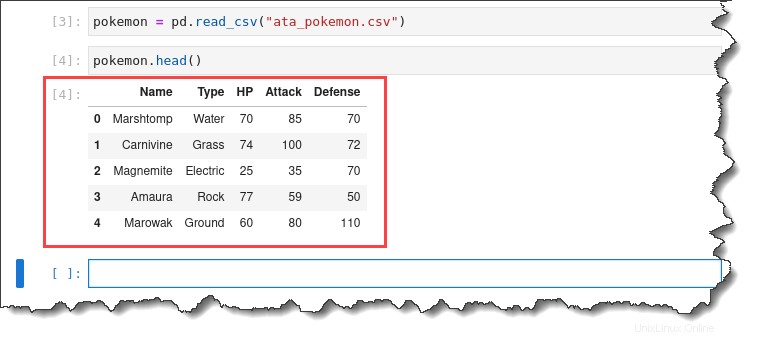
3. ata_pokemon.csv をダブルクリックします 左側のファイルを使用して、個々の行をすべて検査します。次の出力が得られます。
ご覧のとおり、このデータセットは、各観測値を行ごとにリストし、すべての数値情報が別々の列にあるため、操作が非常に便利です。
それでは、分析に役立つデータセットについていくつか質問してみましょう。
- 攻撃力とHPの関係は?
- 攻撃の分布は?
- 攻撃とタイプの関係は?
- 各タイプの攻撃の分布は?
- 各タイプの平均攻撃力は?
- 各タイプのポケモンの数は?
これらの質問の多くは、数値データとカテゴリ データの関係に焦点を当てていることに注意してください。カテゴリデータとは数値以外のデータを意味し、このサンプル データセットではポケモンの種類です。
厳密に数値データを含むプロットを作成するために最適化された Matplotlib とは異なり、Seaborn を使用して、カテゴリ データと数値データの両方を含むデータを分析できます。
関係プロットの作成
これで、データセットがインポートされました。次は何ですか?次に、インポートしたデータを使用して、それらから統計プロットを生成します。 HP 間の関係を発見するために、関係または関係プロットを作成することから始めましょう。 そして攻撃
関係プロットは、データセット内の変数間の可能な関係を特定する場合に実用的です。 Seaborn には、関係をグラフ化するための 2 つのプロットがあります:散布図と折れ線グラフです。
ライン プロット
ライン プロットを作成するには、Seaborn Python lineplot() を呼び出す必要があります。 関数。この関数は 3 つのパラメーター — data= を取ります。 、 x=' 、および y='
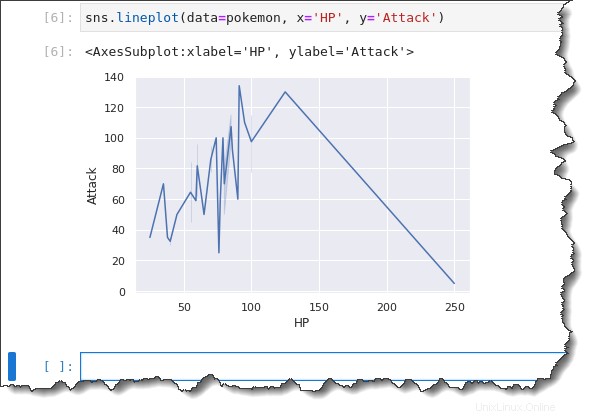
以下のコマンドをコピーして、Jupyter コマンド セルで実行します。このコマンドは pokemon を使用します 以前にインポートしたデータ ソース、HP としてのオブジェクト x 軸の列データ、および Attack y 軸のデータ。
sns.lineplot(data=pokemon, x='HP', y='Attack')以下に示すように、折れ線グラフは、迅速に分析できる情報を示すのに十分ではありません。折れ線グラフは、時間などの連続変数に従う x 軸を示すのに適しています。
この例では、離散変数 HP をプロットしています。それで何が起こるかというと、線のプロットがいたるところに行きます。そして、傾向を推測するのはより困難です。
散布図
探索的データ分析の一部は、さまざまなことを試して、何がうまく機能するかを確認することです。そうすることで、プロットによっては他のプロットよりも優れた洞察が得られることがわかります。
では、ライン プロットよりも優れた関係プロットとは何でしょうか? — 散布図。
散布図を作成するには、散布図関数 sns.scatterplot を呼び出します 、次の 3 つのパラメータを渡します:data=pokemon 、 x=HP 、および y=Attack .
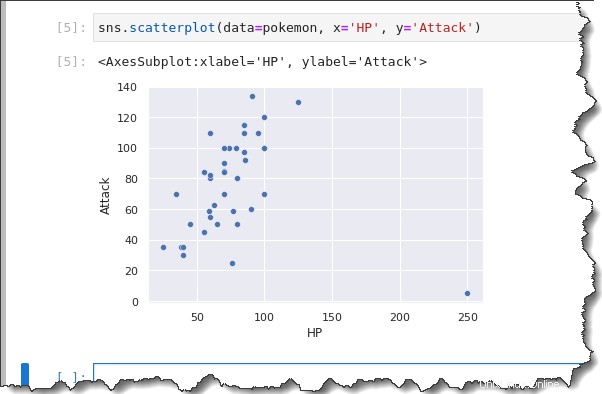
次のコマンドを実行して、ポケモン データセットの散布図を作成します。
sns.scatterplot(data=pokemon, x='HP', y='Attack')以下の結果からわかるように、散布図は HP の間に一般的な正の相関関係がある可能性があることを示しています。 (x 軸) と 攻撃 (y 軸)、外れ値が 1 つあります。
通常、HP が増加すると、攻撃も増加します。ヘルスポイントが大きいポケモンほど強い傾向があります。
凡例を使用した散布図
散布図はより適切なデータの視覚化を既に示していますが、凡例を使用してタイプ分布を分類することで、グラフをさらに改善できます。
sns.scatterplot() を実行します 次の例で再び機能します。ただし、今回は hue='Type' を追加します さまざまなポケモンの種類を示す凡例を作成します。 Jupyter ノートブック タブに戻り、以下のコマンドを実行します。
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')以下の結果を見ると、散布図の色が異なっていることに注意してください。凡例が提供する視覚的な違いにより、データのカテゴリ的側面の分析が大幅に改善されました。
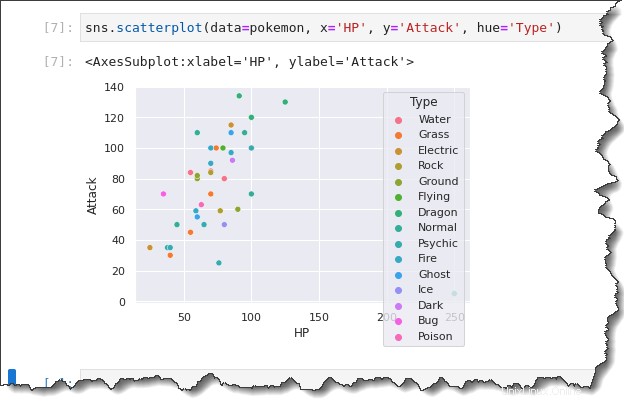
さらに優れているのは、 sns.relplot() を使用してプロットをさらに分解できることです。 col=Type の関数 と col_wrap キーワード引数。
以下のコマンドを Jupyter で実行して、各ポケモン タイプのプロットをマルチプロット グリッド形式で作成します。
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)以下の結果を見ると、HP と攻撃力は一般的に正の相関関係にあることが推測できます。 HPが多いポケモンほど強い傾向があります。
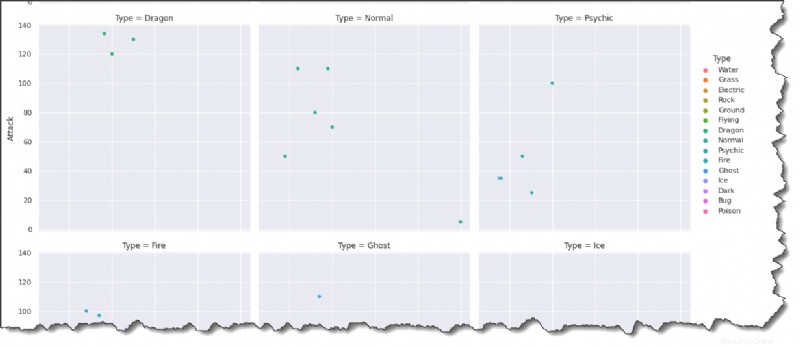
色と凡例を追加するとプロットがより面白くなることに同意しますか?
分布プロットの作成
前のセクションでは、散布図を作成しました。今回は、分布プロットを使用して、各ポケモン タイプの攻撃と HP の分布についての洞察を得ましょう。
ヒストグラム プロット
ヒストグラムを使用して、変数の分布を視覚化できます。サンプル データセットでは、変数はポケモンの攻撃です。
ヒストグラム プロットを作成するには、sns.histplot() を実行します。 以下の関数。この関数は 2 つのパラメーターを取ります:data=pokemon と x='Attack' .以下のコマンドをコピーして、Jupyter で実行してください。
sns.histplot(data=pokemon, x='Attack')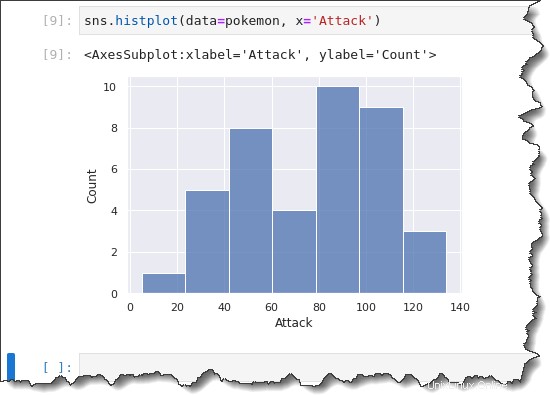
ヒストグラムを作成するとき、Seaborn は自動的に最適なビン サイズを選択します。ビンのサイズを変更して、さまざまな形のグループでデータの分布を観察することをお勧めします。
固定またはカスタムのビン サイズを指定するには、bins=x を追加します。 コマンドの引数 x カスタムビンサイズです。以下のコマンドを実行して、ビン サイズ 10 のヒストグラムを作成します。
sns.histplot(data=pokemon, x='Attack', bins=10)生成した前のヒストグラムでは、ポケモンの攻撃は二峰性分布 (2 つの大きなこぶ) を持っているように見えます。
しかし、ビン サイズ 10 を見ると、グループはより細分化されています。右方向に歪んだ単峰性分布が多いことがわかります。
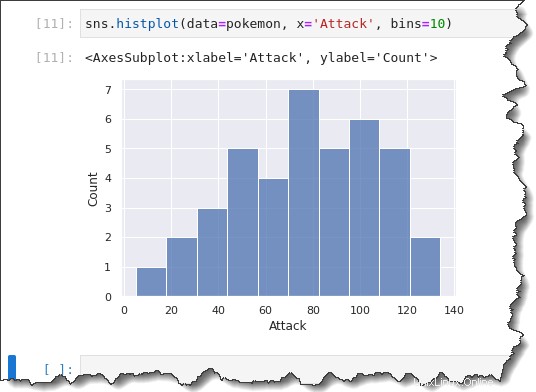
カーネル密度推定 (KDE) プロット
分布を視覚化する別の方法は、カーネル密度推定プロットを使用することです。 KDE は基本的にヒストグラムに似ていますが、列ではなく曲線を使用しています。
KDE プロットを使用する利点は、中心傾向、モダリティ、スキューなどの特徴を示す確率曲線により、データがどのように分布しているかをより迅速に推測できることです。
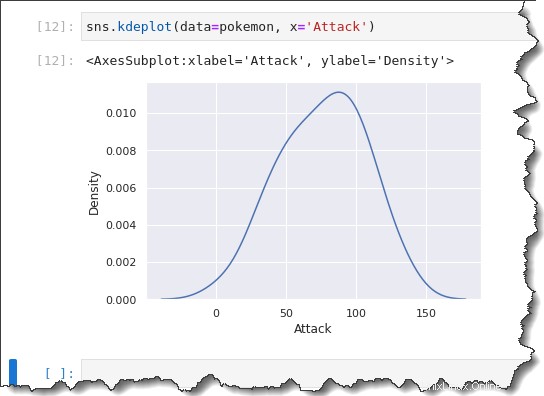
KDE プロットを作成するには、sns.kdeplot() を呼び出します。 関数と同じ data=pokemon を渡します 、 x='Attack' 引数として。以下のコードを Jupyter で実行して、KDE プロットの動作を確認してください。
sns.kdeplot(data=pokemon, x='Attack')以下に示すように、KDE プロットは、ビン サイズが 10 のヒストグラムと同様に歪んでいます。
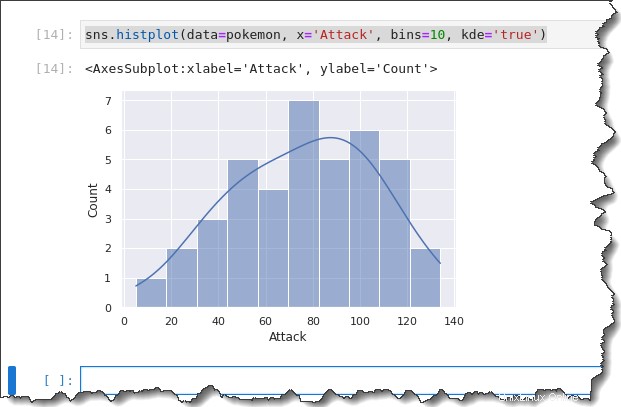
ヒストグラムと KDE は似ているので、一緒に使用してみませんか? Seaborn では、キーワード kde='true' を追加することで、KDE をヒストグラムに重ねることができます 以下に示すように、前のコマンドへの引数。
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')次の出力が得られます。以下のヒストグラムによると、ほとんどのポケモンの攻撃ポイントは 50 から 120 の範囲に分布しています。これは良い広がりではないでしょうか!
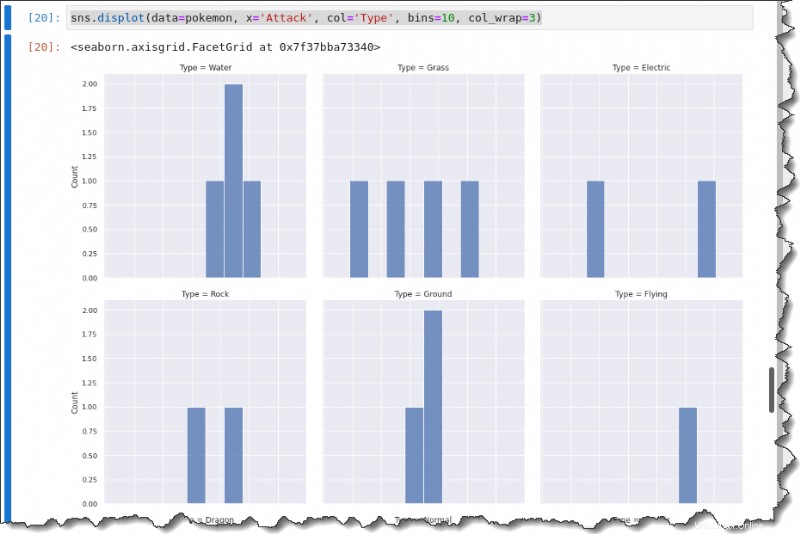
各攻撃の分布をタイプ別に分類するには、displot() を呼び出します col の関数 以下のキーワードを使用して、各タイプを示すマルチグリッド プロットを作成します。
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)次の出力が得られます。
カテゴリカル プロットの生成
タイプ カテゴリに基づいて個別のヒストグラムを作成すると便利です。ただし、ヒストグラムでは明確な画像が得られない場合があります。それでは、Seaborn のカテゴリカル プロットを使用して、ポケモンの種類に基づいて攻撃データをさらに分析してみましょう。
ストリップ プロット
前の散布図とヒストグラムでは、カテゴリ変数 (Type )。今回は、カテゴリ別にグループ化された一連の散布図であるストリップ プロットを作成します。
カテゴリ ストリップ プロットを作成するには、sns.stripplot() を呼び出します 関数を呼び出して、3 つの引数を渡します:data=pokemon 、 x='Type' 、および y='Attack' .以下のコードを Jupyter で実行して、カテゴリカル ストリップ プロットを生成します。
sns.stripplot(data=pokemon, x='Type', y='Attack')これで、すべての観測値がタイプ別にグループ化されたストリップ プロットができました。しかし、x 軸のラベルがすべて押しつぶされていることに注意してください。あまり役に立ちませんよね?
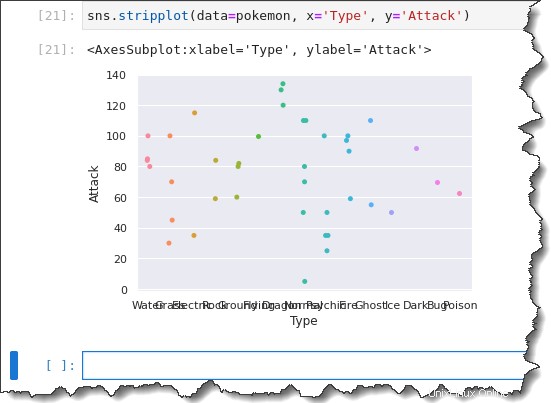
x 軸のラベルを修正するには、catplot() という別の関数を使用する必要があります .
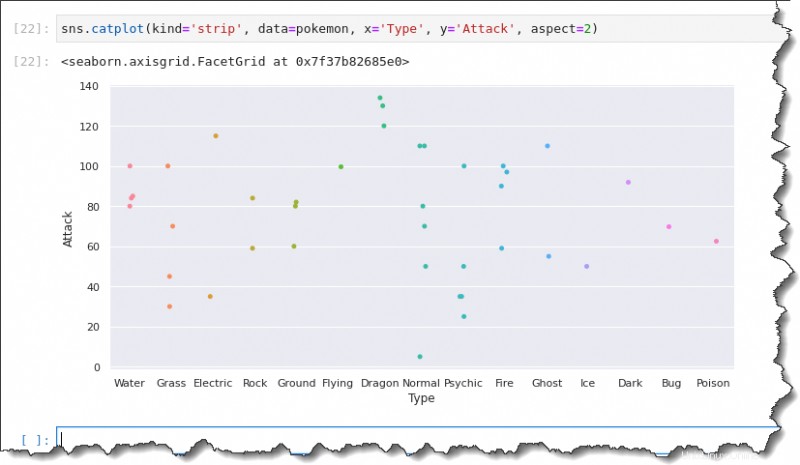
Jupyter ノートブック コマンド セルで、sns.catplot() を実行します。 関数を呼び出して、5 つの引数 kind='strip' を渡します 、 data=pokemon 、 x='Type' 、 y='Attack' 、およびaspect=2
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)今回は、結果のポットに x 軸ラベルが全幅で表示され、分析がより便利になります。
ボックス プロット
catplot() 関数には、カテゴリ変数を使用してデータ分布を視覚化するのに役立つプロットの別のサブファミリーがあります。それらの 1 つが箱ひげ図です。
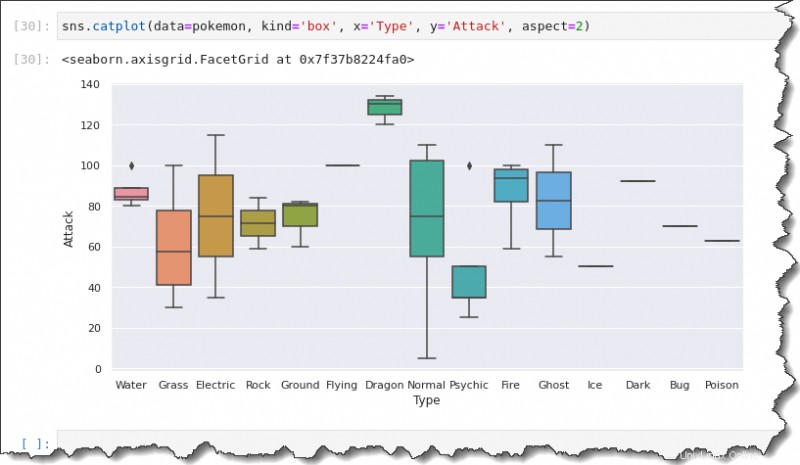
ボックス プロットを作成するには、sns.catplot() を実行します。 次の引数を持つ関数:data=pokemon 、 kind='box' 、 x='Type' 、 y='Attack' 、および aspect=2 .
aspect 引数は、x 軸ラベル間の間隔を制御します。値が大きいほどスプレッドが広くなります。
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
この出力は、データの広がりの概要を示します。 catplot() の使用 関数を使用すると、1 つのプロットで各ポケモン タイプのデータ スプレッドを取得できます。
黒いひし形のマーカーが外れ値を表していることに注意してください。ボックス プロットの代わりに、中央の線は、そのタイプのポケモンの観察結果が 1 つしかないことを意味します。
これらのボックス プロットとウィスカー プロットのそれぞれについて、5 つの数値の要約があります。ボックスの中央の線は、攻撃ポイントの中央値または中心傾向を表しています。
また、最大値と最小値を表す第 1 四分位数と第 3 四分位数、およびひげもあります。
バイオリンのプロット
分布を視覚化するもう 1 つの方法は、バイオリン プロットを使用することです。ヴァイオリン プロットは、ボックス プロットと KDE の組み合わせのようなものです。ヴァイオリン プロットはボックス プロットに似ています。
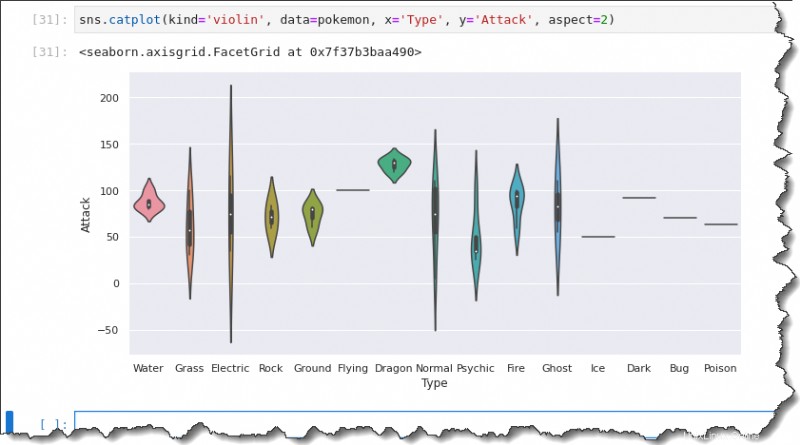
ヴァイオリン プロットを作成するには、kind を置き換えます。 値を violin に 、残りはボックス プロット コマンドを実行したときと同じです。以下のコードを実行してバイオリン プロットを作成します。
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)その結果、ヴァイオリン プロットには中央値、第 1 および第 3 四分位数が含まれていることがわかります。バイオリン プロットは、ボックス プロットに広がるデータの同様の要約を提供します。
質問の再検討:ポケモンの種類ごとの攻撃分布とは?
箱ひげ図は、最小攻撃ポイントが 0 から 10 の間にあり、最大は 110 になることを示しています。
ノーマルタイプのポケモンの攻撃ポイントの中央値は約 75 のようです。第 1 および第 3 四分位数は約 55 と 105 のようです。
バー プロット
棒グラフは、各データ カテゴリの平均値または平均値を示す Seaborn のカテゴリ推定ファミリのメンバーです。
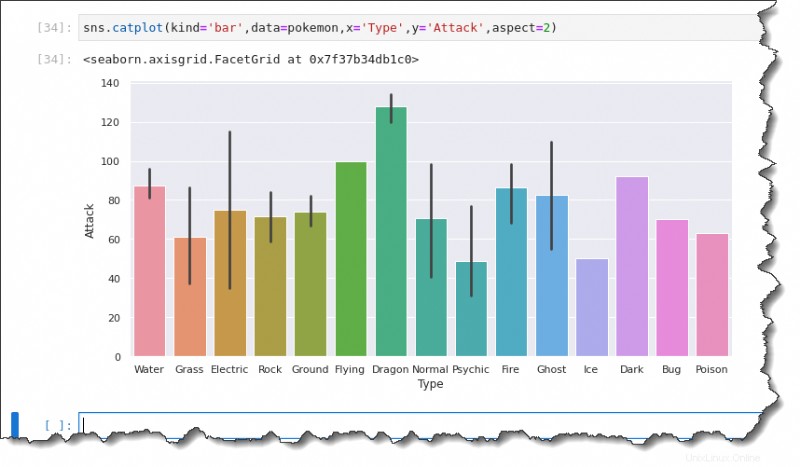
棒グラフを作成するには、sns.catplot() を実行します Jupyter で関数を作成し、次の 6 つの引数を指定します:kind='bar' 、data=pokemon 、 x='Type' 、y='Attack' 、および aspect=2
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)各バーの黒い線は、観測値の外れ値などの不確実性を表すエラー バーです。以下に示すように、平均値は次のとおりです。
- みずタイプのポケモンで約90。
- 草の場合は約 60 .
- 電気 約 75 です。
- ロック おそらく70。
- グラウンド 75 以内
- など
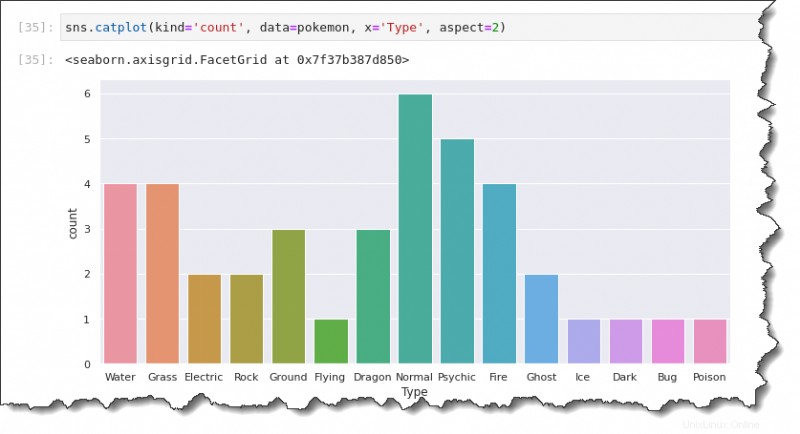
カウント プロット
平均/平均データの代わりにポケモンの数をプロットしたい場合はどうしますか?カウント プロットを使用すると、Seaborn Python ライブラリでそれを行うことができます。
カウント プロットを生成するには、kind を置き換えます。 count の値 、以下のコードに示すように。バー プロットとは異なり、カウント プロットには 1 つのデータ軸しか必要ありません。作成するプロットの向きに応じて、x 軸または y 軸のみを指定します。
以下のコマンドは、x 軸に型変数を示すカウント プロットを作成します。
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)以下のようなカウント プロットが表示されます。ご覧のとおり、最も一般的なタイプのポケモンは次のとおりです。
- 通常 (6)。
- サイキック (5)。
- 水 (4).
- 草 (4)。
- など
結論
このチュートリアルでは、Seaborn Python ライブラリを使用してプログラムで統計プロットを作成する方法を学習しました。あなたのデータセットにはどのプロット方法が最も適していると思いますか?
例を見て、Seaborn でプロットを作成する練習をしたので、自分で新しいプロットを作成してみませんか。おそらく、アイリス データセットから始めるか、サンプル データを収集することができますか?
また、Seaborn に組み込まれている他のテンプレートやカラー パレットも試してみてください。読んでくれてありがとう。楽しんでね!