Linuxのtrコマンドは、ある文字セットを別の文字セットに変換します。文字または文字のセットを別の文字または文字のセットに置き換えることができます。 trは標準入力から入力を読み取り、出力を標準出力に表示します。入力は、ファイルで、またはechoコマンドを使用して行うこともできます。
tr translateの略です 。
trコマンドの標準形式は次のとおりです:
$ tr [option] [char_set 1] [char_set 2]
指定されたオプションに基づいて、trコマンドは「set1」の文字セットを「set2」に置き換えます。
文字の置き換え
trコマンドを使用して文字を置き換えるには、1番目のセットで置き換える文字と、2番目のセットで置き換えた後にその場所に配置する文字を指定するだけです。
$ tr 'a' '1'
このコマンドは、STDINからの入力を待ちます。入力を取得すると、画面に出力が表示され、「a」のすべてのインスタンスが「1」に置き換えられます。

1。 trコマンドでechoを使用する
上記の例は、STDINからの入力を読み取ります。 Echoコマンドは、trコマンドとともに入力を提供できます。パイプ(|)演算子を使用して、コマンドを一緒に実行します。
$ echo "apples and bananas" | tr 'a' '1'

2。ファイルから入力を取得する
trは、ファイルから入力を取得することもできます。これは、大量のテキストのコレクションに対して翻訳を行う場合に役立ちます。リダイレクト(<)演算子は、ファイルからの入力を提供するために使用されます。
$ tr 'a' '1' < input.txt

input.txtには、上記の例と同じテキストが含まれています。
テキストをファイルに保存するには、redirection(>)演算子を使用して、出力をファイルにリダイレクトします。
$ tr 'a' '1' < input.txt > output.txt
trコマンドでテキストの大文字と小文字を変更する
trコマンドの最も一般的な使用法の1つは、テキストを小文字から大文字に、またはその逆に翻訳することです。
trは文字のセットで機能するため、小文字のセットをセット1として明示的に言及し、大文字のセットをセット2として明示的に言及して切り替えを行うことができます。
$ echo "apples and bananas" | tr a-z A-Z
a-zを設定します 小文字のセットとA-Zのセットを表します 大文字のセットを表します。
同じことを行う別の方法は:
$ echo "apples and bananas" | tr [:lower:] [:upper:]
ここでは、 [:lower:] 小文字のアルファベットと[:upper:]のセットを表します 大文字のアルファベットのセットを表します。

trを使用した文字の削除
trには、テキストから文字のセットを削除する機能があります。これは、 -dとともにtrを使用することで実現されます。 コマンド。
$ echo "apples and bananas" | tr -d 'n'
このコマンドは、「n」のすべての出現を排除します 本文中。

複数の文字の出現を削除するには、すべての文字を一重引用符で囲んでください。
$ echo "apples and bananas" | tr -d 'na'
このコマンドは、‘n’の出現を削除します および「a」

trは文字レベルで機能するため、「n」のすべての個別の出現 および「a」 削除されます。誤解されやすく、このコマンドは「na」の出現のみを削除すると考えられます その順序で発生します。ただし、そうではありません。
複数のオカレンスを1つに絞ります
複数のオカレンスを1つにまとめると、テキストを圧縮するのに役立ちます。これは、行間の複数のスペースのインスタンスを削除するためによく使用されます。
-s オプションは、trとともに使用して絞ります。
$ echo "apples and bananas" | tr -s 'p'

アップルでの「p」の複数回の出現は、1回の出現に減少しました。
$ echo "apples and bananas" | tr -s 'na' '1'
このコマンドの出力は、最初に出現した文字‘n’を置き換える出力と同等です。 および‘a ‘with ‘1’ 、続いてスクイーズ操作。比較するには、出力の2番目のコマンドを見てください。 2番目のコマンドの結果は、単純な文字置換です。
2番目のコマンドの出力にあるすべての1を絞り込んで、最初のコマンドと同じ出力が得られるかどうかを確認しましょう。

出力の最初のコマンドと同じ出力が得られます。
テキスト内の連続する空白を削除するには、次を使用します:
$ echo "apples and bananas" | tr -s " "

または、 [:space:] 」「の代わりに使用できます
$ echo "apples and bananas" | tr -s [:space:]
テキストから数字を抽出する
特定の文字セットのみを保持する必要がある操作を実現するため。 -cを使用することをお勧めします オプション。 -c セットを補完するために使用されます。
セットの補集合とは、そのセットに含まれるもの以外のすべてを意味します。
$ echo " Home : 011 1234 4321" | tr -cd [:digit:],'\n'

‘\ n’(改行)に言及 そうしないと、出力に改行がなく、ターミナルの次の行と混同されるため、重要です。文字の削除中に改行を無視しないもう1つの理由は、ファイルの複数行に複数の数字が含まれる可能性があるためです。改行文字を削除すると、すべての数字がスペースなしで一緒に表示されます。

テキストから単語を抽出する
このプロセスは、上記で実行したプロセスとは正反対です。ここでは、数字を無視し、文字で構成される単語のみに焦点を当てます。
$ echo " Home : 011 1234 4321" | tr -d [:digit:]

この例では、テキストからすべての数字を削除しただけです。
同じことを行うためのより制御された方法は、補完によるものです。
$ echo " Home : 011 1234 4321" | tr -cd [:alpha:],'\n'

[:alpha:] アルファベットのセットを表します。下部と上部の2つのセットのコレクションと考えてください。
[:alpha:] = [:lower:] + [:upper:]
単語の出現回数を数える
単語がテキストに出現する回数を数えることは、ヒストグラムを作成するのに役立ちます。また、電子メールスパム検出の確率モデルを構築するのにも非常に役立ちます。
まず、繰り返し単語を含むファイルを作成しましょう。

テキストの各単語を新しい行に表示すると便利な場合があります。
$ tr -cs "[:alpha:]" "\n" < input.txt
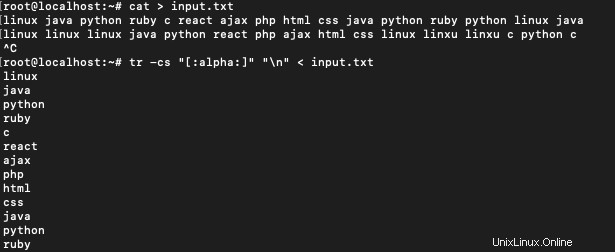
各単語の出現回数を取得するには、次を使用します。
$ tr -cs "[:alpha:]" "\n" < input.txt | sort | uniq -c
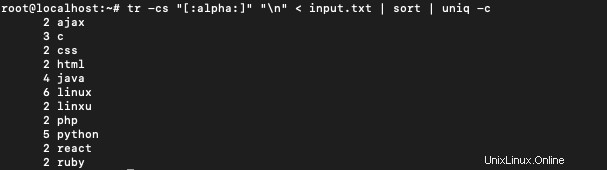
並べ替え リストを辞書式にソートするために使用されます。 uniq -c 各単語の個々の出現をカウントし、その結果をカウント付きの単語のリストとして出力します。
結論
trコマンドは、文字ベースの翻訳を実行するのに役立ちます。 sortやuniqなどの他のコマンドと組み合わせると、trコマンドは非常に強力であることがわかります。 trコマンドの詳細については、マニュアルページを参照してください。行全体に変換を適用する場合は、sedコマンドを使用できます。