Grepまたはグローバル正規表現印刷 Linuxシステムでテキストまたはパターンを検索するために使用されます。ファイル、ディレクトリ、さらには他のコマンドの出力を検索できます。
正規表現は、ユーザーのニーズに応じてテキストに一致するパターンです。これらはパターンマッチングのルールのようなものです。
Grepは、テキスト内のパターンを検索するために正規表現とともに使用されることがよくあります。 grepを使用した正規表現の実際的な例をいくつか見てみましょう。
1。大文字と小文字を区別せずに単語を一致させる
テキストの中には、同じ単語をさまざまな方法で書くことがあります。これは、適切な名詞の場合に最も一般的に当てはまります。大文字で始める代わりに、すべて小文字で書かれることもあります。
$ grep "[Jj]ayant"

大文字と小文字に関係なく、両方のバージョンの単語が一致しています。
もう1つの興味深い事例は、「IoT」という言葉で観察できます。このような単語は、さまざまなバリエーションでテキスト全体に数回出現する可能性があります。大文字と小文字を区別せずにすべての単語に一致させるには:
$ grep "[iI][oO][tT]"

2。正規表現とgrepを使用した携帯電話番号の照合
正規表現を使用して、テキストから携帯電話番号を抽出できます。
携帯電話番号の形式は事前に知っておく必要があります。たとえば、携帯電話番号に一致するように設計された正規表現は、自宅の電話番号では機能しません。
この例では、次の形式の携帯電話番号が照合されます:91-1234567890(つまり、TwoDigit-TenDigit)。
$ grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}"

明らかなように、上記の形式の携帯電話番号のみが一致します。
3。メールアドレスを一致させる
テキストからメールアドレスを抽出することは非常に便利であり、grepを使用して実現できます。
メールアドレスには特定の形式があります。 「@」の前の部分は、メールボックスを識別するユーザー名です。次に、gmail.comやyahoo.inのようなドメインがあります。
正規表現は、これらのことを念頭に置いて設計できます。
$ grep -E "[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}"


- [A-Za-z0-9 ._%+-]+は「@」の前のユーザー名をキャプチャします
- [A-Za-z0-9 .-] +は、「。com」部分なしでドメインの名前をキャプチャします
- 。[A-Za-z]{2,6}は、「。com」や「.in」などをキャプチャします。
4。 URLチェッカー
URLには特定の表現形式があります。 URLが適切な形式であるかどうかを検証する正規表現を作成できます。
URLは、http / https / ftpで始まり、その後に「://」が続く必要があります。次に、「。com」、「。in」、「。org」などで終わることができるドメイン名があります。
$ grep -E "^(http|https|ftp):[\/]{2}([a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,4})"


この例と前の例で使用されている-Eは、基本正規表現セットの代わりに拡張正規表現セットを使用する拡張grepを意味します。これは、特定の特殊文字をエスケープする必要がないことを意味します。これにより、複雑な正規表現を作成するプロセスの煩わしさが軽減されます。詳しくはこちらをご覧ください。
5。特定の拡張子を持つファイルを検索する
lsコマンドは、現在のディレクトリ内のすべてのファイルを表示します。
ls -lを実行すると、ファイルに関する追加情報が得られます。 Grepをls-lコマンドと一緒に使用して、出力のパターンを一致させることができます。
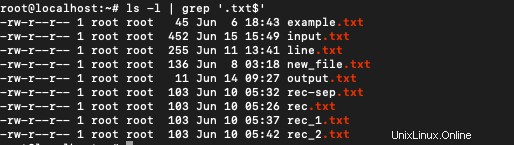
拡張子「.txt」で保存されているファイルを取得するには、次を使用します。
$ ls -l | grep '.txt$'
6。括弧内のコンテンツを検索する
多くの場合、テキストファイルの内容は括弧内にあります。 grepで正規表現を使用してこれらを抽出できます。
$ grep "([A-Za-z ]*)"

正規表現は、パラセシス内のテキストを選択します。括弧内のコンテンツの長さも指定できます。
たとえば、括弧を10文字のみと一致させるには、:
を使用します。
$ grep "([A-Za-z ]{10})"
7。特定の単語で始まる行を一致させる
正規表現を使用して、特定の単語で始まる行を見つけることができます。

Applesという単語で始まる行を見つけるには:
grep '^Apples' input.txt
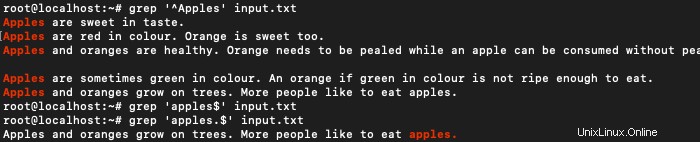
同様に、他の単語で始まる行も見つかります。
以下の正規表現を使用して、特定の単語で終わる行を照合できます。
$ grep 'apples.$' input.txt

8。一度に複数の単語を一致させる
以下に示すように、複数の単語を正規表現と一致させましょう:
$ grep 'Apples\|Orange' input.txt
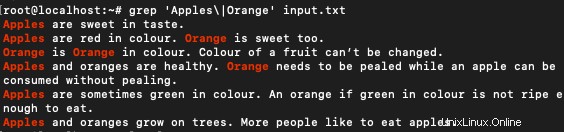
このコマンドは、2つの単語の間のOR行で機能します。 2つの単語のいずれかを含む行に一致します。
2つの単語の間でANDを実行するには、次を使用します。
$ grep 'Apple' input.txt | grep 'Orange

9。同じ単語を異なる形式で一致させる
単語がさまざまな形で出現することがあります。使用されている時制によって異なる場合があります。
ピーリングとピーリングはその一例です。どちらの単語でも、ルートワードは「ピール」です
正規表現を使用して、すべての形式の単語に一致させることができます。
私たちのテキストでは、ピーリングとピーリングをそれぞれピールとピーリングと綴っています。
同様の方法で、米国英語から英国英語に翻訳することもできます。たとえば、colorという単語はcolorになります。
$ grep 'peal\([a-z]*\)\(\.*[[:space:]]\)' input.txt

10。 / etc/passwdファイルでユーザーを保護する
grepを使用して、/ etc /passwd/ファイルからユーザーを取得できます。 / etc / passwdファイルは、システム上のユーザーのリストといくつかの追加情報を保持します。
$ grep "Adam" /etc/passwd

このコマンドは、システムファイルでgrepを使用します。 「アダム」という単語が見つかると、その行が出力として表示されます。ファイル内の他の要素に対しても同じ検索を実行できます。
結論
正規表現とgrepコマンドは非常に強力です。正規表現は、コンピュータサイエンスの別の分野として研究されており、非常に複雑なパターンを照合するために使用できます。正規表現の詳細については、こちらをご覧ください。