LinuxおよびUnixシステムでは、「グローバル正規表現print」の略であるGrepは、正規表現に含まれるテキストファイルの検索と照合に使用されるコマンドです。さらに、このコマンドはすべてのLinuxディストリビューションにプリインストールされています。このガイドでは、いくつかの例を使用して、一般的なgrepコマンドの使用法を見ていきます。
LinuxのGrepコマンド
Grepコマンドを使用して、テキストファイル内の正規表現または文字列を検索または検索できます。これを示すために、テキストファイル welcome.txtを作成しましょう。 図のようにコンテンツを追加します。
Welcome to Linux !
Linux is a free and opensource Operating system that is mostly used by
developers and in production servers for hosting crucial components such as web
and database servers. Linux has also made a name for itself in PCs.
Beginners looking to experiment with Linux can get started with friendlier linux
distributions such as Ubuntu, Mint, Fedora and Elementary OS.
すごい!これで、いくつかのgrepコマンドを実行し、出力を操作して目的の結果を得る準備ができました。
ファイル内の文字列を検索するには、以下のコマンドを実行します
構文
$ grep "string" file nameまたは
$ filename grep "string"例 :
$ grep "Linux" welcome.txt出力

ご覧のとおり、grepは文字列「Linux」を検索して照合しただけでなく、文字列が表示されている行も出力しました。
ファイルが別のファイルパスにある場合は、必ず以下のようにファイルパスを指定してください
$ grep "string" /path/to/file–colorオプションを使用したGrep結果の色付け
検索文字列またはパターンを他のテキストとは異なる色で表示しないシステムで作業している場合は、-colorを使用してください。 結果を目立たせるために。
例
$ grep --color "free and opensource" welcome.txt 出力

すべてのディレクトリで文字列を再帰的に検索する
現在のディレクトリおよび他のすべてのサブディレクトリで文字列を検索する場合は、-rを使用して検索します。 示されているフラグ
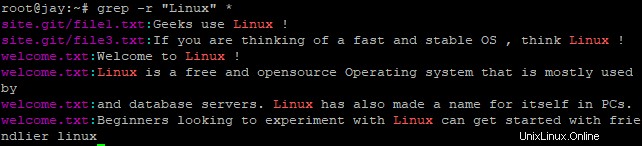
$ grep -r "string-name" *例
$ grep -r "linux" *出力
大文字と小文字の区別を無視する
上記の例では、文字列「Linux」が大文字で指定されており、大文字のファイルにも存在するため、検索結果から必要なものが得られました。それでは、小文字の文字列を検索してみましょう。
$ grep "linux" file name
出力から何もありませんよね?これは、最初の文字が小文字であるため、greppingが文字列「linux」を見つけて一致させることができなかったためです。大文字と小文字の区別を無視するには、 -iを使用します フラグを立てて、以下のコマンドを実行します
$ grep -i "linux" welcome.txt出力

すごいですね。 -私 通常、大文字と小文字の区別に関係なく、文字列を表示するために使用されます。
文字列が-cオプションで一致する行を数えます
文字列パターンが表示または存在する行の総数をカウントするには、以下のコマンドを実行します
$ grep -c "Linux" welcome.txt出力

Grepを使用して出力を反転する
Grep出力を反転するには、 -vを使用します 国旗。 -v オプションは、式を含まない、または式に一致しないすべての行を出力するようにgrepに指示します。
–vオプションは、出力を反転するようにgrepに指示します。つまり、一致する行を印刷する代わりに、反対のことを行い、式に一致しないすべての行を印刷します。ファイルに戻って、図のように行番号を表示しましょう。
VimエディターでESCを押し、コロン全体を入力してから
set nu次に、Enterキーを押します
出力

ここで、文字列「Linux」を含まない行を表示するには、run
$ grep -v "Linux" welcome.txt出力
ご覧のとおり、grepは検索パターンを含まない行を表示しています。
-nオプションを使用して検索パターンを含む行に番号を付けます
文字列パターンが一致する行に番号を付けるには、 -nを使用します 示されているオプション
$ grep -n "Linux" welcome.txt出力

-wオプションを使用して完全に一致する単語を検索します
次に-wを渡します フラグは、示されているように完全に一致する単語を含む行を検索します
$ grep -w "opensource" welcome.txt出力

ただし、試してみると
$ grep -w "open" welcome.txtパターンではなく正確な単語を検索しているため、結果は返されません!
grepでのパイプの使用
grepコマンドをパイプと一緒に使用して、明確な出力を取得できます。
たとえば、特定のパッケージがUbuntuシステムにインストールされているかどうかを知りたい場合は、
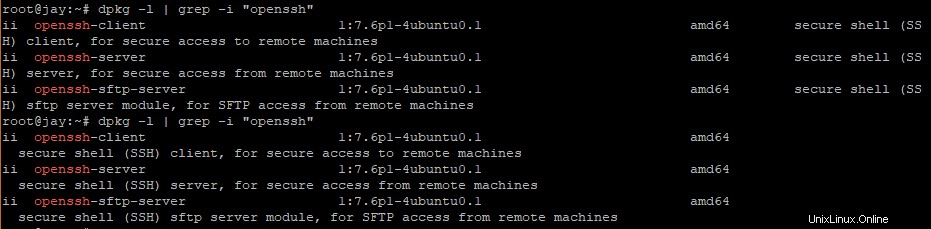
を実行します。$ dpkg -L | grep "package-name"
たとえば、OpenSSHがシステムにインストールされているかどうかを確認するには、 dpkg -lをパイプします。 示されているようにgrepするコマンド
$ dpkg -L | grep -i "openssh"出力
パイプを使用した検索パターンの前後の行数の表示
-Aを使用できます または-B 検索文字列の前後の行数を表示します。 -A フラグは、検索文字列と -Bの後に続く行を示します 検索文字列の前に表示される出力を出力します。
例
$ ifconfig | grep -A 4 ens3
このコマンドは、 ensの後に文字列と4行のテキストを含む行を表示します。 ifconfigの文字列 コマンド。
出力

逆に、以下の例では、-Bフラグを使用すると、検索文字列を含む行と、 etherの前に3行のテキストが表示されます。 ifconfigの文字列 コマンド。
出力
$ ifconfig | grep -B 4 ether

正規表現でのgrepの使用(REGEX)
REGEXという用語は、 REGの頭字語です。 ular EX 圧力。正規表現は、パターンを照合するために使用される文字のシーケンスです。以下にいくつかの例を示します。
^ Matches characters at the beginning of a line
$ Matches characters at the end of a line
"." Matches any character
[a-z] Matches any characters between A and Z
[^ ..] Matches anything apart from what is contained in the brackets
例
特定の文字で始まる行を印刷する場合、構文は次のとおりです。
grep ^character file_nameたとえば、welcome.txtファイルで文字「d」で始まる行を表示するには、
を実行します。$ grep ^d welcome.txt 出力

文字「x」で終わる行を表示するにはrun
$ grep x$ welcome.txt出力

より多くのGrepオプションについてサポートを受ける
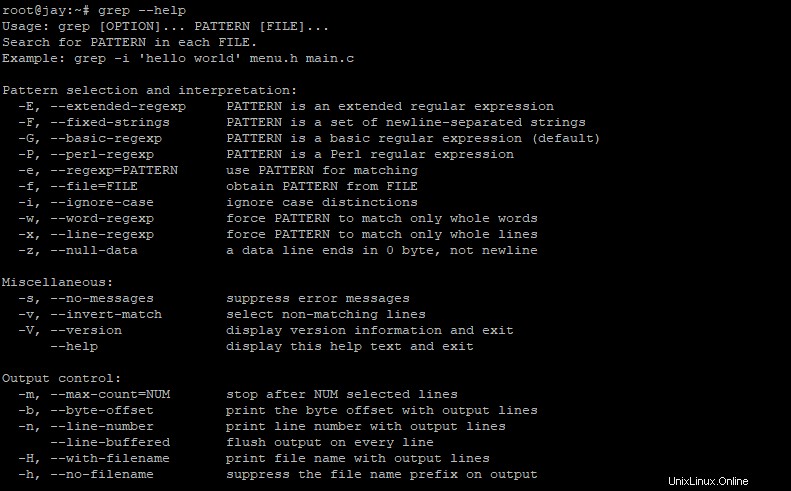
Grepコマンドの使用法について詳しく知る必要がある場合は、以下のコマンドを実行して、コマンドと一緒に使用できる他のフラグまたはオプションのプレビューを取得してください。
$ grep --helpサンプル出力
このチュートリアルをお読みいただき、ありがとうございます。コマンドを試してみて、どのように進んだかをお知らせください。