はじめに
このガイドでは、Linux/Unixシステムで最も役立つgrepコマンドについて詳しく説明します。
すべてのコマンドと例を実行した後、grepを使用してターミナルからテキストのファイルを検索する方法を学習します。

前提条件
- LinuxまたはUNIXライクなシステム
- 端末/コマンドラインへのアクセス
- 目的のファイルとディレクトリにアクセスする権限を持つユーザー
grepコマンドとは何ですか?
Grep Gの頭字語です。 ローブR egular E xpression P リント。
Grepは、指定されたファイル内の文字列を検索するために使用されるLinux/Unixコマンドラインツールです。テキスト検索パターンは正規表現と呼ばれます。一致するものが見つかると、その行に結果が出力されます。 grepコマンドは、大きなログファイルを検索するときに便利です。
grepコマンドの使用
grepコマンドは、最も基本的な形式の3つの部分で構成されています。最初の部分はgrepで始まります 、続いて検索しているパターン。文字列の後に、grepが検索するファイル名が続きます。
最も単純なgrepコマンドの構文は次のようになります。
コマンドには、多くのオプション、パターンバリエーション、およびファイル名を含めることができます。必要な数のオプションを組み合わせて、必要な結果を取得します。以下は、最も一般的なgrepコマンドと例です。 。
ファイルを検索するには
特定の文字パターンを含むファイルから任意の行を印刷するには、この場合は phoenix ファイル内sample2 、コマンドを実行します:
grep phoenix sample2
Grepは、 phoenixという単語に一致するすべての行を表示します。 。このコマンドを実行すると、完全に一致するものは得られません。代わりに、端末は入力した文字列を含む単語を含む行を印刷します。次に例を示します:

複数のファイルを検索するには
grepコマンドを使用して複数のファイルを検索するには、検索するファイル名をスペース文字で区切って挿入します。
この場合、 phoenixという単語に一致するgrepコマンド 3つのファイルでsample 、 sample2 、および sample3 この例のようになります:
grep phoenix sample sample2 sample3ターミナルは、一致する行を含むすべてのファイルの名前と、必要な文字列を含む実際の行を出力します。
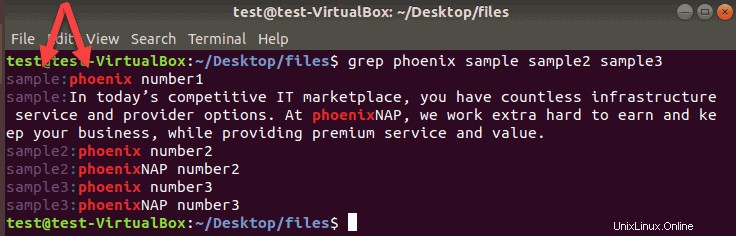
必要な数のファイル名を追加できます。ターミナルは、リストされたファイルで見つかったすべての一致に対して、ファイル名を含む新しい行を出力します。
ディレクトリ内のすべてのファイルを検索
現在のディレクトリ内のすべてのファイルを検索するには、grepコマンドの最後にファイル名の代わりにアスタリスクを使用します。
この例では、 nixを使用します 検索基準として:
grep nix *出力には、 nixを含むファイルの名前が表示されます 行全体を返します。
単語全体のみを検索するには
Grepを使用すると、単語全体の結果のみを検索して印刷できます。 フェニックスという単語を検索するには 現在のディレクトリ内のすべてのファイルに、 -wを追加します grepコマンドに。
grep -w phoenix *このオプションは、単語全体が一致する行と、それらが見つかったファイルの名前のみを出力します。

-wの場合 省略した場合、grepは別の単語の部分文字列であっても検索パターンを表示します。
複数の文字列と単語パターンを検索したい場合は、複数の文字列、パターン、または単語をgrepする方法に関する記事を確認してください。
Grep検索で大文字と小文字を区別しない
grepコマンドでは大文字と小文字が区別されるため、grep検索で最も役立つ演算子の1つは-iです。 小文字の結果のみを印刷する代わりに、端末は大文字と小文字の両方の結果を表示します。出力には、大文字と小文字が混在するエントリを含む行が含まれます。
このコマンドの例:
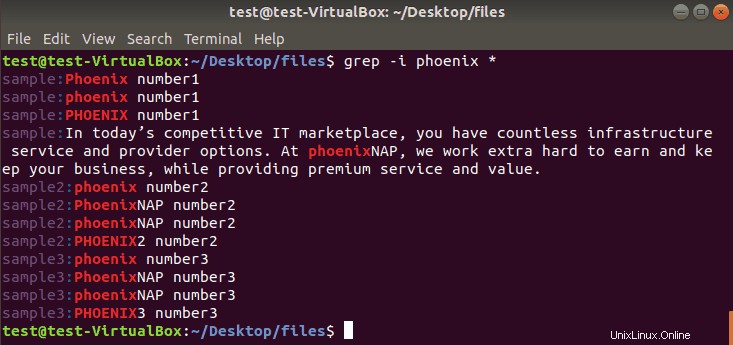
grep -i phoenix *
-i operatorを使用する場合 現在のディレクトリ内のファイルでphoenixを検索します 、出力は次のようになります:
サブディレクトリを検索するには
検索にすべてのサブディレクトリを含めるには、 -rを追加します grepコマンドの演算子。
grep -r phoenix *
このコマンドは、現在のディレクトリ、サブディレクトリ、およびファイル名との正確なパスにあるすべてのファイルの一致を出力します。以下の例では、 -wも追加しました 単語全体を表示する演算子ですが、出力形式は同じです。
逆grep検索
grepを使用して、しないすべての行を印刷できます。 文字の特定のパターンに一致します。検索を逆にするには、 -vを追加します grepコマンドに。
phoenixを含むすべての行を除外するには 、次のように入力します:
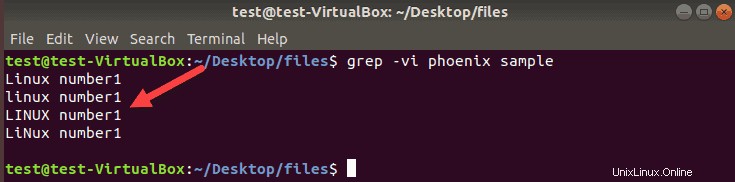
grep -v phoenix sample
端末は、検索条件として使用される単語を含まないすべての行を印刷します。 -iを使用する 大文字と小文字を区別せずに、この検索に使用される単語を完全に除外するには:
検索文字列と完全に一致する行を表示するには
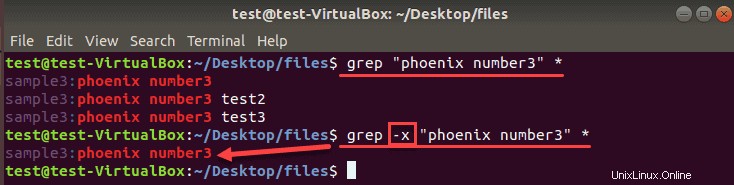
grepコマンドは、ファイル内で一致するものが見つかると、行全体を出力します。検索文字列に完全に一致する行のみを印刷するには、 -xを追加します オプション。
grep -x “phoenix number3” *出力には、完全に一致する行のみが表示されます。同じ行に他の単語や文字がある場合、grepはそれを検索結果に含めません。検索パターンにスペースや記号がある場合は、必ず引用符を使用してください。
-xを使用した場合と使用しない場合の結果の比較を次に示します。 grepコマンドの演算子:
一致するファイルの名前を一覧表示するには
場合によっては、単語または文字列を含み、実際の行を除外するファイルの名前だけを確認する必要があります。検索に一致するファイル名のみを印刷するには、 -lを使用します 演算子:
grep -l phoenix *
出力には、 phoenixを含む正確なファイル名が表示されます 現在のディレクトリにありますが、対応する単語の行は出力されません:
注意として、再帰検索演算子 -rを使用してください 検索にすべてのサブディレクトリを含める。
一致数をカウントするには
Grepは、ファイル名と、単語に一致するものが見つかった行数を表示できます。
-cを使用します 一致数をカウントする演算子:
grep -c phoenix *
検索文字列の前後の行数を表示するには
最も関連性の高いものを決定するために、検索結果にさらに多くのコンテンツが必要になる場合があります。
次の演算子を使用して、一致の前、後、またはその両方で目的の行を追加します。
- -Aを使用する 一致後に表示する行数:
grep -A 3 phoenix sample-このコマンドは、一致後に3行を出力します。 - -Bを使用します 一致する前に表示する行数:
grep -B 2 phoenix sample-このコマンドは、一致する前に2行を出力します。 - -Cを使用します およびの前に表示する行数 試合後:
grep -C 2 phoenix sample-このコマンドは、一致の前後に2行を出力します。
grepが一致する行番号を表示するには
grepが多くの一致を含む結果を出力する場合、行番号を確認すると便利です。 -nを追加します 行番号を表示するには、任意のgrepコマンドの演算子を使用します。
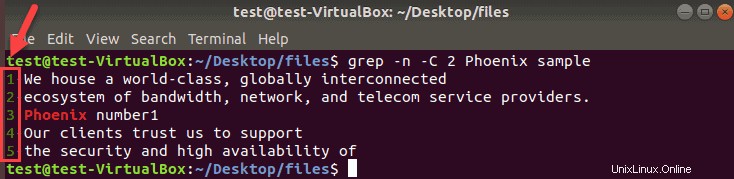
フェニックスを検索します 現在のディレクトリで、一致の前後の2行とその行番号を表示します。
grep -n -C 2 Phoenix samplegrep出力を固定行数に制限する
ログファイルなどの個々のファイルには、grep検索パターンに一致するものが多数含まれている可能性があります。 -m を追加して、grep出力の行数を制限します オプションとコマンドの番号。
grep -m2 Phoenix sample
この場合、端末はsampleで見つかった最初の2つの一致を出力します ファイル。
ファイルを指定せずにディレクトリ内のすべてのファイルを検索すると、出力にはすべての最初の2つの結果が出力されます。 一致するファイルを含むファイル。