Linux sedエディターとシェルスクリプトでawkコマンドを正常に使用するには、正規表現または短い正規表現を理解する必要があります。正規表現には多くのエンジンがあるため、シェル正規表現を使用して、正規表現を操作する際のbashパワーを確認します。
まず、正規表現とは何かを理解する必要があります。次に、その使用方法を確認します。
正規表現とは
一部の人々にとって、彼らが初めて正規表現を見るとき、彼らはこれらのASCIIプークが何であるかを言いました!!
一般に、正規表現または正規表現は、sedやawkなどのLinuxプログラムがテキストのフィルタリングに使用することを定義するテキストのパターンです。
基本的なLinuxコマンドを紹介するときにこれらのパターンのいくつかを確認し、lsコマンドがワイルドカード文字を使用して出力をフィルタリングする方法を確認しました。
正規表現の種類
Linuxでは、プログラミング言語(Java、Perl、Python)に含まれる正規表現や(sed、awk、grep)などのLinuxプログラムや他の多くのアプリケーションなど、さまざまなアプリケーションがさまざまな種類の正規表現を使用します。
正規表現パターンは、それらのパターンを変換する正規表現エンジンを使用します。
Linuxには2つの正規表現エンジンがあります:
- 基本正規表現(BRE) エンジン。
- 拡張正規表現(ERE) エンジン。
ほとんどのLinuxプログラムはBREエンジン仕様でうまく機能しますが、sedなどの一部のツールはBREエンジンルールの一部を理解しています。
POSIX EREエンジンには、いくつかのプログラミング言語が付属しています。数字や単語のマッチングなど、より多くのパターンを提供します。 awkコマンドは、EREエンジンを使用して正規表現パターンを処理します。
多くの正規表現の実装があるため、すべてのエンジンで機能するパターンを作成することは困難です。したがって、最も一般的に見られる正規表現に焦点を当て、sedとawkでの使用方法を示します。
BREパターンの定義
次のように、テキストに一致するパターンを定義できます。
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

正規表現は、パターンが発生する場所やデータストリーム内の回数を気にしないことに気付くかもしれません。
知っておくべき最初のルールは、正規表現のパターンでは大文字と小文字が区別されるということです。
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

最初の正規表現は大文字で「オタク」という単語が存在するため成功しますが、2行目は小文字を使用しているため失敗します。
次のように、パターンでスペースまたは数字を使用できます。
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

特殊文字
正規表現パターンはいくつかの特殊文字を使用します。また、パターンに含めることはできません。含めると、期待どおりの結果が得られません。
これらの特殊文字は正規表現によって認識されます:
.*[]^${}\+?|() バックスラッシュ文字(\)を使用して、これらの特殊文字をエスケープする必要があります。
たとえば、ドル記号($)と一致させる場合は、次のように円記号でエスケープします。
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
バックスラッシュ(\)自体を一致させる必要がある場合は、次のようにエスケープする必要があります:
$ echo "\ is a special character" | awk '/\\/{print $0}'

スラッシュは特殊文字ではありませんが、直接使用するとエラーが発生します。
$ echo "3 / 2" | awk '///{print $0}'

したがって、次のようにエスケープする必要があります:
$ echo "3 / 2" | awk '/\//{print $0}'

アンカーキャラクター
テキストの行頭を見つけるには、キャレット文字(^)を使用します。
次のように使用できます:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

キャレット文字(^)は、テキストの先頭と一致します:
$ awk '/^this/{print $0}' myfile

テキストの途中で使用するとどうなりますか?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

通常の文字のように印刷されます。
awkを使用する場合は、次のようにエスケープする必要があります:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

これは、テキストの最初を見るということですが、最後を見るのはどうですか?
ドル記号($)は、行の終わりをチェックします:
$ echo "Testing regex again" | awk '/again$/{print $0}'

次のように、同じ行でキャレットとドル記号の両方を使用できます。
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
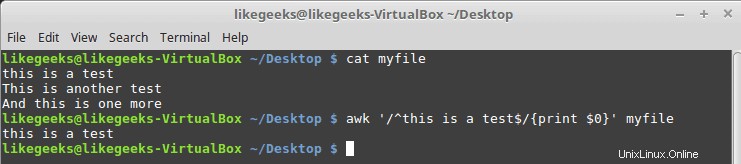
ご覧のとおり、パターンが一致する行のみが印刷されます。
次のパターンで空白行をフィルタリングできます:
$ awk '!/^$/{print $0}' myfile ここでは、感嘆符でできる否定を紹介します!
このパターンは、行の最初と最後の間に何もない空の行を検索し、行だけにテキストがあることを否定します。
ドット文字
ドット文字を使用して、改行(\ n)以外のすべての文字と一致させます。
次の例を見て、アイデアを得てください。
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
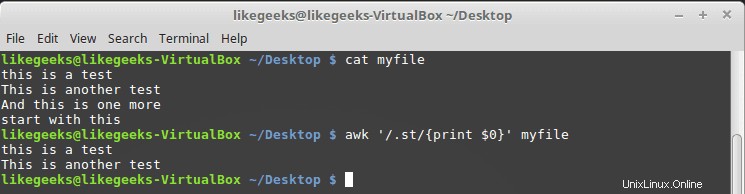
結果から、最初の2行だけがstパターンを含んでいるのに対し、3行目にはそのパターンがなく、4行目はstで始まっているため、これもパターンと一致しないことがわかります。
キャラクタークラス
任意の文字をドット特殊文字と一致させることができますが、文字のセットのみを一致させる場合は、文字クラスを使用できます。
文字クラスは、文字のセットが見つかった場合に一致し、パターンは一致します。
次のように角かっこ[]を使用して文字クラスを定義できます:
$ awk '/[oi]th/{print $0}' myfile
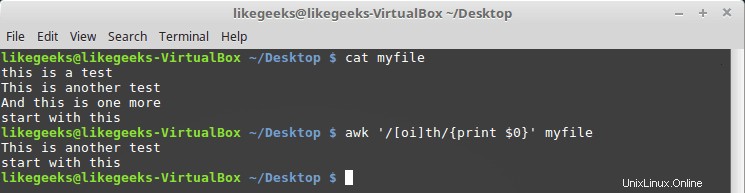
ここでは、o文字またはその前にiがある文字を検索します。
これは、大文字または小文字を含む可能性のある単語を検索するときに便利ですが、それについてはよくわかりません。
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "testing regex" | awk '/[Tt]esting regex/{print $0}'

もちろん、それは文字に限定されません。数字や好きなものを使うことができます。アイデアが浮かんだら、好きなように使うことができます。
文字クラスの否定
キャラクタークラスにないキャラクターを検索するのはどうですか?
これを実現するには、文字クラス範囲の前に次のようなキャレットを付けます。
$ awk '/[^oi]th/{print $0}' myfile
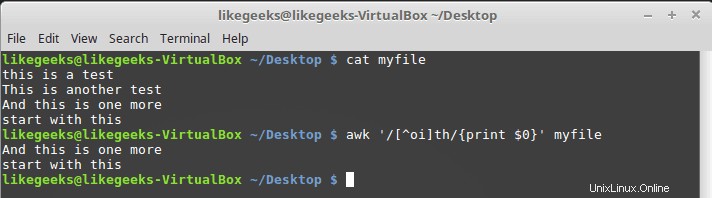
したがって、oとiを除いて何でも受け入れられます。
範囲の使用
文字の範囲を指定するには、次のように(-)記号を使用できます。
$ awk '/[e-p]st/{print $0}' myfile
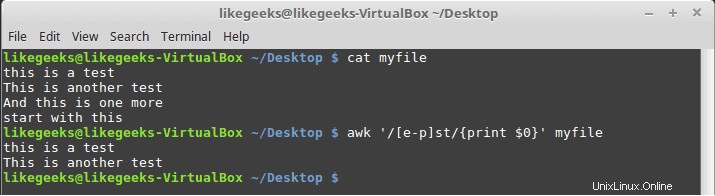
これは、eとpの間のすべての文字に一致し、その後に示されているようにstが続きます。
数値に範囲を使用することもできます:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

次のように、複数の個別の範囲を使用できます。
$ awk '/[a-fm-z]st/{print $0}' myfile
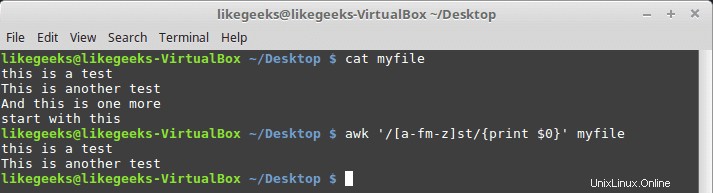
ここでのパターンはaからfを意味し、mからzはstテキストの前に表示される必要があります。
特殊文字クラス
次のリストには、それらを使用できる特殊文字クラスが含まれています。
| [[:alnum:]] | 0–9、A–Z、またはa–zのパターン。 |
| [[:blank:]] | スペースまたはタブのみのパターン。 |
| [[:digit:]] | 0から9のパターン。 |
| [[:lower:]] | a–z小文字のみのパターン。 |
| [[:print:]] | 印刷可能な文字のパターン。 |
| [[:punct:]] | 句読文字のパターン。 |
| [[:space:]] | 任意の空白文字のパターン:スペース、タブ、NL、FF、VT、CR。 |
| [[:upper:]] | A〜Z大文字のみのパターン。 |
次のように使用できます:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

アスタリスク
アスタリスクは、文字が0回以上存在する必要があることを意味します。
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

このパターン記号は、スペルミスや言語のバリエーションをチェックするのに役立ちます。
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green color" | awk '/colou*r/{print $0}'

これらの例では、色を入力するか、一致する色を入力するかに関係なく、アスタリスクは「u」文字が何度も存在するか、一致する時間がゼロであるかを意味するためです。
任意の数の任意の文字に一致させるには、ドットを使用できます アスタリスク このように:
$ awk '/this.*test/{print $0}' myfile
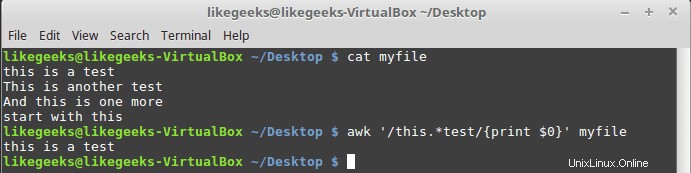
「this」と「test」の間の単語の数は関係ありません。どの行も一致します。
文字クラスでアスタリスク文字を使用できます。
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
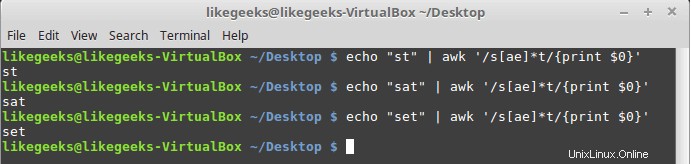
アスタリスクは、「a」文字または「e」文字が0回以上見つかった場合にそれを印刷することを意味するため、3つの例すべてが一致します。
拡張正規表現
以下は、PosixEREに属するパターンの一部です。
疑問符
疑問符は、前の文字が1回だけ存在することも、存在しないこともあることを意味します。
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}'
疑問符は文字クラスと組み合わせて使用できます:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
文字クラス項目のいずれかが存在する場合、パターンマッチングは合格です。そうしないと、パターンが失敗します。
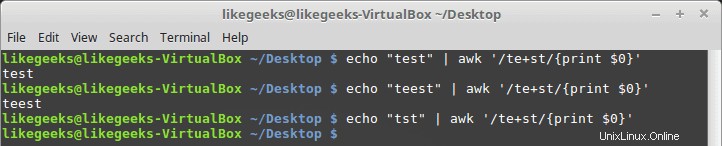
プラス記号
プラス記号は、プラス記号の前の文字が1回以上存在する必要があるが、少なくとも1回は存在する必要があることを意味します。
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
「e」文字が見つからない場合は失敗します。
次のような文字クラスで使用できます:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
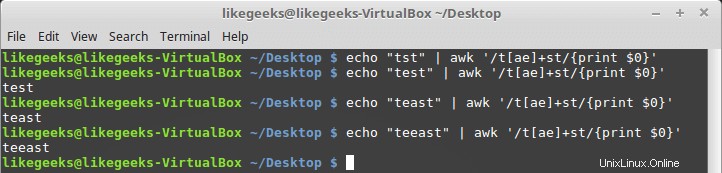
文字クラスの文字が存在する場合、それは成功します。
中括弧
中括弧を使用すると、パターンの存在数を指定できます。2つの形式があります。
n:正規表現は正確にn回表示されます。
n、m:正規表現は少なくともn回出現しますが、m回以下です。
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

古いバージョンのawkでは、awkコマンドに–re-intervalオプションを使用して中括弧を読み取る必要がありますが、新しいバージョンでは必要ありません。
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

この例では、「e」文字が1回または2回存在する場合、成功します。それ以外の場合は失敗します。
次のような文字クラスで使用できます:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
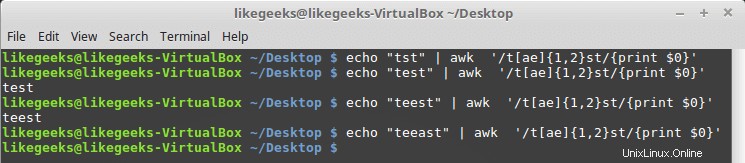
文字「a」または「e」のインスタンスが1つまたは2つある場合、パターンは合格です。それ以外の場合は失敗します。
パイプ記号
パイプシンボルは、2つのパターン間の論理ORを作成します。パターンの1つが存在する場合、それは成功します。それ以外の場合は失敗します。例を次に示します。
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
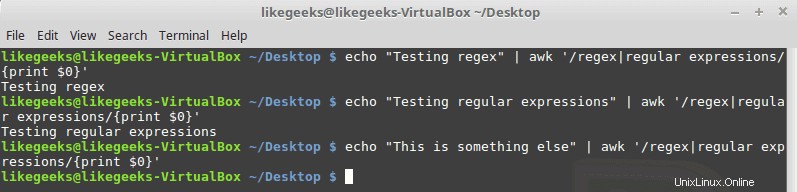
パターンとパイプ記号の間にスペースを入力しないでください。
グループ化式
式をグループ化して、正規表現エンジンがそれらを1つのピースと見なすようにすることができます。
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
「Geeks」をグループ化すると、正規表現エンジンはそれを1つのピースとして扱うため、「LikeGeeks」または「Like」という単語が存在する場合は成功します。
実例
正規表現パターンを使用する簡単なデモンストレーションを見ました。練習のためだけに、それを実行に移す時が来ました。
ディレクトリファイルのカウント
PATH環境変数からフォルダー内の実行可能ファイルをカウントするbashスクリプトを見てみましょう。
$ echo $PATH
ディレクトリリストを取得するには、各コロンをスペースに置き換える必要があります。
$ echo $PATH | sed 's/:/ /g'
次に、次のようにforループを使用して各ディレクトリを繰り返し処理します。
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
素晴らしい!!
lsコマンドを使用して各ディレクトリのファイルを取得し、変数に保存できます。
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
一部のディレクトリが存在しないことに気付くかもしれませんが、これは問題ありません。OKayです。
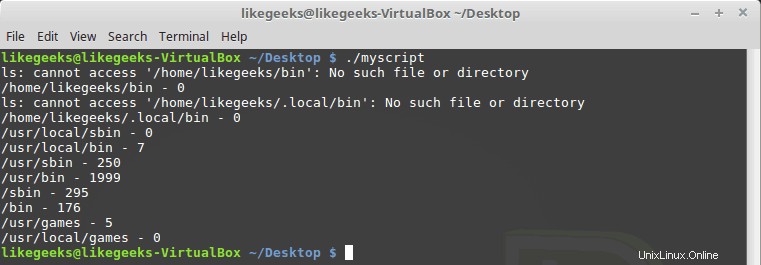
涼しい!!これが正規表現の力です。これらの数行のコードは、すべてのディレクトリ内のすべてのファイルをカウントします。もちろん、これを非常に簡単に実行するLinuxコマンドがありますが、ここでは、使用できるものに正規表現を使用する方法について説明します。もっと便利なアイデアを思いつくことができます。
電子メールアドレスの検証
電子メールや電話番号など、あらゆるものに正規表現パターンをすぐに使用できるWebサイトがたくさんあります。これは便利ですが、どのように機能するかを理解したいと思います。
example@unixlinux.online
ユーザー名には、ドット、ダッシュ、プラス記号、アンダースコアを組み合わせた任意の英数字を使用できます。
ホスト名には、ドットとアンダースコアを組み合わせた任意の英数字を使用できます。
ユーザー名については、次のパターンがすべてのユーザー名に適合します。
^([a-zA-Z0-9_\-\.\+]+)@
プラス記号は、1文字以上存在し、その後に@記号が続く必要があることを意味します。
その場合、ホスト名パターンは次のようになります。
([a-zA-Z0-9_\-\.]+)
TLDまたはトップレベルドメインには特別なルールがあり、最大2文字から5文字以上である必要があります。以下は、トップレベルドメインの正規表現パターンです。
\.([a-zA-Z]{2,5})$ 今、それらをすべてまとめました:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ メールに対してその正規表現をテストしてみましょう:
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

素晴らしい!!
これは、終わりのない正規表現の世界の始まりにすぎませんでした。これらのASCIIピュークを理解し、より専門的に使用してください。
投稿が気に入っていただければ幸いです。
ありがとうございます。