Linuxオペレーティングシステムは、そのコンピューティング能力と能力を自慢するのが好きです。特にファイル管理下でのファイル処理などに対するそのアルゴリズム的アプローチは、Linux管理フットプリントを習得するためのLinuxユーザーにとって重要なマイルストーンをもたらします。
Linuxオペレーティングシステム環境でのファイル処理で考慮しなければならない側面の1つは、編集可能なLinuxでサポートされているファイル内の最長の行を特定することです。
ファイル内の長い行の実際的な意味
会社で働いているシナリオや、巨大なログファイルを処理するプロジェクトを扱っているシナリオを考えてみてください。これらのファイルは、実際には何千ものJSONドキュメントをカプセル化できる場合でも、単一のテキスト行としてレンダリングされる可能性があります。
これらのテキスト行のサイズが非常に/異常に長い場合、Elastic Searchサーバーなどの宛先サーバーにファイルを正しくリダイレクトするために、プロキシサーバーを介してそれらを処理する必要がある場合があります。
ただし、実際にはファイル内の非常に長い行を処理しているだけの場合、ファイル処理に対するこのような注意深い手順により、意図しないファイル処理エラーが発生する可能性があります。そのようなエラーを診断することは、プレイ中の脅威を知らなければ不可能です。
このチュートリアルでは、Linuxオペレーティングシステム環境でターゲットファイル内の最長行を特定するために必要な手順を実行します。
問題の説明
この記事をより楽しく魅力的なものにするために、いくつかのさまざまな行を含む参照テキストファイルを作成し、後で有効なLinuxソリューションを実装して最長の行を見つけます。
$ sudo nano sample_file.txt
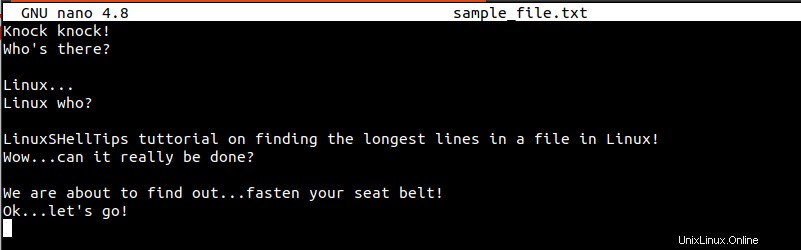
上記のファイル( sample_file.txt )の最長行を特定するよう努めます。 )便利なLinuxコマンドを使用します。
1。 Awkコマンドを使用してファイル内の最長行を検索する
理想的には、ワンライナー awk を使用して、上記のファイルのすべての行を先頭に追加できます。 以下に示すように、正確な長さを決定するコマンド。
$ awk '{printf "%2d| %s\n",length,$0}' sample_file.txt
上記のスクリーンキャプチャのとおり、 73 は最大の行の長さです。
wcおよびgrepコマンドを使用してファイルに最長行を印刷する
これらの2つのコマンドを組み合わせることにより、grepコマンドからの正規表現とwcコマンドからのmax-line-lengthを使用できるようになります。 wc コマンドは-Lを取ります 以下に示すように、最大行長を決定するコマンドオプション。
$ grep -E "^.{$(tr '\t' ' ' 上記のコマンドは、ファイル sample_file.txtに最長の行を出力する必要があります 。

73の最大行長を持つ2つの同一の行があったため 、上記のコマンドは2つを出力しました 行。最大行長が73の1行だけの場合、その行だけが印刷されます。
これで、Linuxでファイル内の最長の行を快適に見つけることができます。