質問 :Linux システムに多数の行を含むファイルがあります。ファイル内の合計行数をカウントするにはどうすればよいですか?
「wc -l」の使用
ファイル内の行数を数える方法はいくつかあります。しかし、最も簡単で広く使われている方法の 1 つは、「wc -l」を使用することです。 wc ユーティリティは、各入力ファイル、または標準入力 (ファイルが指定されていない場合) に含まれる行数、単語数、およびバイト数を標準出力に表示します。
構文は次のとおりです:
# wc -l [filename]
以下に示すファイルを考えてみましょう:
$ cat file01.txt this is a sample file with some sample data
1. このファイルに対して「wc -l」コマンドを実行すると、ファイル名とともに行数が出力されます。
$ wc -l file01.txt
5 file01.txt 2. 結果からファイル名を省略するには、次を使用します:
$ wc -l < file01.txt
5 3. パイプを使用して wc コマンドにコマンド出力をいつでも提供できます。例:
$ cat file01.txt | wc -l
5 ここでは、cat の代わりに任意のコマンドを使用できます。任意のコマンドからの出力を wc コマンドにパイプして、出力の行数をカウントできます。
awk の使用
awk を使用して行数を確認する必要がある場合は、次の awk コマンドを使用してください:
$ awk 'END{print NR}' [filename] 出力例:
$ awk 'END{print NR}' file01.txt
5 sed の使用
以下の sed コマンド構文を使用して、GNU sed を使用して行数を見つけます:
$ sed -n '$=' [filename]
出力例:
$ sed -n '$=' file01.txt 5
grep の使用
私たちの古き良き友人「grep」も、ファイル内の行数をカウントするために使用できます。これらの例は、「wc -l」を使用せずに行を数える方法が複数あることを知らせるためのものです。しかし、尋ねられたら、覚えるのが簡単すぎるので、これらのオプションの代わりに常に「wc -l」を使用します.
$ grep -c ".*" [filename]
出力例:
$ grep -c ".*" file01.txt 5
GNU grep では、以下の grep 構文を使用できます:
$ grep -Hc ".*" [filename]
行数を確認する別のバージョンの grep コマンドを次に示します。
$ grep -c ^ file01.txt 5
出力例:
$ grep -Hc ".*" file01.txt file01.txt:5
その他のコマンド
上記のコマンドに加えて、ファイル内の行数を見つけるためにめったに使用されないコマンドを知っておくとよいでしょう。
1. nl コマンド (行番号フィルター) を使用して、各行に番号を付けます。コマンドの構文は次のとおりです:
$ nl [filename]
出力例:
$ nl file01.txt
1 this is a sample
2 file
3 with
4 some sample
5 data 行数を取得する直接的な方法ではありません。ただし、 awk または sed を使用して、最後の行からカウントを取得できます。例:
$ nl file01.txt | tail -1 | awk '{print $1}'
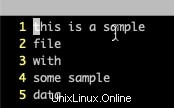
5 2. 以下に示すように、vi と vim をコマンド ":set number" で使用して、各行に番号を設定することもできます。ファイルが非常に大きい場合は、「Shift+G」を使用して最後の行に移動し、行数を取得できます。
3. -n を指定して cat コマンドを使用する 各行に番号を付けるように切り替えます。ここでも、最後の行から行数を取得できます。
$ cat -n file01.txt
1 this is a sample
2 file
3 with
4 some sample
5 data $ cat -n file01.txt | tail -1 | awk '{print $1}'
5 4. perl one lines を使用して行数を確認することもできます:
$ perl -lne 'END { print $. }' file01.txt
5