カンマ区切りの値 別名CSV 単語を区切る区切り文字としてコンマを使用する半構造化データです。 CSVファイル形式は、多くのCSVファイルを処理し、それを処理して洞察を作成する必要があるため、データの専門家の間で非常に人気があります。この記事では、LinuxのBashシェルスクリプトでCSVファイルを解析する方法に焦点を当てます。
この記事のほとんどの部分で、 awkを使用します およびsed grep 、cut 、tr 、など。
awk ユーティリティは、複数のコマンドをパイプしたり、データを取得するロジックを使用してループを作成したりする複雑さを軽減します。代わりに、awkでワンライナーコードを書くことができます 仕事をするために。
1。処理用のCSVファイルの準備
CSVファイルは、データベースまたはAPIから生成されているか、いくつかのコマンドを実行して出力をCSV形式の区切り文字に変換している可能性があります。いずれの場合も、ロジックを実行する前に、まずデータセットを分析する必要があります。
ベストプラクティスとして、データセットを使用する前にデータセットをクレンジングする必要があります。なぜデータセットをクレンジングする必要があるのですか?空のセル値があるか、ヘッダーに適切なフォーマットがない、処理に必要のない余分な列などがある場合があります。
Kaggleから取得した以下のCSVデータを使用しています デモンストレーション用。
Player_Id,Player_Name,DOB,Batting_Hand,Bowling_Skill,Country 1,SC Ganguly,8-Jul-72,Left_Hand,Right-arm medium, 2,BB McCullum,27-Sep-81,Right_Hand,Right-arm medium, 3,RT Ponting,19-Dec-74,Right_Hand,Right-arm medium, 4,DJ Hussey,15-Jul-77,Right_Hand,Right-arm offbreak,Australia 5,Mohammad Hafeez,17-Oct-80,,Right-arm offbreak,Pakistan 6,R Dravid,11-Jan-73,,Right-arm offbreak,India 7,W Jaffer,16-Feb-78,,Right-arm offbreak,India 8,V Kohli,5-Nov-88,,Right-arm medium,India 9,JH Kallis,16-Oct-75,,Right-arm fast-medium,South Africa 10,CL White,18-Aug-83,Right_Hand,Legbreak googly,Australia 11,MV Boucher,3-Dec-76,Right_Hand,Right-arm medium,South Africa 12,B Akhil,7-Oct-77,Right_Hand,Right-arm medium-fast,India 13,AA Noffke,30-Apr-77,Right_Hand,Right-arm fast-medium,Australia 14,P Kumar,2-Oct-86,Right_Hand,Right-arm medium,India 15,Z Khan,7-Oct-78,Right_Hand,Left-arm fast-medium,India
1.1。空のセルを交換する
場合によっては、CSVファイルの特定のセルに値が含まれていません。下のスクリーンショットを見てください。列の間に空のセルがいくつかあります。
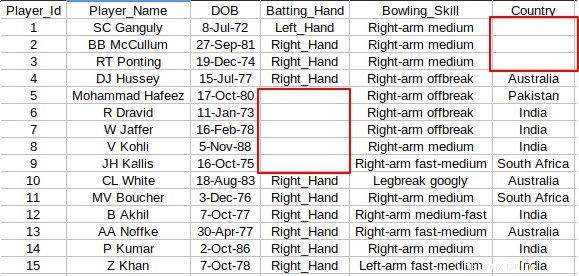
常に「NA」または「NoValue」に置き換えるので、空のセルはありません。次のawkを使用できます 空のセルを目的の値に置き換えるスニペット。この場合、空のセルを「値なし」に置き換えています。
awk 'BEGIN{FS=",";OFS=","}
{
for(i=1;i<=NF;i++)
{
if($i == ""){
$i="No Value"
}
}
print
}' ~/Downloads/Player.csv > player_cleaned.csv
このスニペットが機能する方法は、フィールド区切り文字と出力フィールド区切り文字をコンマ(FS=",";OFS=",")に設定することです。 )。 for loopを使用する 、行の各セルを反復処理し、セルが空であることが判明した場合($i == "" )次に、"No value"に置き換えます ($i="No value" )。変更を新しいファイルにリダイレクトする必要があります。
おすすめの記事:
- 例を使用して説明されたBashリダイレクト
1.2。ヘッダーを大文字にする
CSVファイルにはヘッダーがある場合とない場合があります。ただし、ヘッダーがある場合は、読みやすくするために常に大文字にします。 awkを使用して簡単に行うことができます またはsed 。両方の方法を紹介します。
awk 'BEGIN{FS=",";OFS=","}
{
if(NR==1){
print toupper($0)
} else {
print
}
}' player.csv > player_cleaned.csv>
ここでは、(NR==1を使用して行が最初の行であるかどうかを確認しています )そしてtoupper()を使用する それを大文字にする機能。同じスニペットをワンライナーとして書くことができます。
awk 'NR==1{ print toupper($0) }NR>1' player.csv > player_cleaned.csv
awkを使用する 、変更を新しいファイルに再度リダイレクトする必要があります。代わりに、'sedを使用できます '変更をファイルに直接変更します。ここで\U 大文字と小文字を大文字に変換します。小文字に変換する場合は、 \Lを使用します 。
$ sed -i -e '1 s/(.*)/\U\1/' player_cleaned.csv
$ cat player_cleaned.csv
1.3。末尾のカンマを削除
CSVファイルの最後にカンマが含まれている場合があります。末尾のカンマを削除するには、次の方法に従います。
7の行から意図的に末尾のカンマを追加しました 〜 11 私のデータファイルにあります。
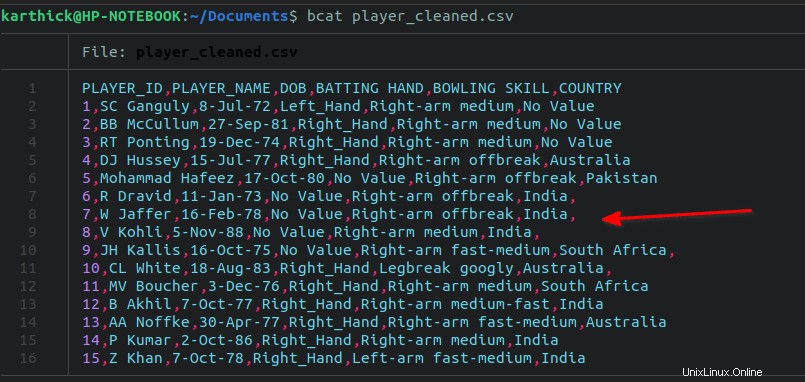
末尾のカンマをすべて削除するには、次のsedを実行します コマンド:
$ sed -i 's/,$//' ~/Documents/player_cleaned.csv
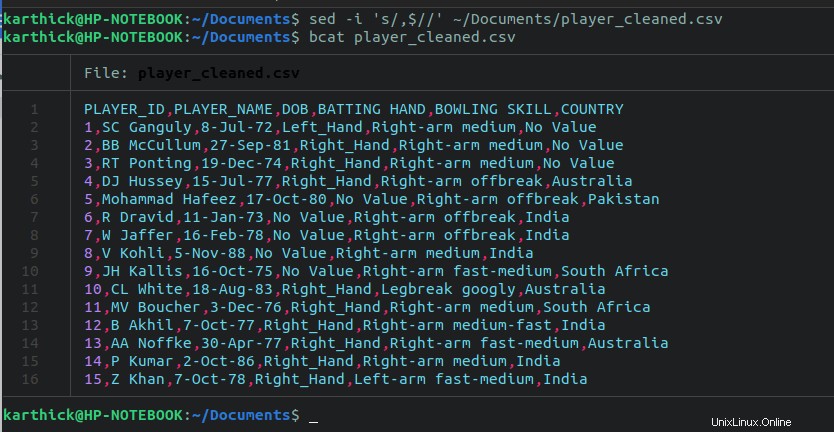
これで、クリーニング部分は完了です。さらにいくつかの手順が必要になる場合がありますが、それはCSVファイルの構造と何をクリーンアップする必要があるかによって異なります。
2。ターミナルでCSVファイルをきれいに印刷する
ターミナルでCSVファイルを表示しようとしている場合は、ファイルを表形式で印刷して読みやすくするためのオプションがいくつかあります。
2.1。列コマンド
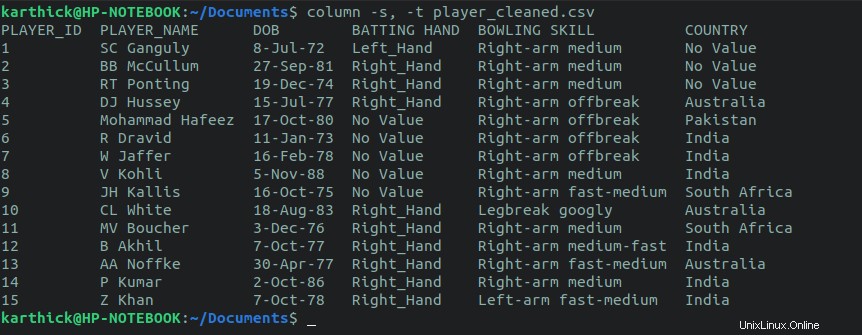
最初のアプローチは、columnを使用することです 指図。列コマンドは、コンマに設定されている区切り文字と、以下のコマンドでタブに設定されている列を分割するための区切り文字を受け入れます。独自のカスタム区切り文字を設定することもできます。
$ cat player_cleaned.csv | column -s, -t $ column -s, -t player_cleaned.csv
2.2。 CSVルックコマンド
Csvlookは、csvkitパッケージに付属するユーティリティです。 columnで行ったように、区切り文字を設定する必要はありません。 コマンド。
$ cat player_cleaned.csv | csvlook
$ csvlook player_cleaned.csv
2.3。 Python Pretty Table
Pythonをお持ちの場合かなりテーブル モジュールをインストールしたら、次のワンライナーを実行し、CSVファイルをリダイレクトしてテーブルを生成できます。
python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))" < player_cleaned.csv
エイリアスを作成することもできます ワンライナーの場合は、ファイル名を引数として渡します。
$ alias ptable='python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))"'
$ ptable < player_cleaned.csv
3。 CSVファイルからデータを取得する
3.1。行と列の数を印刷
CSVファイルの列数を取得するには、次のコマンドを実行します。ここで変数NF 区切り文字としてコンマで分割されたフィールドの数を表します。
$ awk -F, 'END{print NF}' player_cleaned.csv
6
行数を取得するには、次のコマンドを実行します。ここで、変数 NR 現在のレコードを表します(つまり、各行は1つのレコードと見なされます。
$ awk -F, 'END{print NR}' player_cleaned.csv
16 最初の行(ヘッダー)をスキップして行数を計算するには、次のコマンドを実行します。
$ awk -F, 'END{print NR-1}' player_cleaned.csv
15 3.2。 CSVファイル全体を印刷する
これは非常に簡単です。 catを使用できます またはawk CSVファイル全体を印刷します。
$ cat player_cleaned.csv
$ awk '{print}' player_cleaned.csv 3.3。 CSVファイルからヘッダーのみを印刷
ヘッダーだけを印刷すると、CSVファイルが保持しているデータの種類の概要がわかります。 headを使用できます またはawk ヘッダーだけを取得するコマンド。
$ head -n 1 player_cleaned.csv
$ awk 'NR==1' player_cleaned.csv PLAYER_ID,PLAYER_NAME,DOB,BATTING HAND,BOWLING SKILL,COUNTRY
3.4。ヘッダー行を除外する
ヘッダー行を除外して他のすべての行を印刷するには、awkを使用します 指図。 awk変数NR > 1 最初の行がスキップされます。
$ awk '(NR>1)' player_cleansed.csv
Sedを使用して、最初の行を除外し、他のすべての行を印刷することもできます。 1d フラグは最初の行を削除し、他のすべての行をstdout(ターミナル)に出力します。
$ sed 1d < player_cleaned.csv
3.5。特定の列を印刷する
列の位置を使用して、列全体を印刷できます。これを達成するための2つのアプローチがあります。最初のアプローチは、 awkを使用することです。 2番目のアプローチは、ループを使用することです。 。 Awkはコラムをつかむのがはるかに簡単になります。
Awkはデフォルトで区切り文字に基づいて行を分割し、値を$1に格納します 、$2 、$3 、など。awkのデフォルトの区切り文字は空白です。 。
以下のスニペットを見てください。フィールドseparator(FS="," )および出力フィールドseparator(OFS="," )はコンマに設定されます。 printステートメントは、最初の列、2番目の列、および6番目の列を印刷します。
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv 上記のスニペットはワンライナーで書くこともできます。
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv 
次に、2番目のアプローチはループを使用することです。
IFS=","
while read -r -a fields
do
echo ${fields[0]},${fields[1]},${fields[5]}
done < player_cleaned.csv 上記のスニペットを実行すると正確に何が起こるかを説明しましょう。
- 内部フィールドセパレータIFSをカンマに設定しています。
- readコマンドを使用して、「fields」という名前の配列を作成し、入力ファイルを
while loopにリダイレクトします。 。 - 反復ごとに、行ごとに読み取り、その行を配列要素として「フィールド」に格納するため、配列のインデックス位置を使用して特定の列のみを取得できます。
注: インデックス値は0..Nから始まります
3.6。条件に一致する行を印刷する
特定の条件に一致する行を印刷する場合は、awkを使用して簡単に印刷できます。 。いくつかのシナリオを見てみましょう。
列の値に一致するすべての行を出力するには、次のコマンドを実行します。ここでは、列6の値「India」に一致するすべての行を印刷しようとしています。
$ awk -F , '$6 == "India"' player_cleaned.csv

特定の値と一致しないすべての行を印刷するには、次のコマンドを実行します。 等式演算子の代わりに 、等しくない演算子を使用しています 。
$ awk -F , '$6 != "India"' player_cleaned.csv
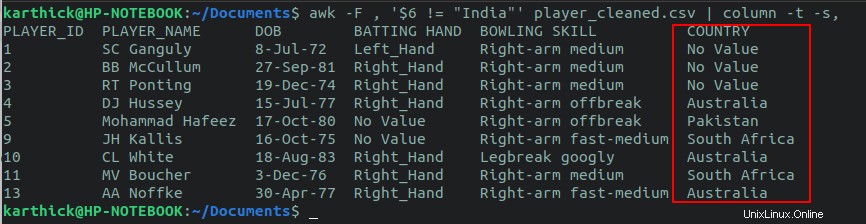
論理AND、論理OR演算子を使用して、複数の列の条件チェックを実行することもできます。国が「インド」で、打者が「右手」であるすべての行をチェックしたいとします。
ここでは、$4 4番目の列を指し、$6 6番目の列を指します。記号&& 2つの条件を評価するための論理積演算子として使用されます。
$ awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv

条件付きチェックの結果と一緒にヘッダーを含める場合は、次のコマンドを使用します。まず、NR==1を使用して最初の行を印刷しています 次に、条件チェックを実行する論理積演算子を使用して結果を出力します。
$ awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv
出力を印刷またはリダイレクトする場合は、コマンド全体をサブシェル内でブラケットで囲んで実行します。 。
$ (awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv) | column -t -s,

Csvkitに関するメモ
これまでのところ、この記事で見たものはすべて単純でわかりやすいものです。ただし、CSVファイルの構造が複雑な場合は、上記のアプローチを使用して解析するのが面倒になります。 CSVKITというユーティリティがあります 、bashでCSVファイルを操作するための優れたユーティリティです。
csvkitユーティリティの問題は、ディストリビューションにデフォルトでインストールされており、手動でインストールする必要がある場合があることです。企業環境では、外部パッケージのインストールにいくつかの制限があるため、これが不可能な場合があります。ただし、このユーティリティは言及する価値があり、別の詳細な記事を作成します。
結論
このガイドでは、awk、sedを使用してCSVファイルを操作する方法を見てきました。また、cut、grep、trなどの他のユーティリティを使用して目的の結果を得ることができますが、awkとsedを使用すると、作業が簡単になり、多くのコードを記述する複雑さが軽減されます。フィードバックがある場合は、コメントセクションにその旨を記載してください。喜んでご連絡いたします。
同様の読み取り:
- Bashスクリプト–getoptsを使用してBashスクリプトの引数を解析する
- Linuxコマンドラインツールを使用してJSONを解析してきれいに印刷する方法