一部の企業は、サービスの停止を許可できません。サーバーが停止した場合、携帯電話事業者は課金システムのダウンタイムを経験し、すべてのクライアントの接続が失われる可能性があります。そのような状況の潜在的な影響を認めることは、常に計画Bを持つという考えにつながります。
この記事では、サーバー障害に対するさまざまな保護方法と、高可用性クラスターを構築するためのコントロールパネルであるVMmanagerCloudの導入に使用されるアーキテクチャについて説明します。

クラスタトレランスの分野の用語は、Webサイトごとに異なります。異なる用語や定義が混ざらないようにするために、特定の記事で使用されるものの概要を説明しましょう。
- フォールトトレランス(FT)は、コンポーネントの1つに障害が発生した後も、システムが動作を継続できる機能です。
- クラスターは、通信チャネルを介して接続されたサーバー(クラスターノード)のグループです。
- フォールトトレラントクラスター(FTC)は、1つのサーバーに障害が発生しても、クラスター全体が完全に利用できなくなるクラスターです。障害が発生したノードの機能は、残りのノード間で自動的に再割り当てされます。
- 継続的可用性(CA)は、ユーザーがタイムアウトを発生させることなくサービスを利用できることを意味します。ノードに障害が発生してからの経過時間は関係ありません。
- 高可用性(HA)は、ノードの1つがダウンした場合に、ユーザーがサービスのタイムアウトを経験する可能性があることを意味します。ただし、システムは最小限のダウンタイムで自動的に復旧されます。
- CAクラスターは継続的な可用性クラスターです。
- HAクラスターは高可用性クラスターです。
各ノードで仮想マシンが実行されている10ノードで構成されるクラスターをデプロイする必要があるとします。目標は、サーバーに障害が発生した後に仮想マシンを保護することです。デュアルCPUサーバーは、ラックの密度の計算を最大化するために使用されます。
一見したところ、企業にとって最も魅力的なオプションは、機器に障害が発生した後もサービスがプロビジョニングされているときに、継続的可用性クラスターを展開することです。実際、課金システムの運用を維持したり、継続的な生産プロセスを自動化したりする必要がある場合は、継続的な可用性が必須です。ただし、このアプローチには、以下で説明する落とし穴と落とし穴もあります。
サービスの継続性は、このサービスを備えた物理マシンまたは仮想マシンの正確なコピーが構築されている場合にのみ実現可能であり、いつでも利用できます。このような冗長性モデルは2Nと呼ばれます。機器に障害が発生した後にサーバーのコピーを作成すると時間がかかり、サービスがタイムアウトします。さらに、この場合、障害が発生したサーバーからRAMダンプを取得することはできません。つまり、そこに含まれるすべての情報が失われます。
CAを提供するために使用される方法には、ハードウェア層とソフトウェア層の2つがあります。それぞれについて詳しく見ていきましょう。
ハードウェア方式 すべてのコンポーネントが複製され、計算が同時に独立して実行されるダブルサーバーを表します。同期は、両方の部分からの結果をチェックする専用ノードを使用して実現されます。ノードが不一致を検出すると、問題を定義してエラーを修正しようとします。エラーを修正できない場合、システムは故障したモジュールのスイッチを切ります。
CAサーバーのメーカーであるStratusは、システムの全体的なダウンタイムが年間32秒を超えないことを保証します。このような結果は、特別な装置を使用することによって達成できます。 Stratusの担当者によると、同期されたモジュールごとにデュアルCPUを搭載した1台のCAサーバーのコストは、仕様にもよりますが、約16万ドルです。この場合のCAクラスター全体の拡張価格は$1600000になります。
ソフトウェア方式
この記事の時点でContinuousAvailabilityクラスターを展開するための最も一般的なソフトウェアツールはVMwarevSphereです。この製品の継続的な可用性テクノロジーは、フォールトトレランスと呼ばれます。
ハードウェア方式とは異なり、このテクノロジーには次のような特定の要件があります。
- 物理ホスト上のCPU:
- Intel with Sandy Bridgeアーキテクチャ(またはそれ以降)。 Avotonはサポートされていません。
- AMD Bulldozer(またはそれ以降)。
- フォールトトレランスを備えたマシンは、低遅延で1つの10Gbネットワークに接続されます。 VMwareでは、専用ネットワークを使用することを強くお勧めします。
- VMあたり4つ以下の仮想CPU。
- 物理ホストあたり8個以下の仮想CPU。
- 物理ホストあたり4台以下の仮想マシン。
- 仮想マシンのスナップショットは使用できません。
制限と非互換性の完全なリストは、公式ドキュメントにあります。
vSphereライセンスは、物理CPUに基づいています。価格は、ライセンスあたり1750ドル+年間サブスクリプションとサポートの550ドルから始まります。クラスタ管理の自動化には、8000ドルを超えるVMwarevCenterServerも必要です。 2Nモデルは継続的な可用性を提供するために使用されるため、仮想マシンを備えた10ノードのクラスターを構築するには、それぞれのライセンスを持つ10台の複製サーバーを購入する必要があります。
ソフトウェアの全体的なコストは、2[サーバーあたりのCPU数]*(10[仮想マシンを備えたノードの数]+10 [複製されたノードの数])*(1750 + 550)[各CPUあたりのライセンスコスト]+8000になります。 [VMwarevCenterServerのコスト]=$100000。すべての価格は四捨五入されています。
サーバーコンポーネントはクラスターの目的によって常に異なるため、この記事では特定のノード構成については説明しません。ネットワーク機器についても、すべての場合で同一である必要があるため、説明していません。この記事では、ライセンスコストである、確実に変化するコンポーネントに焦点を当てています。
開発およびサポートされなくなった製品について言及することも重要です。
Remusと呼ばれる製品は、Xen仮想化に基づいています。これは、マイクロスナップショットテクノロジーを利用した無料のオープンソースソリューションです。残念ながら、そのドキュメントは長い間更新されていません。インストールガイドには、2014年にサポート終了が発表されたUbuntu 12.10の手順が記載されています。Google検索でも、Remusを運用に使用している会社は見つかりませんでした。
>QEMUを変更して、このテクノロジーで継続的可用性クラスターを構築する試みが行われました。この方向での作業を発表した2つのプロジェクトがあります。
1つ目は田村義晃が率いるオープンソースの蹴鞠です。このプロジェクトは、ライブQEMU移行を使用することを目的としています。最後のコミットは2011年2月に行われたもので、開発が行き詰まりに達し、継続されないことを示唆しています。
2番目の製品は、MichaelHinesによって設立されたオープンソースプロジェクトであるMicroCheckpointingです。昨年の変更ログには、Kemariプロジェクトに似たアクティビティは見つかりませんでした。
これらの事実により、今日までKVM仮想化で継続的に可用性を実現する可能性はまったくないという結論を下すことができます。
継続的可用性システムのすべての利点にもかかわらず、そのようなソリューションを展開および運用する方法には多くの障害があります。それでも、場合によっては、フォールトトレランスが必要になることがありますが、継続的に利用できる必要はありません。このようなシナリオでは、高可用性を備えたクラスターを使用できます。
高可用性クラスターは、ハードウェアがダウンしているかどうかを自動的に検出し、その後、使用可能なノードでサービスを起動することにより、フォールトトレランスを提供します。
高可用性は、ノードで起動されたCPUの同期をサポートしておらず、ローカルディスクの同期を常に許可しているわけではありません。これを念頭に置いて、ノードが使用するドライブをネットワークストレージなどの別の独立したストレージに配置することをお勧めします。
理由は明らかです。障害が発生した後はノードに到達できず、ストレージデバイスから情報を取得できません。データストレージシステムもフォールトトレラントである必要があります。そうでない場合、高可用性の可能性はありません。その結果、高可用性クラスターは2つのサブクラスターで構成されます。
- 仮想マシンを備えたノードで構成されるクラスターの計算
- コンピューティングノードで使用されるディスクを備えたストレージクラスター。
現在、クラスターノード上の仮想マシンで高可用性クラスターを実装するために使用されるソリューションは次のとおりです。
- ハートビート、バージョン1。? DRBDを使用;
- ペースメーカー;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Hyper-Vサーバーの役割を持つWindowsServerフェールオーバークラスタリング;
- VMmanagerCloud。
VMmanagerCloudを詳しく見てみましょう。
VMmanagerクラウド
VMmanager Cloudは、高可用性クラスターのデプロイを可能にし、QEMU-KVM仮想化を使用する製品です。このテクノロジが選択されたのは、積極的に開発およびサポートされており、仮想マシンに任意のオペレーティングシステムをインストールできるためです。この製品は、Corosyncを使用してクラスターの可用性を検出します。サーバーの1つがダウンしている場合、VMmanagerは仮想マシンを残りのノードに1つずつ分散します。
簡略化された形式では、このメカニズムは次のように機能します。
- システムは、仮想マシンの数が最も少ないクラスターノードを識別します。
- マシンを見つけるのに十分なRAMがあるかどうかをチェックします。
- ノードに関連するマシン用の十分なメモリがある場合、VMmanagerはこのノードに新しい仮想マシンを作成します。
- 十分なメモリがない場合、システムはより多くの仮想マシンで他のノードをチェックします。
いくつかのハードウェア構成をテストし、現在の多くのVMmanagerクラウドユーザーに問い合わせたところ、機器のパフォーマンスにもよりますが、障害が発生したノードからすべてのVMの動作を分散して復元するには、通常45〜90秒かかることがわかりました。
緊急事態に対する保護手段として1つまたはいくつかのノードを専用にし、通常の操作中にこれらのノードにVMをデプロイしないことをお勧めします。障害が発生したノードから仮想マシンを追加するために、ライブクラスターノードでリソースが不足する可能性を最小限に抑えます。バックアップノードが1つだけ使用されている場合、そのようなセキュリティモデルはN+1と呼ばれます。
VMmanager Cloudは、ファイルシステム、LVM、ネットワークLVM、iSCSI、およびCeph [特に、Ceph実装の1つであるRBD(RADOSブロックデバイス)]のストレージタイプをサポートします。後者の3つは、高可用性に使用されます。
10個の運用ノードと1個のバックアップノードの1つのライフタイムライセンスのコストは3520ユーロ、つまり現在までに3865ドルです(CPU番号に関係なく、1つのライセンスのコストはノードあたり320ユーロです)。ライセンスには、1年間の無料アップデートが含まれています。 2年目から、サブスクリプションモデルごとに、クラスター全体で年間880ユーロの価格でアップデートが提供されます。
VMmanagerCloudが高可用性クラスターのデプロイにどのように使用されているかを確認しましょう。
FirstByte
FirstByteは、2016年2月にクラウドホスティングの提供を開始しました。当初、クラスターはOpenStack上に構築されていました。ただし、可用性とコストの両方の点でこのシステムのスペシャリストが不足しているため、代替ソリューションを探す必要がありました。高可用性クラスターを構築するための新しいシステムは、次の要件を満たすことでした。
- KVM仮想マシンをデプロイする機能。
- Cephとの統合。
- 既存のサービスを提供するための課金システムとの統合。
- 手頃なライセンス費用。
- ソフトウェア開発者からのサポート。
VMmanagerCloudはすべての要件に適合します。
FirstByteクラスターの特徴:
- データ転送は、イーサネットテクノロジーとシスコの機器に基づいています。
- ルーティングはCiscoASR9001を使用して実行されます。クラスタは約50000のIPv6アドレスを使用します。
- コンピューティングノードとスイッチ間のリンク速度は10Gbpsです。
- スイッチとストレージノード間のデータ転送速度は20 Gbpsで、2つのチャネルを組み合わせてそれぞれ10Gbpsにします。
- レプリケーション用のストレージノードを備えたラック間で、個別の20Gbpsリンクが使用されます。
- SSDと組み合わせたSASディスクは、すべてのストレージノードにインストールされます。
- ストレージタイプはRBDです。
システムレイアウトを以下に示します:
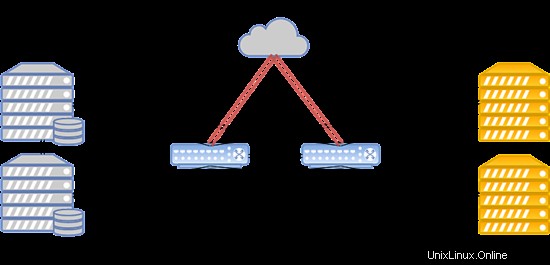
このような構成は、平均以上の負荷で人気のあるWebサイト、ゲームサーバー、データベースをホストする場合に機能します。
FirstVDS
FirstVDSは、2015年9月に開始されたフォールトトレラントクラスタのサービスを提供します。
このクラスターには、次の要因によりVMmanagerCloudが選択されました。
- ISPsystemコントロールパネルを使用した確かな経験。
- デフォルトでBILLmanagerと統合します。
- 高品質のテクニカルサポート。
- Cephとの統合。
彼らのクラスターには次の機能があります:
- データ転送は、接続速度が56GbpsのInfinibandネットワークに基づいています。
- InfinibandネットワークはMellanox機器で構築されています;
- ストレージノードにはSSDドライブがあります;
- ストレージタイプはRBDです。
システムは次のようにレイアウトできます。
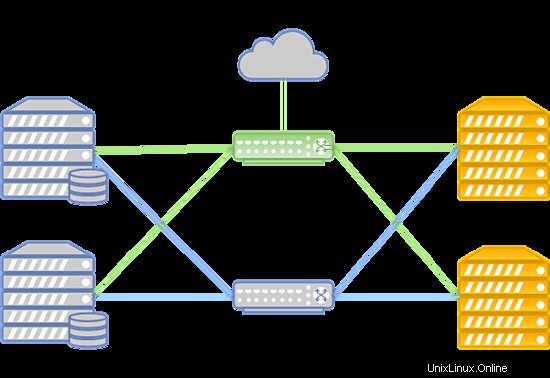
Infinibandネットワークに障害が発生した場合、VMディスクストレージとコンピューティングサーバー間の接続は、Juniper機器に展開されたイーサネットネットワークを介して確立されます。新しい接続は自動的に設定されます。
ストレージとの通信が高速であるため、このクラスターは、トラフィックが非常に多いWebサイト、ビデオとコンテンツのストリーミング、およびビッグデータをホストするのに最適です。
記事の主な調査結果をまとめましょう。
継続的な可用性クラスターは、1秒ごとのダウンタイムが大幅な損失をもたらす場合に必須です。仮想マシンがバックアップノードにデプロイされている間に5分間の停止が許可されている場合、高可用性クラスターはハードウェアとソフトウェアのコストを削減するための優れたオプションになる可能性があります。
フォールトトレランスを実現する唯一の方法は過度であることを忘れないでください。サーバー、データ通信機器とリンク、インターネットアクセスチャネルと電源を必ず複製してください。できる限りすべてを複製します。このような対策により、システム全体のダウンタイムを引き起こす可能性のあるボトルネックや潜在的な障害点を排除することができます。上記の対策を講じることで、障害に強いフォールトトレラントクラスターを確保できます。
高可用性モデルが要件に適合し、VMmanager Cloudがそれを実現するための優れたツールであると思われる場合は、インストールマニュアルとドキュメントを参照して、システムの詳細を確認してください。私 失敗のない継続的な操作をお祈りします!