データベースサーバーの管理を担当している場合は、クエリを実行して慎重に検査する必要がある場合があります。 MySQLからそれを行うことができますが / MariaDB シェルですが、このヒントを使用すると、Linuxコマンドラインを使用してMySQL / MariaDBクエリを直接実行し、後で調べるために出力をファイルに保存できます(これは、クエリが大量のレコードを返す場合に特に便利です)。
より高度なクエリに移る前に、コマンドラインから直接クエリを実行する簡単な例をいくつか見てみましょう。
サーバー上のすべてのデータベースを表示するには、次のコマンドを発行できます。
# mysql -u root -p -e "show databases;"
次に、tutorialsという名前のデータベーステーブルを作成します データベース内tecmintdb 、以下のコマンドを実行します:
$ mysql -u root -p -e "USE tecmintdb; CREATE TABLE tutorials(tut_id INT NOT NULL AUTO_INCREMENT, tut_title VARCHAR(100) NOT NULL, tut_author VARCHAR(40) NOT NULL, submissoin_date DATE, PRIMARY KEY (tut_id));"
次のコマンドを使用して、出力をteeにパイプします。 コマンドの後に、出力を保存するファイル名を続けます。
推奨される読み物: Linuxでのデータベース管理のための20のMySQL/MariaDBコマンド
説明のために、employeesという名前のデータベースを使用します。 従業員間の単純な結合 および給与 テーブル。自分の場合は、引用符の間にSQLクエリを入力し、 Enterを押します。 。
データベースユーザーのパスワードを入力するように求められることに注意してください:
# mysql -u root -p -e "USE employees; SELECT DISTINCT A.first_name, A.last_name FROM employees A JOIN salaries B ON A.emp_no = B.emp_no WHERE hire_date < '1985-01-31';" | tee queryresults.txt
catコマンドを使用してクエリ結果を表示します。
# cat queryresults.txt

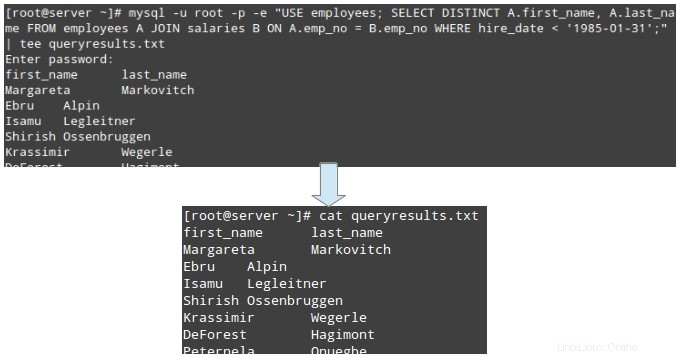
クエリ結果がプレーンテキストファイルになると、他のコマンドラインユーティリティを使用してレコードをより簡単に処理できます。
概要
システム管理者として、日常のLinuxタスクを自動化したり、より簡単に実行したりする際に役立つと思われるLinuxのヒントをいくつか紹介しました。
推奨される読み物: MySQL/MariaDBデータベースをバックアップおよび復元する方法
コミュニティの他の人と共有したい他のヒントはありますか?その場合は、下のコメントフォームを使用してください。
それ以外の場合は、私たちが検討したさまざまなヒント、またはそれぞれを改善するために追加または実行できる可能性のあるヒントについて、お気軽にご意見をお聞かせください。ご連絡をお待ちしております!