Unix / Linuxで特定のコマンドを実行して文字列またはファイルからテキストを読み取ったり編集したりする場合、ほとんどの場合、対象の特定のセクションへの出力をフィルタリングしようとします。ここで正規表現を使用すると便利です。
関連項目: 実用的な例を含む10の便利なLinux連鎖演算子
正規表現とは何ですか?
正規表現は、文字のいくつかのシーケンスを表す文字列として定義できます。正規表現で最も重要なことの1つは、コマンドまたはファイルの出力をフィルタリングしたり、テキストまたは構成ファイルのセクションを編集したりできることです。
正規表現の機能
正規表現は次のもので構成されています:
- 普通のキャラクター スペース、アンダースコア(_)、A-Z、a-z、0-9など。
- メタキャラクター 通常の文字に拡張されたものには、次のものが含まれます。
-
(。)改行以外の任意の1文字に一致します。 -
(*) 直前の文字の0個以上の存在と一致します。 [文字] 文字で指定された文字のいずれかに一致します。ハイフン(-)を使用することもできます[a-f]などの文字の範囲を意味します 、[1-5]、など。-
^ファイルの行頭と一致します。 -
$ファイルの行末と一致します。 -
\エスケープ文字です。
-
テキストをフィルタリングするには、 awkなどのテキストフィルタリングツールを使用する必要があります 。 awkについて考えることができます 独自のプログラミング言語として。ただし、このガイドの範囲については、 awkを使用してください 、簡単なコマンドラインフィルタリングツールとして説明します。
awkの一般的な構文は次のとおりです。
# awk 'script' filename
'script' awkによって理解されるコマンドのセットです ファイル、ファイル名で実行されます。
これは、ファイル内の特定の行を読み取り、その行のコピーを作成してから、その行でスクリプトを実行することによって機能します。これは、ファイル内のすべての行で繰り返されます。
'script' '/ pattern / action'の形式です ここでパターン は正規表現であり、アクション awkが行で指定されたパターンを見つけたときに何をするかです。
LinuxでAwkフィルタリングツールを使用する方法
次の例では、awkの機能の下で上記で説明したメタ文字に焦点を当てます。
awkの簡単な使用例:
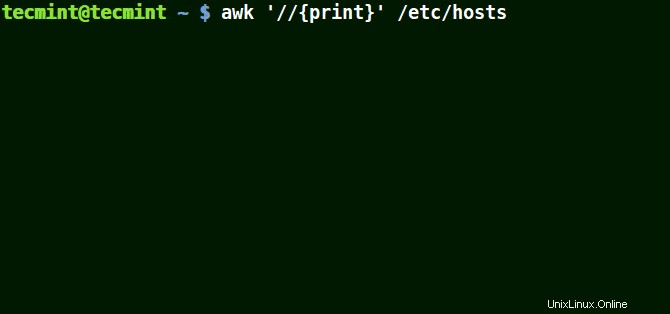
次の例では、ファイル / etc / hostsのすべての行を出力します。 パターンが与えられていないので。
# awk '//{print}'/etc/hosts

パターンでAwkを使用する:
以下の例では、パターン localhost が与えられているので、awkは localhostを持つ行と一致します / etc / hostsにあります ファイル。
# awk '/localhost/{print}' /etc/hosts

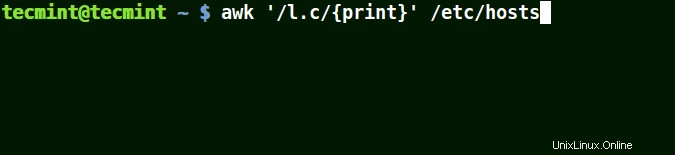
パターンで(。)ワイルドカードを使用してAwkを使用する
(。) locを含む文字列に一致します 、ローカルホスト 、ローカルネット 以下の例では。
つまり、 * l some_single_character c * 。
# awk '/l.c/{print}' /etc/hosts
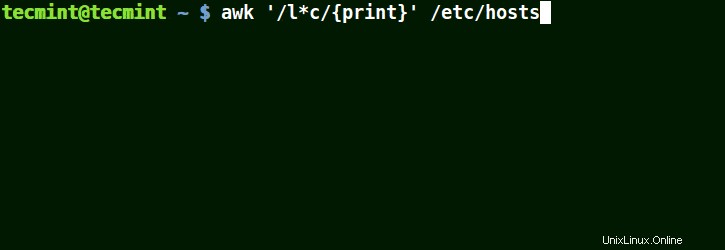
パターン内の(*)文字でのAwkの使用
localhostを含む文字列と一致します 、ローカルネット 、行 、対応 、以下の例のように:
# awk '/l*c/{print}' /etc/localhost
また、(*) 検出可能な最長の一致を取得しようとします。
これを示すケースを見てみましょう。正規表現t* tを使用します。 これは、文字 tで始まる文字列に一致することを意味します tで終わります 下の行:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
パターン/t * t / を使用すると、次の可能性があります。 :
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
そして(*) / t * t /で ワイルドカード文字を使用すると、awkは最後のオプションを選択できます:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
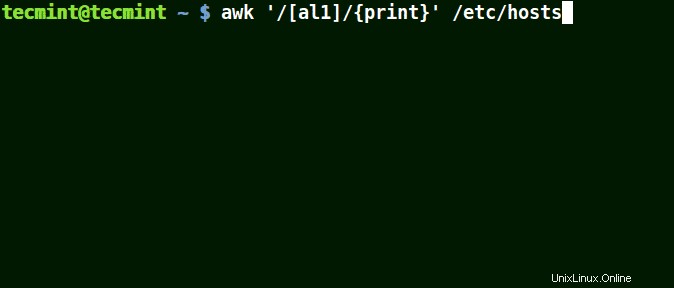
セット[文字]でAwkを使用する
たとえば、セット [al1] 、ここでawkは、文字 aを含むすべての文字列に一致します またはl または1 ファイル/etc / hostsの1行 。
# awk '/[al1]/{print}' /etc/hosts
次の例は、いずれかの Kで始まる文字列に一致します またはk 続いてT :
# awk '/[Kk]T/{print}' /etc/hosts

範囲内の文字の指定
awkで文字を理解する:
-
[0-9]単一の数字を意味します -
[a-z]単一の小文字に一致することを意味します -
[A-Z]単一の大文字に一致することを意味します -
[a-zA-Z]1文字に一致することを意味します -
[a-zA-Z 0-9]単一の文字または数字に一致することを意味します
以下の例を見てみましょう:
# awk '/[0-9]/{print}' /etc/hosts
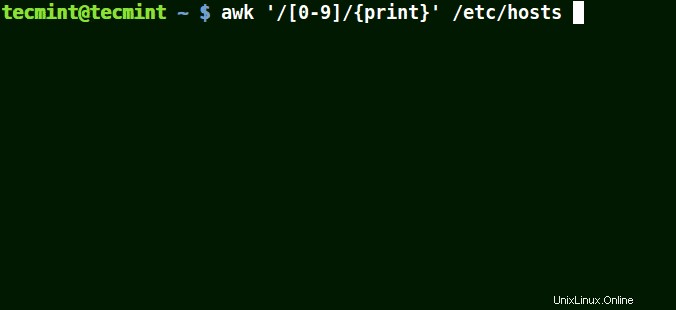
ファイル/etc / hostsのすべての行 少なくとも1つの数字を含む[0-9] 上記の例では。
(^)メタ文字でAwkを使用する
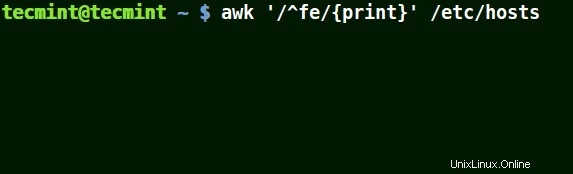
これは、以下の例のように提供されたパターンで始まるすべての行に一致します。
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
($)メタ文字でAwkを使用する
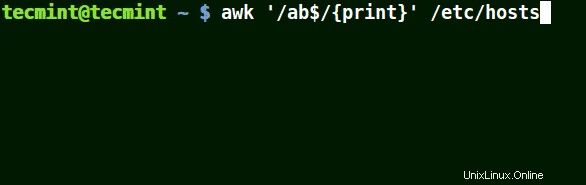
提供されたパターンで終わるすべての行に一致します:
# awk '/ab$/{print}' /etc/hosts
# awk '/ost$/{print}' /etc/hosts
# awk '/rs$/{print}' /etc/hosts
(\)エスケープ文字でAwkを使用する
これにより、それに続く文字をリテラルと見なすことができます。つまり、そのままと見なすことができます。
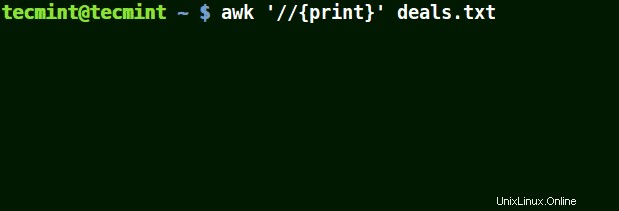
次の例では、最初のコマンドはファイル内のすべての行を出力し、2番目のコマンドは $ 25.00 の行と一致させたいため、何も出力しません。 、ただしエスケープ文字は使用されません。
$ の読み取りにエスケープ文字が使用されているため、3番目のコマンドは正しいです。 そのまま。
# awk '//{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
# awk '/\$25.00/{print}' deals.txt
概要
awkだけではありません コマンドラインフィルタリングツール、上記の例はawkの基本的な操作です。次のパートでは、awkの複雑な機能の使用方法について説明します。読んでいただきありがとうございます。追加や説明があれば、コメントセクションにコメントを投稿してください。