ApacheSparkは分散コンピューティングシステムです。これは、マスターと1つ以上のスレーブで構成され、マスターがスレーブ間で作業を分散するため、多数のコンピューターを使用して1つのタスクを実行できます。これは確かに、タスクを完了するために大規模な計算が必要な強力なツールであると推測できますが、作業のためにスレーブにプッシュできるステップの小さなチャンクに分割できます。クラスタが起動して実行されると、Python、Java、Scalaで実行するプログラムを作成できます。
このチュートリアルでは、Red Hat Enterprise Linux 8を実行している単一のマシンで作業し、Sparkマスターとスレーブを同じマシンにインストールしますが、スレーブのセットアップを説明する手順は、任意の数のコンピューターに適用できることに注意してください。したがって、重いワークロードを処理できる実際のクラスターを作成します。また、管理に必要なユニットファイルを追加し、分散パッケージに付属しているクラスターに対して簡単な例を実行して、システムが動作していることを確認します。
このチュートリアルでは、次のことを学びます。
- Sparkマスターとスレーブをインストールする方法
- systemdユニットファイルを追加する方法
- マスタースレーブ接続が成功したことを確認する方法
- クラスターで簡単なサンプルジョブを実行する方法
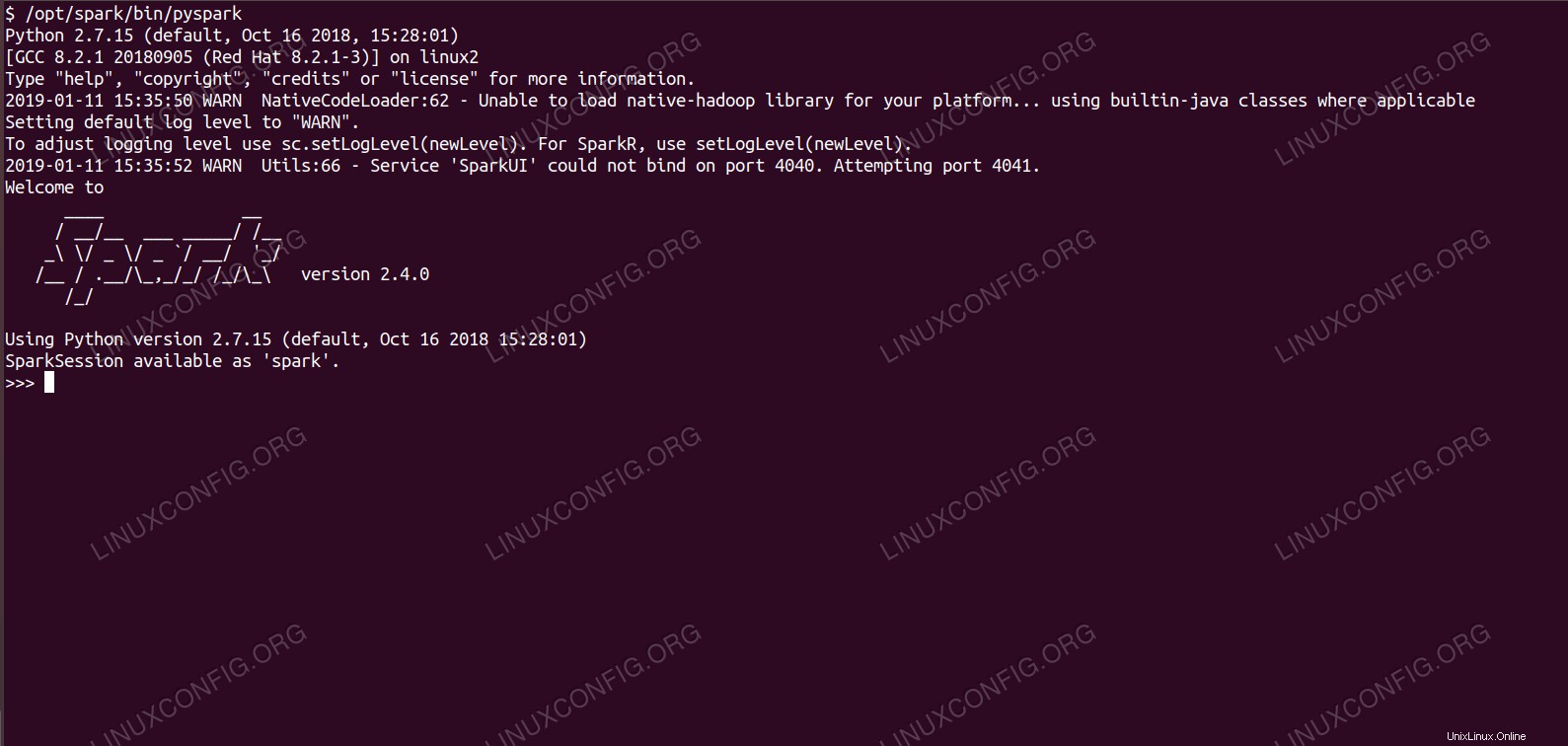 pysparkでシェルをスパークします。
pysparkでシェルをスパークします。 使用されるソフトウェア要件と規則
| カテゴリ | 使用する要件、規則、またはソフトウェアバージョン |
|---|---|
| Red Hat Enterprise Linux 8 | |
| Apache Spark 2.4.0 | |
rootまたはsudoを介したLinuxシステムへの特権アクセス コマンド。 | |
# –指定されたLinuxコマンドは、rootユーザーとして直接、またはsudoを使用して、root権限で実行する必要があります。 コマンド$ –特定のLinuxコマンドを通常の非特権ユーザーとして実行する必要があります |
Redhat8にsparkをインストールする方法ステップバイステップの説明
Apache SparkはJVM(Java仮想マシン)で実行されるため、アプリケーションを実行するには、Java8をインストールする必要があります。それとは別に、パッケージには複数のシェルが同梱されており、そのうちの1つはpysparkです。 、Pythonベースのシェル。これを使用するには、Python2をインストールしてセットアップする必要もあります。
- Sparkの最新パッケージのURLを取得するには、Sparkダウンロードサイトにアクセスする必要があります。場所に最も近いミラーを選択し、ダウンロードサイトから提供されたURLをコピーする必要があります。これは、URLが以下の例と異なる場合があることも意味します。
/opt/の下にパッケージをインストールします 、したがって、ディレクトリをrootとして入力します。 :# cd /opt
取得したURLを
wgetにフィードします パッケージを入手するには:# wget https://www-eu.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
- tarballを解凍します:
# tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
- シンボリックリンクを作成して、次の手順でパスを覚えやすくします。
# ln -s /opt/spark-2.4.0-bin-hadoop2.7 /opt/spark
- マスターとスレーブの両方のアプリケーションを実行する非特権ユーザーを作成します:
# useradd spark
そして、それを
/opt/spark全体の所有者として設定します ディレクトリ、再帰的に:# chown -R spark:spark /opt/spark*
-
systemdを作成します ユニットファイル/etc/systemd/system/spark-master.service次のコンテンツを含むマスターサービスの場合:[Unit] Description=Apache Spark Master After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-master.sh ExecStop=/opt/spark/sbin/stop-master.sh [Install] WantedBy=multi-user.targetまた、
/etc/systemd/system/spark-slave.service.serviceとなるスレーブサービス用の1つです。 以下の内容で:[Unit] Description=Apache Spark Slave After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 ExecStop=/opt/spark/sbin/stop-slave.sh [Install] WantedBy=multi-user.target強調表示されたスパークURLに注意してください。これは、
spark://<hostname-or-ip-address-of-the-master>:7077で構成されています。 、この場合、マスターを実行するラボマシンのホスト名はrhel8lab.linuxconfig.orgです。 。マスターの名前は異なります。すべてのスレーブは、このホスト名を解決し、指定されたポート(ポート7077)でマスターに到達できる必要があります。 デフォルトで。 - サービスファイルを配置したら、
systemdに問い合わせる必要があります それらを再読み込みするには:# systemctl daemon-reload
- Sparkマスターは
systemdで起動できます :# systemctl start spark-master.service
- マスターが実行中で機能していることを確認するには、systemdステータスを使用できます:
# systemctl status spark-master.service spark-master.service - Apache Spark Master Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2019-01-11 16:30:03 CET; 53min ago Process: 3308 ExecStop=/opt/spark/sbin/stop-master.sh (code=exited, status=0/SUCCESS) Process: 3339 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS) Main PID: 3359 (java) Tasks: 27 (limit: 12544) Memory: 219.3M CGroup: /system.slice/spark-master.service 3359 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host [...] Jan 11 16:30:00 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Master... Jan 11 16:30:00 rhel8lab.linuxconfig.org start-master.sh[3339]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org.apache.spark.deploy.master.Master-1[...]最後の行は、
logsにあるマスターのメインログファイルも示しています。 Sparkベースディレクトリの下のディレクトリ、/opt/spark私たちの場合には。このファイルを調べると、次の例のような行が最後に表示されます。2019-01-11 14:45:28 INFO Master:54 - I have been elected leader! New state: ALIVE
また、マスターインターフェイスがリッスンしている場所を示す行を見つける必要があります:
2019-01-11 16:30:03 INFO Utils:54 - Successfully started service 'MasterUI' on port 8080
ブラウザでホストマシンのポート
8080を指定した場合 、現時点ではワーカーが接続されていない、マスターのステータスページが表示されます。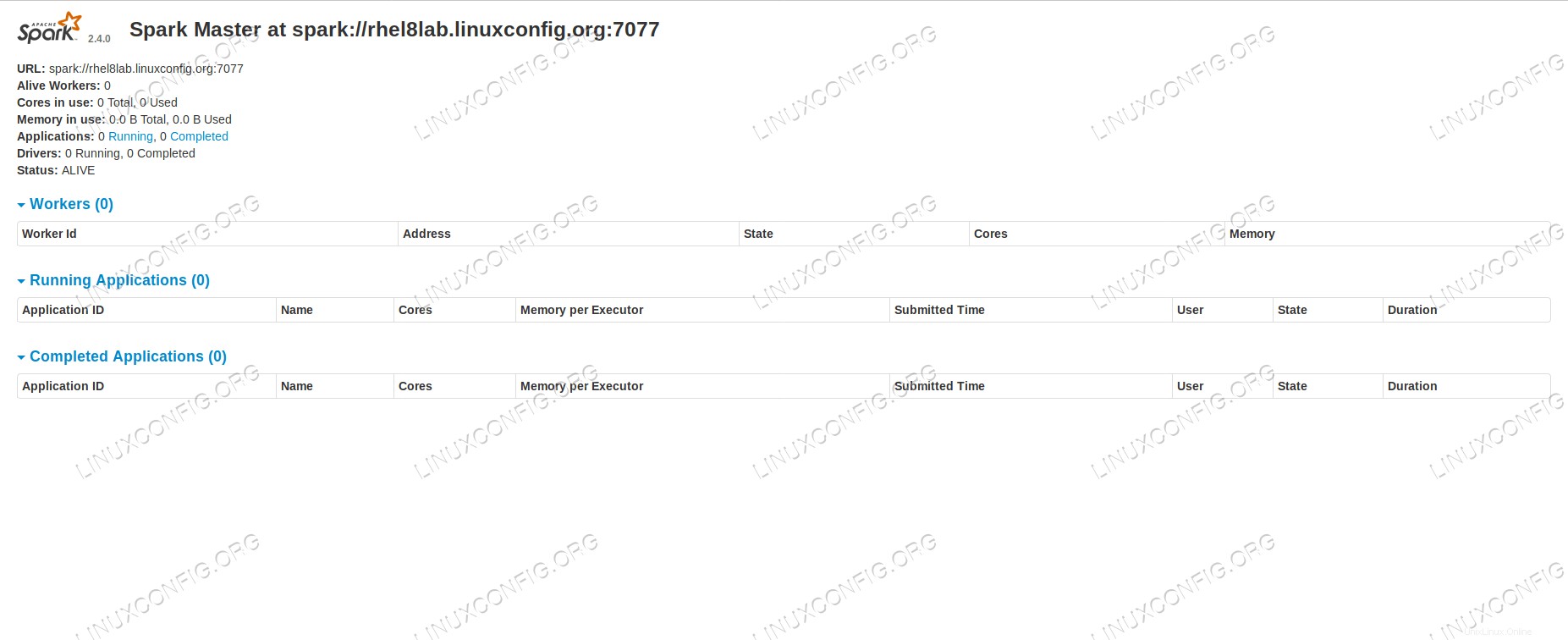 ワーカーが接続されていないSparkマスターステータスページ。
ワーカーが接続されていないSparkマスターステータスページ。 SparkマスターのステータスページのURL行に注意してください。これは、
step 5で作成したすべてのスレーブのユニットファイルに使用する必要があるURLと同じです。 。
ブラウザに「接続が拒否されました」というエラーメッセージが表示された場合は、ファイアウォールのポートを開く必要があります。# firewall-cmd --zone=public --add-port=8080/tcp --permanent success # firewall-cmd --reload success
- マスターが実行されているので、それにスレーブを接続します。スレーブサービスを開始します:
# systemctl start spark-slave.service
- スレーブがsystemdで実行されていることを確認できます:
# systemctl status spark-slave.service spark-slave.service - Apache Spark Slave Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2019-01-11 16:31:41 CET; 1h 3min ago Process: 3515 ExecStop=/opt/spark/sbin/stop-slave.sh (code=exited, status=0/SUCCESS) Process: 3537 ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 (code=exited, status=0/SUCCESS) Main PID: 3554 (java) Tasks: 26 (limit: 12544) Memory: 176.1M CGroup: /system.slice/spark-slave.service 3554 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker [...] Jan 11 16:31:39 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Slave... Jan 11 16:31:39 rhel8lab.linuxconfig.org start-slave.sh[3537]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spar[...]この出力は、同じディレクトリにあり、名前に「worker」が含まれるスレーブ(またはワーカー)のログファイルへのパスも提供します。このファイルをチェックすると、次の出力のようなものが表示されます。
2019-01-11 14:52:23 INFO Worker:54 - Connecting to master rhel8lab.linuxconfig.org:7077... 2019-01-11 14:52:23 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@62059f4a{/metrics/json,null,AVAILABLE,@Spark} 2019-01-11 14:52:23 INFO TransportClientFactory:267 - Successfully created connection to rhel8lab.linuxconfig.org/10.0.2.15:7077 after 58 ms (0 ms spent in bootstraps) 2019-01-11 14:52:24 INFO Worker:54 - Successfully registered with master spark://rhel8lab.linuxconfig.org:7077これは、ワーカーがマスターに正常に接続されていることを示しています。この同じログファイルに、ワーカーがリッスンしているURLを示す行があります。
2019-01-11 14:52:23 INFO WorkerWebUI:54 - Bound WorkerWebUI to 0.0.0.0, and started at http://rhel8lab.linuxconfig.org:8081
マスターがリストされているワーカーのステータスページにブラウザを向けることができます。
 マスターに接続されたSparkワーカーのステータスページ。
マスターに接続されたSparkワーカーのステータスページ。 マスターのログファイルに、確認行が表示されます。
2019-01-11 14:52:24 INFO Master:54 - Registering worker 10.0.2.15:40815 with 2 cores, 1024.0 MB RAM
ここでマスターのステータスページをリロードすると、ワーカーもそこに表示され、ステータスページへのリンクが表示されます。
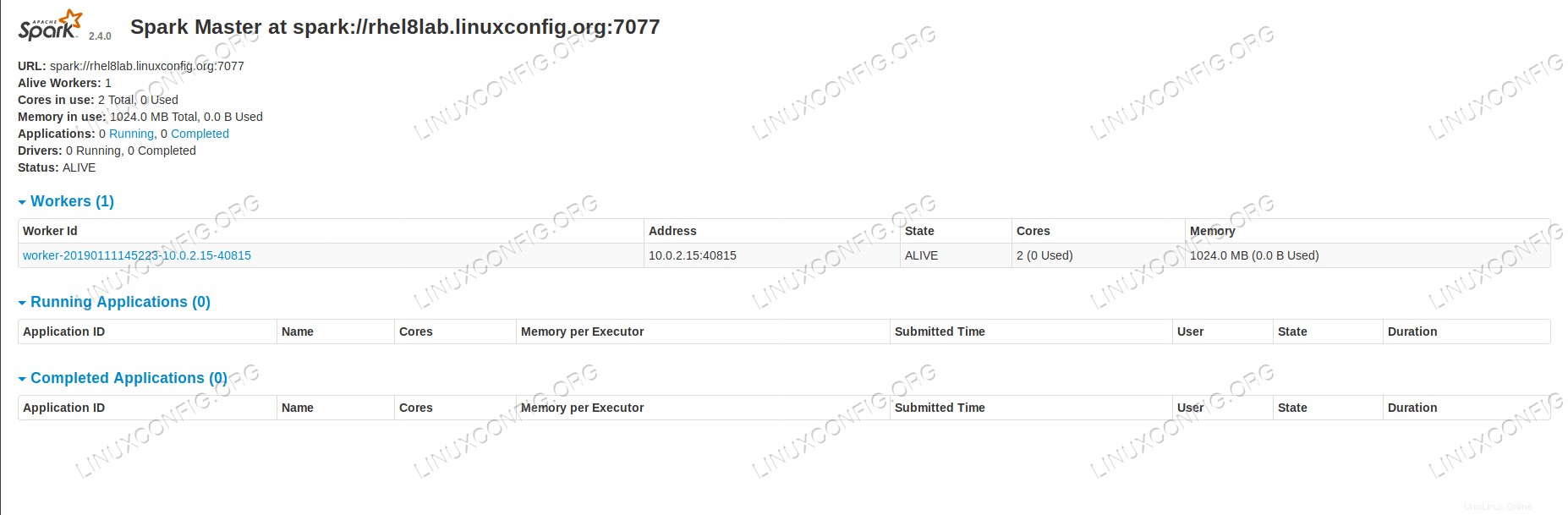 1人のワーカーが接続されたSparkマスターステータスページ。
1人のワーカーが接続されたSparkマスターステータスページ。 これらのソースは、クラスターが接続され、動作する準備ができていることを確認します。
- クラスターで簡単なタスクを実行するために、ダウンロードしたパッケージに付属している例の1つを実行します。次の単純なテキストファイル
/opt/spark/test.fileについて考えてみます。 :line1 word1 word2 word3 line2 word1 line3 word1 word2 word3 word4wordcount.pyを実行します ファイル内のすべての単語の出現をカウントする例。sparkを使用できます ユーザー、rootはありません 必要な特権。$ /opt/spark/bin/spark-submit /opt/spark/examples/src/main/python/wordcount.py /opt/spark/test.file 2019-01-11 15:56:57 INFO SparkContext:54 - Submitted application: PythonWordCount 2019-01-11 15:56:57 INFO SecurityManager:54 - Changing view acls to: spark 2019-01-11 15:56:57 INFO SecurityManager:54 - Changing modify acls to: spark [...]
タスクが実行されると、長い出力が提供されます。出力の終わり近くに結果が表示され、クラスターは必要な情報を計算します:
2019-01-11 15:57:05 INFO DAGScheduler:54 - Job 0 finished: collect at /opt/spark/examples/src/main/python/wordcount.py:40, took 1.619928 s line3: 1 line2: 1 line1: 1 word4: 1 word1: 3 word3: 2 word2: 2 [...]
これにより、ApacheSparkが動作するのを確認できました。追加のスレーブノードをインストールして接続し、クラスターのコンピューティング能力を拡張できます。