私はデータ監査人としてパートタイムで働いています。私を散文のページではなくデータの表を扱う校正者と考えてください。テーブルはリレーショナルデータベースからエクスポートされ、通常はかなり控えめなサイズです。100,000〜1,000,000レコード、50〜200フィールドです。
エラーのないデータテーブルを見たことがありません。ご想像のとおり、乱雑さは、レコードの複製、スペルとフォーマットのエラー、および間違ったフィールドに配置されたデータ項目に限定されません。私も見つけます:
- データ項目に改行が埋め込まれているため、破損したレコードが複数の行にまたがっています
- 同じレコード内の別のフィールドのデータ項目と一致しない1つのフィールドのデータ項目
- データ項目が切り捨てられたレコード。多くの場合、非常に長い文字列が50文字または100文字の制限のあるフィールドに押し込まれたためです。
- 文字化けと呼ばれるジブリッシュを生成する文字エンコードの失敗
- 非表示の制御文字。一部はデータ処理エラーを引き起こす可能性があります
- データの文字エンコードを理解できなかった最後のプログラムによって挿入された置換文字と不思議な疑問符
これらの問題をクリーンアップすることは難しいことではありませんが、それらを見つけることには技術的でない障害があります。 1つ目は、データエラーに対処することを誰もが自然に嫌がることです。表を見る前に、データの所有者または管理者は、データの悲しみの5つの段階すべてを経験している可能性があります。
- データにエラーはありません。
- まあ、いくつかのエラーがあるかもしれませんが、それほど重要ではありません。
- OK、エラーがたくさんあります。社内の担当者に対応してもらいます。
- いくつかのエラーの修正を開始しましたが、時間がかかります。新しいデータベースソフトウェアに移行するときに実行します。
- 新しいデータベースに移動するときにデータをクリーンアップする時間がありませんでした。助けを借りることができます。
2番目の進歩を妨げる態度は、データクリーニングには、高価なプロプライエタリプログラムまたは優れたオープンソースプログラムOpenRefineのいずれかの専用アプリケーションが必要であるという信念です。専用アプリケーションでは解決できない問題に対処するために、データ管理者はプログラマーに助けを求めることがあります。PythonまたはRに長けている人です。
ただし、データの監査とクリーニングには、通常、専用のアプリケーションは必要ありません。プレーンテキストのデータテーブルは何十年も前から存在しているため、テキスト処理ツールもあります。 Bashシェルを開くと、grepなどの強力なテキストプロセッサがロードされたツールボックスがあります。 、cut 、paste 、sort 、uniq 、tr 、およびawk 。高速で信頼性が高く、使いやすいです。
私はすべてのデータ監査をコマンドラインで行い、データ監査のトリックの多くを「料理本」のWebサイトに掲載しています。私が定期的に行う操作は、関数およびシェルスクリプトとして保存されます(以下の例を参照)。
はい、コマンドラインアプローチでは、監査対象のデータがデータベースからエクスポートされている必要があります。はい、監査結果は後でデータベース内で編集する必要があります。または、(データベースで許可されている場合は)クリーンアップされたデータ項目を乱雑なデータ項目の代わりにインポートする必要があります。
しかし、その利点は注目に値します。 awk コンシューマーグレードのデスクトップまたはラップトップで数百万レコードを数秒で処理します。単純な正規表現は、想像できるすべてのデータエラーを見つけます。そして、これはすべて安全に外部で行われます。 データベース構造:コマンドライン監査は、データベース刑務所から解放されたデータを処理するため、データベースに影響を与えることはできません。
Unixでトレーニングした読者は、この時点で微笑んでいるでしょう。彼らは、何年も前にこれらの方法でコマンドラインのデータを操作したことを覚えています。それ以来、処理能力とRAMが大幅に向上し、標準のコマンドラインツールが大幅に効率化されました。データ監査はかつてないほど速く、簡単になりました。そして、MicrosoftWindows10がBashおよびGNU/Linuxプログラムを実行できるようになったので、Windowsユーザーは、乱雑なデータを処理するためのUnixおよびLinuxのモットーである落ち着いてターミナルを開くことを理解できます。

例
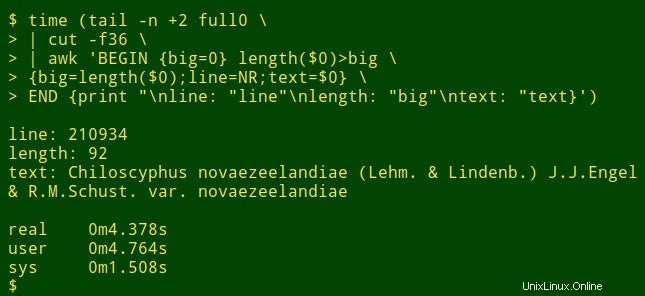
大きなテーブルの特定のフィールドで最長のデータ項目を検索するとします。これは実際にはデータ監査タスクではありませんが、シェルツールがどのように機能するかを示します。デモンストレーションの目的で、タブ区切りのテーブルfull0を使用します 、1,122,023レコード(およびヘッダー行)と49フィールドがあり、フィールド番号36を調べます(クックブックサイトで説明されている関数でフィールド番号を取得します)。
コマンドは、tailを使用して開始します full0からヘッダー行を削除します 。結果はcutにパイプされます 、これは斬首されたフィールド36を抽出します。パイプラインの次はawkです。 。ここで変数big 値0に初期化されます。次にawk 最初のレコードのデータ項目の長さをテストします。長さが0より大きい場合、awk bigをリセットします 新しい長さに変更し、行番号(NR)を変数lineに格納します 変数textのデータ項目全体 。 awk 次に、残りの1,122,022レコードのそれぞれを順番に処理し、より長いデータ項目が見つかったときに3つの変数をリセットします。最後に、行番号、データ項目の長さ、および最長のデータ項目の全文のきちんと分離されたリストを出力します。 (次のコードでは、コマンドはわかりやすくするために数行に分割されています。)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
これにはどのくらい時間がかかりますか?デスクトップ(コアi5、8 GB RAM)で約4秒:
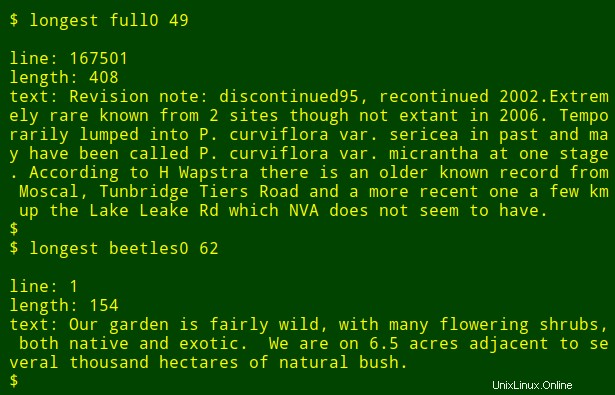
さて、きちんとした部分です。その長いコマンドをシェル関数にポップできます。longest 、引数としてファイル名($1)を取ります およびフィールド番号($2) :

次に、コマンドを関数として再実行し、コマンドの記述方法を覚えていなくても、他のフィールドや他のファイルで最長のデータ項目を見つけることができます。
最後の微調整として、検索している番号付きフィールドの名前を出力に追加できます。これを行うには、headを使用します テーブルのヘッダー行を抽出するには、その行をtrにパイプします タブを新しい行に変換し、結果のリストをtailにパイプします およびhead $2thを印刷するには リストのフィールド名。$2 フィールド番号の引数です。フィールド名はシェル変数fieldに保存されます awkに渡されます 内部awkとして印刷する場合 変数fld 。
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 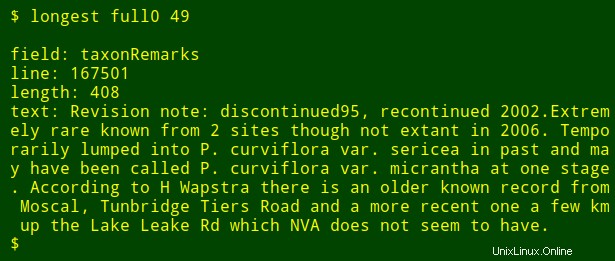
さまざまなフィールドで最長のデータ項目を探している場合は、上矢印キーを押して最後のlongestを取得するだけです。 コマンドを押してから、フィールド番号をバックスペースして新しい番号を入力します。