Hadoop は、ビッグデータを処理するために広く使用されているオープンソースフレームワークです。 。ほとんどのビッグデータ/データ分析 Hadoopエコシステムの上にプロジェクトが構築されています 。 2層で構成されており、1つはデータの保存用です。 もう1つは、データの処理用です。 。
ストレージ HDFSと呼ばれる独自のファイルシステムによって処理されます (Hadoop分散ファイルシステム )および処理 YARNが対応します (さらに別のリソースネゴシエーター )。 Mapreduce Hadoopエコシステムのデフォルトの処理エンジンです 。
この記事では、疑似ノードをインストールするプロセスについて説明します。 Hadoopのインストール 、すべてのデーモン ( JVM )は単一ノードを実行します CentOS 7上のクラスター 。
これは主に、初心者がHadoopを学ぶためのものです。リアルタイムで、 Hadoop データがブロックとしてサーバー間で分散され、ジョブが並列に実行されるマルチノードクラスターとしてインストールされます。
前提条件
- CentOS7サーバーの最小限のインストール。
- Javav1.8リリース。
- Hadoop2.xの安定したリリース。
このページについて
- CentOS7にJavaをインストールする方法
- CentOS7でパスワードなしのログインを設定する
- CentOS7にHadoopシングルノードをインストールする方法
- CentOS7でHadoopを構成する方法
- NameNodeを介したHDFSファイルシステムのフォーマット
CentOS7へのJavaのインストール
1。 Hadoop はJavaで構成されるエコシステムです 。 Javaが必要です Hadoopをインストールするためにシステムに強制的にインストールされます 。
# yum install java-1.8.0-openjdk
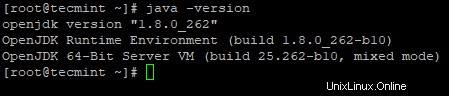
2。 次に、インストールされている Javaのバージョンを確認します システム上。
# java -version
CentOS7でパスワードなしのログインを構成する
マシンHadoopでsshを構成する必要があります SSHを使用してノードを管理します 。マスターノードはSSHを使用します スレーブノードを接続し、開始や停止などの操作を実行するための接続。
マスターがパスワードなしでsshを使用してスレーブと通信できるように、パスワードなしのsshを設定する必要があります。それ以外の場合は、接続を確立するたびに、パスワードを入力する必要があります。
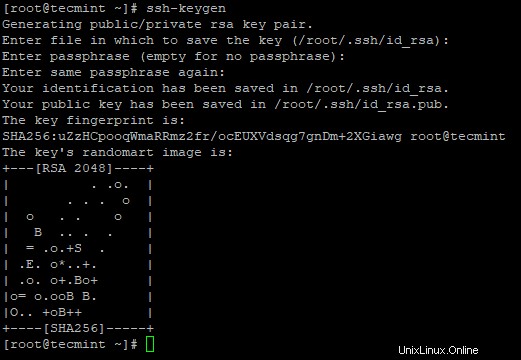
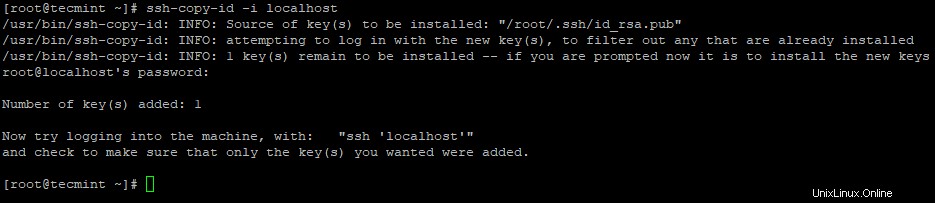
3。 サーバーで次のコマンドを使用して、パスワードなしのSSHログインを設定します。
# ssh-keygen # ssh-copy-id -i localhost
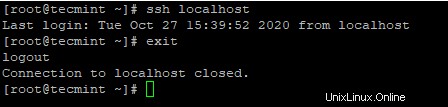
4。 パスワードなしのSSHログインを設定した後、もう一度ログインしてみてください。パスワードなしで接続されます。
# ssh localhost
CentOS7へのHadoopのインストール
5。 Apache Hadoop Webサイトにアクセスし、次のwgetコマンドを使用してHadoopの安定版をダウンロードします。
# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz # tar xvpzf hadoop-2.10.1.tar.gz
6。 次に、 Hadoopを追加します ~/.bashrcの環境変数 図のようにファイルします。
HADOOP_PREFIX=/root/hadoop-2.10.1 PATH=$PATH:$HADOOP_PREFIX/bin export PATH JAVA_HOME HADOOP_PREFIX
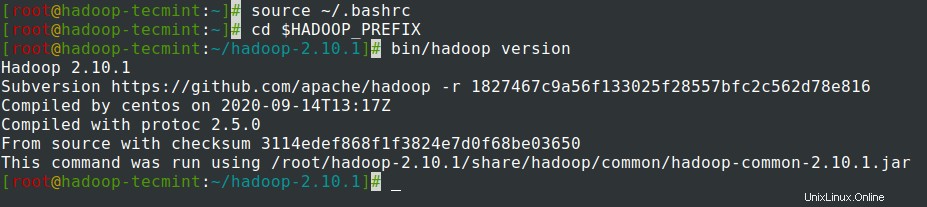
7。 ~/.bashrcに環境変数を追加した後 ファイルを作成し、ファイルを入手して、次のコマンドを実行してHadoopを確認します。
# source ~/.bashrc # cd $HADOOP_PREFIX # bin/hadoop version
CentOS7でのHadoopの構成
マシンに合わせるには、以下のHadoop構成ファイルを構成する必要があります。 Hadoopでは、 各サービスには、データを保存するための独自のポート番号と独自のディレクトリがあります。
- Hadoop構成ファイル– core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
8。 まず、JAVA_HOMEを更新する必要があります およびHadoop hadoop-env.shのパス 図のようにファイルします。
# cd $HADOOP_PREFIX/etc/hadoop # vi hadoop-env.sh
ファイルの先頭に次の行を入力します。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0/jre export HADOOP_PREFIX=/root/hadoop-2.10.1
9。 次に、core-site.xmlを変更します ファイル。
# cd $HADOOP_PREFIX/etc/hadoop # vi core-site.xml
<configuration>の間に次のように貼り付けます 示されているタグ。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
10。 tecmintの下に以下のディレクトリを作成します NNに使用されるユーザーホームディレクトリ およびDN ストレージ。
# mkdir -p /home/tecmint/hdata/ # mkdir -p /home/tecmint/hdata/data # mkdir -p /home/tecmint/hdata/name
10。 次に、hdfs-site.xmlを変更します ファイル。
# cd $HADOOP_PREFIX/etc/hadoop # vi hdfs-site.xml
<configuration>の間に次のように貼り付けます 示されているタグ。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/tecmint/hdata/name</value>
</property>
<property>
<name>dfs .datanode.data.dir</name>
<value>home/tecmint/hdata/data</value>
</property>
</configuration>
11。 ここでも、mapred-site.xmlを変更します ファイル。
# cd $HADOOP_PREFIX/etc/hadoop # cp mapred-site.xml.template mapred-site.xml # vi mapred-site.xml
<configuration>の間に次のように貼り付けます 示されているタグ。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
12。 最後に、yarn-site.xmlを変更します ファイル。
# cd $HADOOP_PREFIX/etc/hadoop # vi yarn-site.xml
<configuration>の間に次のように貼り付けます 示されているタグ。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
NameNodeを介したHDFSファイルシステムのフォーマット
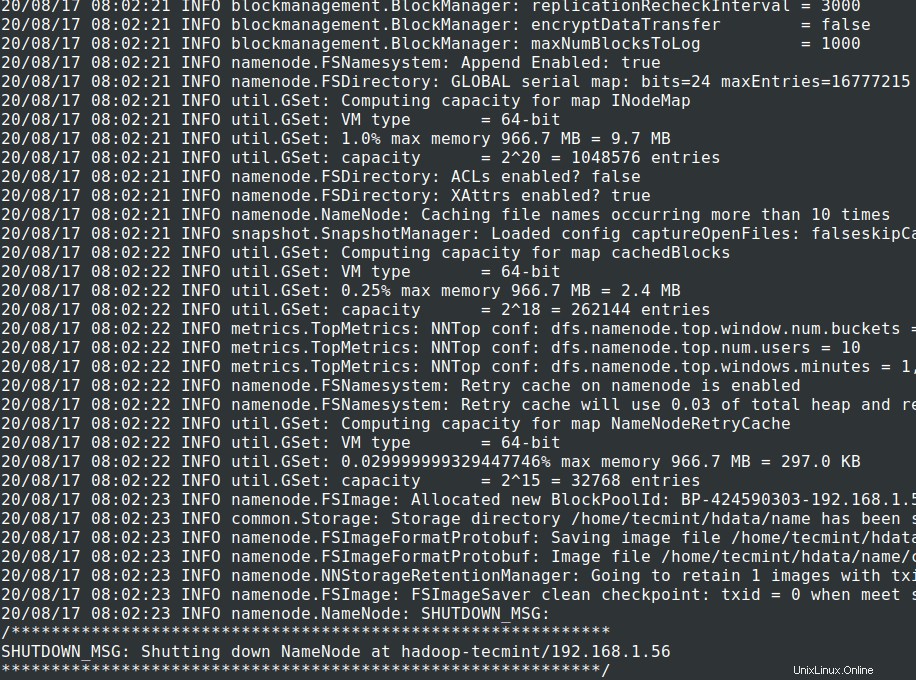
13。 クラスターを開始する前に 、 Hadoop NNをフォーマットする必要があります それがインストールされているローカルシステムで。通常、クラスターを最初に開始する前の初期段階で実行されます。
NNのフォーマット NNメタストアのデータが失われるため、より注意する必要があります。 NNをフォーマットしないでください。 意図的に必要とされない限り、クラスターの実行中。
# cd $HADOOP_PREFIX # bin/hadoop namenode -format
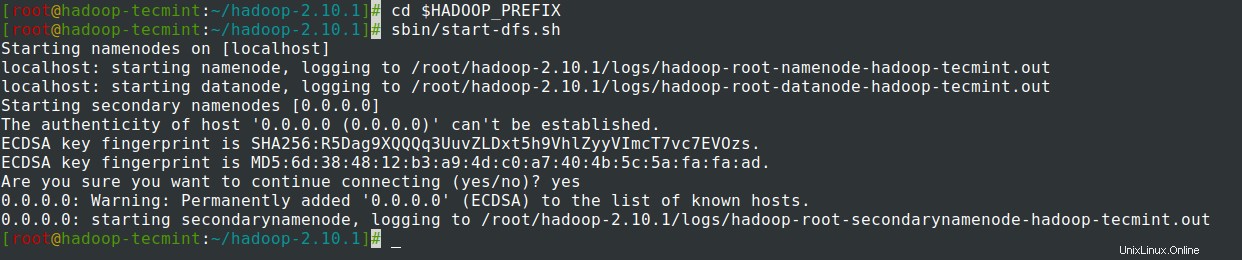
14。 NameNodeを開始します デーモンとDataNode デーモン:(ポート50070 。
# cd $HADOOP_PREFIX # sbin/start-dfs.sh
15。 ResourceManagerを起動します デーモンとNodeManager デーモン:(ポート8088 。
# sbin/start-yarn.sh

16。 すべてのサービスを停止します。
# sbin/stop-dfs.sh # sbin/stop-dfs.sh
概要
まとめ
この記事では、 Hadoop Pseudonodeを設定するための段階的なプロセスを実行しました。 (単一ノード )クラスター 。 Linuxの基本的な知識があり、次の手順に従うと、クラスターは40分で稼働します。
これは、初心者が Hadoopの学習と練習を開始するのに非常に役立ちます。 または、このバニラバージョンの Hadoop 開発目的で使用できます。リアルタイムクラスターが必要な場合は、少なくとも3台の物理サーバーが必要であるか、複数のサーバーを持つためにクラウドをプロビジョニングする必要があります。