glusterfs の高度なノウハウとトラブルシューティングを続ける友人たち。この記事では、glusterfs3.4 で実行されている 3 ノード クラスターを使用しています。以下は、glusterfs のトラブルシューティングに使用される手順です。
ステップ 1 :Gluster ボリュームのステータスと情報を確認してください。

[root@gluster1 ~]# gluster volume info
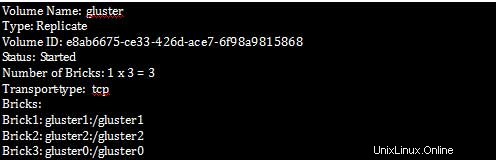
ステップ 2 :Bricks でのレプリケーションのすべての詳細を確認します。
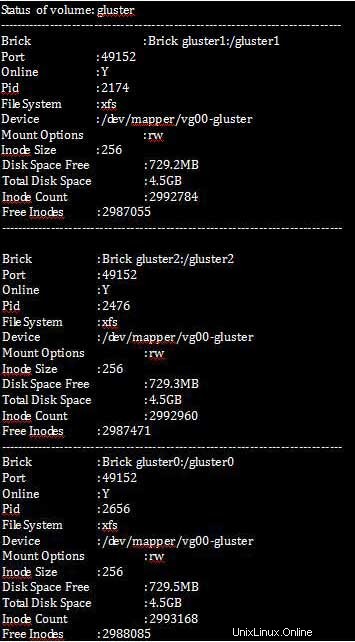
下記のコマンドは、空きディスク容量の合計サイズをチェックすることで、レプリケートされたデータとレプリケートされるデータの量の完全な統計を表示します。
[root@gluster1 ~]# gluster volume status all detail
ステップ 3 :glusterfs のパフォーマンスと修復特性を改善するために、特定の構成が必要です。
# gluster volume set gluster cluster.min-free-disk 5% # gluster volume set cluster.rebalance-stats on # gluster volume set cluster.readdir-optimize on # gluster volume set cluster.background-self-heal-count 20 # gluster volume set cluster.metadata-self-heal on # gluster volume set cluster.data-self-heal on # gluster volume set cluster.entry-self-heal: on # gluster volume set cluster.self-heal-daemon on # gluster volume set cluster.heal-timeout 500 # gluster volume set cluster.self-heal-window-size 2 # gluster volume set cluster.data-self-heal-algorithm diff # gluster volume set cluster.eager-lock on # gluster volume set cluster.quorum-type auto # gluster volume set cluster.self-heal-readdir-size 2KB # gluster volume set network.ping-timeout 5
次に実行します:
# service glusterd restart
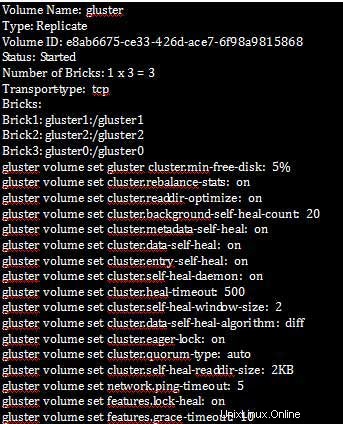
クラスタのプロパティを設定したら、以下に示すようにボリューム情報を確認できます:
[root@gluster1 ~]# gluster volume info
[root@gluster1 ~]# gluster volume status
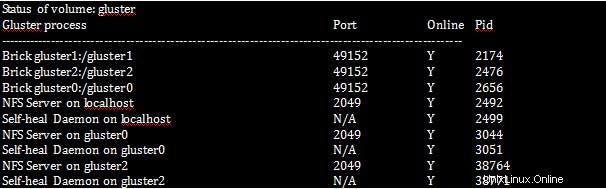
自己修復デーモンは、クラスタの一部のノードがしばらくダウンした場合に修復する責任があるため、クラスタ内の各システムで実行する必要があることに注意してください。
ステップ 4 :クラスターからマシン gluster0 を削除します。
gluster0 マシンにマウントされているボリュームをアンマウントします:
[root@gluster0 ~]# umount /mnt [root@gluster1 ~]# gluster volume remove-brick gluster replica 2 gluster0:/gluster0 commit
gluster ボリューム情報 (検証用):
[root@gluster1 ~]# gluster volume info
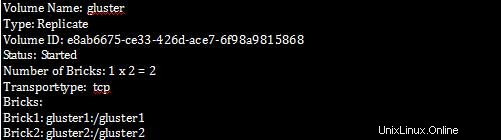
gluster1 で次のコマンドを実行します。
# gluster peer detach gluster0
gluster0 サーバーのブリックがクラスターから削除されます。
CentOS および RHEL での KVM Virsh コマンドの例
Samba、Winbind、および Kerberos を使用して Linux サーバーを Active Directory と統合する