はじめに
MySQL文字列関数を使用すると、ユーザーはデータ文字列を操作したり、 SELECTによって返された文字列に関する情報を照会したりできます。 クエリ。
この記事では、MySQL文字列関数の使用方法を学習します。

前提条件
- MySQLServerとMySQLシェルがインストールされています
- root権限を持つMySQLユーザーアカウント
MySQL文字列関数のチートシート
すべての文字列関数は、以下の記事で説明および例示されています。より便利な場合は、MySQL文字列関数のチートシートをダウンロードをクリックしてチートシートのPDFを保存できます。 リンク。
MySQL文字列関数のチートシートをダウンロード
ASCII()
ASCII()の構文 機能は次のとおりです:
ASCII('str')
ASCII() stringは、指定された str の左端の文字のASCII(数値)値を返します。 ストリング。 str がない場合、関数は0を返します が指定されています。 NULLを返します strの場合 NULLです 。
ASCII()を使用する 0から255までの数値を持つ文字の場合。
例:

この例では、 ASCII() 関数はpの数値を返します 、指定された strの左端の文字 文字列。
BIN()
BIN()の構文 機能は次のとおりです:
BIN(number)
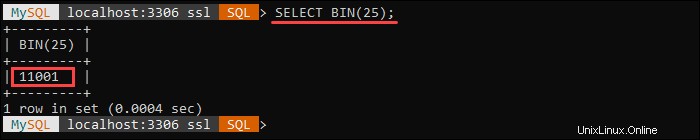
BIN() 関数は、指定された数値のバイナリ値を返します 引数、ここで番号 BIGINTEGERです 番号。 NULLを返します 番号の場合 引数はNULL 。
たとえば、次のクエリは数値25のバイナリ表現を返します。
BIT_LENGTH()
BIT_LENGTH()の構文 機能は次のとおりです:
BIT_LENGTH('str')
この関数は、指定された strの長さを出力します ビット単位の文字列。
たとえば、次のクエリは、指定された'例のビット長を返します。 '文字列:

CHAR()
CHAR()の構文 機能は次のとおりです:
CHAR(number,... [USING charset_name])
CHAR() 指定された各番号を解釈します 引数を整数として、ASCIIテーブルから文字のバイナリ文字列を出力します。この関数はNULLをスキップします 値。
例:

バイナリ以外の出力を生成する場合は、オプションの USINGを使用します 句を指定し、目的の文字セットを指定します。結果の文字列が指定された文字セットに対して不正である場合、MySQLは警告を発行します。
CHAR_LENGTH()、つまりCHARACTER_LENGTH()
CHAR_LENGTHの構文 機能は次のとおりです:
CHAR_LENGTH(str)
この関数は、指定された strの長さを出力します 文字列、文字数で測定。
CHAR_LENGTH() マルチバイト文字を1文字として扱います。つまり、4つの2バイト文字を含む文字列は結果として4を返しますが、 LENGTH() 8を返します。
例:

CHARACTER_LENGTH() CHAR_LENGTH()の同義語です 。
CONCAT()
CONCAT() 関数は、2つ以上の指定された文字列を連結します。構文は次のとおりです。
CONCAT(string1,string2,...)
CONCAT 関数は、連結する前にすべての引数を文字列型に変換します。すべての引数が非バイナリ文字列の場合、結果は非バイナリ文字列になります。一方、バイナリ文字列を連結すると、バイナリ文字列になります。数値引数は、同等の非バイナリ文字列形式に変換されます。
指定された引数のいずれかがNULLの場合 、 CONCAT() NULLを返します 結果として。
例:

この関数は、指定された文字列を1つにまとめます。この場合は、' phoenixNAP '。
CONCAT_WS()
CONCAT_WS()の構文 は:
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() CONCAT()の特殊な形式です これは、2つ以上の式をまとめ、区切り文字を含みます。セパレータは、連結する文字列を分割します。区切り文字がNULLの場合 、結果は NULL 。
例:

この例では、セパレーターは、出力で指定された文字列を区切る空白スペースです。
ELT()
ELT()の構文 機能は次のとおりです:
ELT(N,str1,str2,str3,...)
N 引数は、指定された文字列のどれを結果として返すかを定義します。 ELT() NULLを返します Nの場合 1未満、または指定された文字列の数より大きい。
例:

EXPORT_SET()
EXPORT_SET()の構文 は:
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
EXPORT_SET() 関数はONを返します またはOFF 最初の引数のすべてのビットの文字列。右から左にチェックします。引数は整数ですが、関数はそれをビットに変換します。
ビットが1の場合、関数は ONを返します ストリング。ビットが0の場合、関数は OFFを返します 。 EXPORT_SET() 戻り値の間にセパレータを配置します。デフォルトの区切り文字はコンマですが、4番目の引数として別の区切り文字を指定できます。
文字列は、区切り文字列で区切られて、左から右に出力結果に追加されます。 number_of_bits 引数は、調べるビット数を指定します。
例:

説明:
1.変換後、最初の引数5は00000101を表します。
2.右から左にチェックすると、最初のビットは1であるため、関数は'はいを返します。 '引数( ON ストリング)。 2番目のビットは0であるため、関数は'いいえを返します '(オフ ストリング)。 3番目のビットについては、「はい」を返します。 。」残りのすべてのビット(ゼロ)については、「いいえ」を返します。 。'
3.4番目の引数'- 'は、戻り結果の区切り文字として指定されます。
FIELD()
FIELD()の構文 構文は次のとおりです:
FIELD(str,str1,str2,str3,...)
この関数は、文字列リスト内の文字列のインデックス位置を返します。そのような文字列がない場合、出力は0です。文字列が NULLの場合 、関数は0を返します。 FIELD() 関数は大文字と小文字を区別しません。
例:

この関数は、文字列' fの位置である6を返します。 'リストにあります。
FIND_IN_SET()
FIND_IN_SET()の構文 機能は次のとおりです:
FIND_IN_SET(str,strlist)この関数は、文字列のリスト内の文字列の位置を返します。複数の文字列インスタンスがある場合、出力は指定された文字列の最初の位置のみを返します。
例:

FORMAT()
FORMAT()の構文 機能は次のとおりです:
FORMAT(X,D)
この関数は、指定された数値 Xを出力します '#、###、###。##'のような形式で、指定された小数点以下の桁数に丸められます D 。 D の場合、結果には小数点がありません は0です。
ユーザーは、 Dの後にロケールを指定することもできます 引数。これは出力に影響します。
例:

出力は数値を小数点以下3桁に丸め、ドイツ語ロケールでは。が発生します。 数千を表す記号と、 分数を表す文字。
FROM_BASE64()
FROM_BASE64()の構文 機能は次のとおりです:
FROM_BASE64(str)
この関数は、指定されたbase-64でエンコードされた文字列をデコードし、結果をバイナリ文字列として返します。引数がNULLの場合 または無効なbase-64文字列の場合、結果は NULLになります。 。
FROM_BASE64() TO_BASE64()の逆です TO_BASE64()として クエリをbase64でエンコードします。
例:
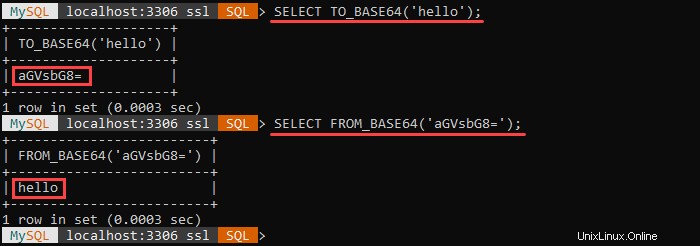
最初のクエリは、指定された文字列をbase64でエンコードします。 2番目のクエリは、base64でエンコードされた文字列をデコードし、元の値を返します。
HEX()
HEX()の構文 機能は次のとおりです:
HEX(N_or_S)
この関数は、指定された Nの16進値の文字列表現を返します。 10進値またはS 文字列値。
引数がstringの場合 、 HEX 各文字を2桁の16進数に変換します。一方、引数が 10進数の場合 、出力は引数の16進文字列表現であり、 BIGINTEGERとして扱われます。 番号。
HEX() 文字列関数は、数学関数 CONV(N、10,16)と同等です。 。
例:

出力は、指定された文字列の16進値を返します。
INSERT()
INSERT()の構文 機能は次のとおりです:
INSERT(str,pos,len,newstr)
この関数は、 newstrを挿入します str内の文字列 文字列とlenを削除します posで始まる元の文字の数 位置。
posの場合 引数が元の文字列の長さ、 INSERT()内にありません 元の文字列を返します。
lenの場合 引数が文字列の残りの長さの範囲内にありません、 INSERT() posの残りの文字列を置き換えます 位置。
引数がNULLの場合 、 INSERT() NULLを返します 。
例:

出力は、元の文字列が5の位置に挿入され、元の文字が削除されていない元の文字列です。
INSTR()
INSTR()の構文 機能は次のとおりです:
INSTR(str,substr)
この関数は、 substrの最初の出現位置を出力します。 元のstrの部分文字列 文字列。
この関数は、 LOCATE()と同じように機能します 、引数の順序が逆になっていることを除いて。
例:

出力は、部分文字列の位置(位置8)を示します。
LEFT()
LEFT()の構文 機能は次のとおりです:
LEFT('str', chars)
この関数は、左端の文字数を出力します chars 指定されたstrから 文字列。
引数がNULLの場合 、出力も NULL 。
例:

LENGTH()、つまりOCTET_LENGTH()
LENGTH()の構文 機能は次のとおりです:
LENGTH(str)
この関数はstrを出力します 文字列の長さ(バイト単位)。マルチバイト文字は複数バイトとしてカウントされます。
例:

OCTET_LENGTH() 関数はLENGTH()の同義語です 。
いいね
LIKEの構文 機能は次のとおりです:
expr LIKE patこの関数は、他の文字列内で指定された文字列パターンを見つけることにより、パターンマッチングを実行します。
LIKE ワイルドカードをサポート:
-
%-ゼロでも、任意の数の文字に一致します。 -
_-正確に1文字に一致します。
LIKE 1(true)または0(false)を返します。 exprの場合 式またはpat パターンはNULL 、出力も NULL 。
例:
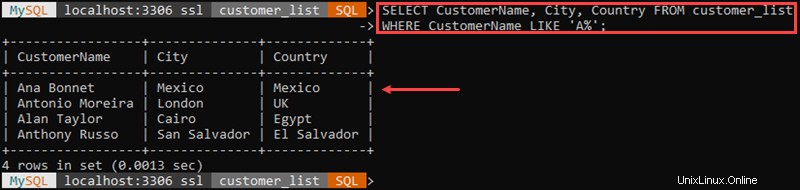
この例では、名前が「 A」で始まるすべての顧客を取得しました。 '。
LOAD_FILE()
LOAD_FILE()の構文 機能は次のとおりです:
LOAD_FILE(file_name)この関数はファイルを読み取り、ファイルの内容を含む文字列を出力します。この機能の前提条件は次のとおりです。
- ファイルをサーバーホストに保持します。
- file_name引数の代わりにフルファイルパスを指定します。
- FILE権限を持っている 。
サーバーはファイルを読み取れる必要があり、そのサイズは max_allowed_packet未満である必要があります バイト。 secure_file_privの場合 システム変数は空でないディレクトリ名です。ファイルをそのディレクトリに配置してください。
上記のいずれかの理由でファイルが存在しないか、関数がファイルを読み取れない場合、出力は NULLになります。 。
例:

LOCATE()、つまりPOSITION()
LOCATE()の構文 機能は次のとおりです:
LOCATE(substring,str,[position])
この関数は、指定された substringの最初の出現位置を出力します。 str内の引数 ストリング。 位置 引数はオプションであり、どの strから指定するために使用されます 検索を開始する文字列の位置。 位置を省略します 引数は最初から検索を開始します。
サブストリングの場合 strにありません 文字列、 LOCATE() 0を返します。引数がNULLの場合 、関数は NULLを返します 。
例:

POSITION(substring IN str) 関数はLOCATE(substr、str)の同義語です 。
LOWER()、つまりLCASE()
LOWER()の構文 機能は次のとおりです:
LOWER(str)
この関数は、指定された strのすべての文字を変更します 文字列を小文字にして結果を出力します。使用するデフォルトの文字セットマッピングはutf8mb4です。 LOWER() マルチバイトセーフです。
例:

LCASE() 関数はLOWER()の同義語です 。
LPAD()
LPAD()の構文 機能は次のとおりです:
LPAD(str,len,padstr)
この関数は、指定された strを出力します 文字列、 padstrが左に埋め込まれます 文字列、長さ len 文字。この関数は、出力を lenに短縮します strの場合は文字 引数がlenより長い 。
LPAD() マルチバイトセーフです。
例:

この例では、 LPAD() 関数は、指定された引数を指定された padstrで左パディングします 、最大10文字。
LTRIM()
LTRIM()の構文 機能は次のとおりです:
LTRIM(str)
この関数は、指定された strを出力します 先頭にスペース文字を含まない文字列。
例:

MAKE_SET()
MAKE_SET()の構文 機能は次のとおりです:
MAKE_SET(bits,str1,str2,...)
この関数は、設定値、つまり、ビットで指定された対応するビットを持つ指定されたサブ文字列を含む文字列を出力します。 引数。
str1 引数はビット0、 str2に対応します ビット1などに対応します。引数のいずれかがNULLの場合 、結果には表示されません。
例:

この例では、最初のビットは1、つまり001です。右端の桁は1であるため、関数は「フェニックス」を返します。 。」 2番目のビットは2、つまり010で、中央の数値は1なので、関数は' NAPを返します。 、'このようにして出力を完了します。
MATCH()
MATCH()の構文 機能は次のとおりです:
MATCH(col1, col2,…) AGAINST(expr[search_modifier])
この関数を使用すると、ユーザーは、コンマで区切られた列のリストを指定することにより、全文検索を実行できます。 expr の代わりに、検索する文字列を入力します 引数。
search_modifier 引数はオプションであり、検索タイプを示します。受け入れられる値は次のとおりです。
自然言語モード(デフォルト)クエリ拡張機能を備えた自然言語モードブールモードクエリ拡張あり
例:
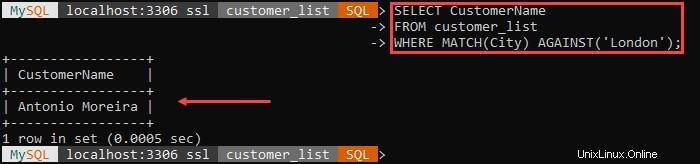
好きではない
NOT LIKEの構文 機能は次のとおりです:
expr NOT LIKE pat [ESCAPE 'escape_char']
好きではない LIKEの否定です 、 LIKEと同じ条件で動作することを意味します 同じワイルドカードを使用します。
例:
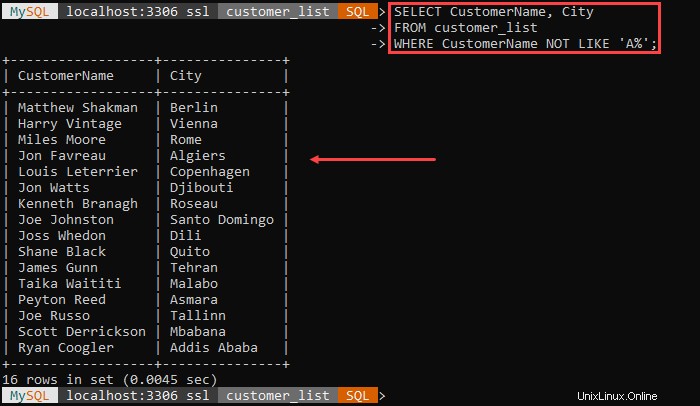
出力には、名前が「 A 」で始まる顧客を除く、すべての顧客とその都市が一覧表示されます。 。'
正規表現ではありません
NOT REGEXPの構文 機能は次のとおりです:
expr NOT REGEXP pat
この関数は、 exprのパターンマッチングを実行します patに対する文字列 パターン。パターンは拡張正規表現にすることができます。
正規表現ではありません REGEXPの否定です 。
exprの場合 引数はpatと一致します 引数の場合、出力は1です。それ以外の場合、出力は0です。いずれかの引数が NULLの場合 、出力は NULL 。
例:
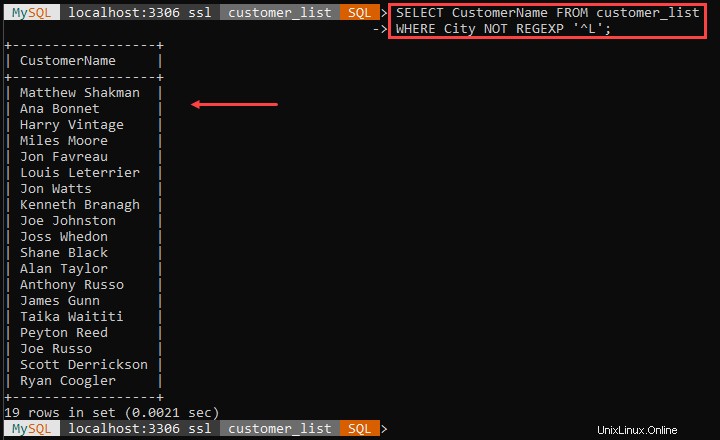
上記の例は、Lで始まる都市に住んでいないすべての顧客を出力します。' ^ '文字は都市名の始まりを示します。
OCT()
OCT()の構文 機能は次のとおりです:
OCT(N)
この関数は、指定された Nの8進値を出力します。 引数、ここで N BIGINTEGERです 番号。 Nの場合 NULLです 、関数は NULLを返します 。
例:

ORD()
ORD()の構文 機能は次のとおりです:
ORD(str)
この関数は、文字列の左端のマルチバイト文字のコードを検索します。左端の文字がマルチバイトでない場合は、 ORD() 文字のASCII値を返します。
この関数は、構成バイトの数値から文字コードを計算します。この操作に使用される式は次のとおりです。
(1バイトコード)+(2バイトコード* 256)+(3バイトコード* 256 ^ 2)...
例:

QUOTE()
QUOTE()の構文 機能は次のとおりです:
QUOTE(str)この関数は、SQLステートメントで使用できる適切にエスケープされたデータ値を表す文字列を出力します。一重引用符で文字列を囲み、円記号( \ )を含めます )バックスラッシュの各インスタンスの前( \ )、一重引用符(' )、 ASCII NUL 、および Control + Z 。
strの場合 引数はNULL 、出力は NULL 。
例:
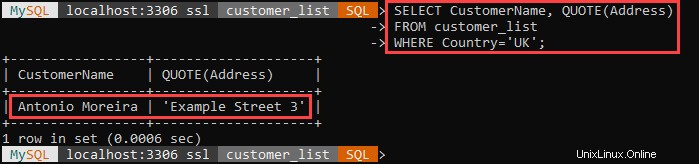
上記の例では、英国に住むすべての顧客を選択し、住所を一重引用符で囲んでいます。
REGEXP_LIKE()、REGEXP、RLIKE
REGEXP_LIKE()の構文 機能は次のとおりです:
REGEXP_LIKE(expr, pat, [match_type])
expr の場合、関数は1を出力します 文字列は、 patの代わりに指定された式と一致します 口論。それ以外の場合、出力は0です。 exprの場合 またはpat 引数はNULL 、出力値は NULLです。 。
match_type 引数はオプションであり、一致するタイプを指定する次のフラグのいずれかまたはすべてを含む可能性のある文字列を表します。
- 大文字と小文字を区別するマッチング (
c)。いずれかの引数がバイナリ文字列の場合は、大文字と小文字を区別して引数をバイナリ文字列として処理します。cフラグは、iであっても、大文字と小文字の区別が採用されることを意味します フラグも指定されています。 - 大文字と小文字を区別しないマッチング (
i)。大文字と小文字を区別せずに引数を処理します。 - 複数行モード (
m)。文字列内の行末記号を認識します。デフォルト設定では、文字列式の開始と終了でのみ行末記号が一致します。 - 。文字がラインターミネータと一致する (
n)。 を変更するために使用されます。 (ドット)ラインターミネータに一致する文字。デフォルトでは、。 マッチングは行末で停止します。 - Unixのみの行末 (
u)。 。、^、および$一致演算子によって改行文字のみを認識するUnixのみの行末。
match_type内で矛盾するフラグが指定されている場合 、右端のものが優先されます。
REGEXP およびRLIKE REGEXP_LIKE()の同義語です 。
例:

この例では、正規表現でドットの代わりに任意の文字を指定できるため、関数は1を出力して一致を示します。
REGEXP_INSTR()
REGEXP_INSTR()の構文 機能は次のとおりです:
REGEXP_INSTR(expr, pat[, pos[, occurrence[, return_option[, match_type]]]])
この関数は、 exprに一致する部分文字列の開始インデックスを出力します 式のパット パターン。一致するものがない場合、出力は0です。いずれかの引数が NULLの場合 、出力は NULL 。文字インデックスは1から始まります。
オプションの引数は次のとおりです。
-
pos-exprで位置を指定します 検索を開始する場所。省略した場合、デフォルトは1です。 発生-検索する一致の発生を指定します。省略した場合、デフォルトは1です。-
return_option-どのポジションタイプを返すか。 0に設定すると、REGEXP_INSTR()一致した部分文字列の最初の文字位置を返します。 1に設定されている場合、REGEXP_INSTR()一致した部分文字列に続く位置を返します。省略した場合、デフォルトは0です。 -
match_type-照合方法を指定します。引数はREGEXP_LIKE()と同じです 同じフラグを取ります。
例:

この例では、一致があり、部分文字列は位置1から始まります。
REGEXP_REPLACE()
REGEXP_REPLACE()の構文 機能は次のとおりです:
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
この関数は、 expr内のすべての出現箇所を置き換えます patで指定された文字列 replのパターン 文字列、および結果の文字列を出力します。一致するものがある場合、出力は文字列全体に置換が含まれます。一致するものがない場合、出力は元の exprです。 ストリング。引数がNULLの場合 、出力は NULL 。
オプションのREGEXP_REPLACE() 引数は次のとおりです:
-
pos-exprでの位置 検索を開始する場所。省略した場合、デフォルトは1です。 発生-置換する一致オカレンス。省略した場合、デフォルトは0であり、すべてのオカレンスを置き換えます。-
match_type-照合方法を指定します。引数はREGEXP_LIKE()と同じです 同じフラグを取ります。
例:

REGEXP_SUBSTR()
REGEXP_SUBSTR()の構文 機能は次のとおりです:
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
この関数は、 exprのサブストリングを出力します patで指定された正規表現に一致する文字列 パターン。一致するものがない場合、結果は NULLになります。 。引数がNULLの場合 、出力は NULL 。
オプションの引数は次のとおりです。
-
pos-exprでの位置 検索を開始する場所。省略した場合、デフォルトは1です。 発生-置換する一致オカレンス。省略した場合、デフォルトは1です。-
match_type-照合方法を指定します。引数はREGEXP_LIKE()と同じです 同じフラグを取ります。
例:

この例では、結果は指定された exprから一致する部分文字列を出力します 文字列。
REPEAT()
REPEAT()の構文 機能は次のとおりです:
REPEAT(str,count)
この関数は、 strを繰り返す文字列を出力します 文字列count 回数。 カウントの場合 引数が1未満の場合、関数は空の文字列を出力します。いずれかの引数がNULLの場合 、結果は NULL 。
例:

上記の例では、関数は'作業で構成される文字列を出力します '文字列が6回繰り返されました。
REPLACE()
REPLACE()の構文 機能は次のとおりです:
REPLACE(str,from_str,to_str)
この関数は、 from_strのすべてのインスタンスを置き換えます str内 指定されたto_strの文字列 ストリング。この関数は大文字と小文字を区別し、マルチバイトセーフです。
例:

REVERSE()
REVERSE()の構文 機能は次のとおりです:
REVERSE(str)
この関数はstrを出力します 文字の順序が逆の文字列。 REVERSE() マルチバイトセーフ関数です。
例:

RIGHT()
RIGHT()の構文 機能は次のとおりです:
RIGHT(str,len)
この関数は、右端の lenを出力します strの文字数 ストリング。引数がNULLの場合 、結果は NULL 。 RIGHT() マルチバイトセーフ関数です。
例:

RPAD()
RPAD()の構文 機能は次のとおりです:
RPAD(str,len,padstr)
この関数は、指定された strを出力します 文字列、 padstrで右埋め込み 文字列、長さ len 文字。 str 引数がlenより長い 出力をlenに短縮します 文字。
RPAD() マルチバイトセーフです。
例:

RTRIM()
RTRIM()の構文 機能は次のとおりです:
RTRIM(str)
この関数はstrを出力します 末尾のスペース文字を含まない文字列。 RTRIM() 関数はマルチバイトセーフです。
例:

SOUNDEX()、つまりSOUNDS LIKE
SOUNDEX()の構文 機能は次のとおりです:
SOUNDEX(str)
この関数は、soundex文字列、つまり入力 strの音声表現を出力します。 ストリング。 SOUNDEX() この関数を使用すると、ユーザーは、綴りが異なるが音が似ている英語の単語を比較できます。
SOUNDEX() ignores all non-alphabetic characters in the input string and treats all characters outside the A-Z range as vowels.
重要: The SOUNDEX() function works well only with strings in English. Results are unreliable for strings in other languages and for strings that use multibyte character sets, including utf-8.
例:

The (expr1) SOUNDS LIKE (expr2) function is the same as SOUNDEX(expr1) =SOUNDEX(expr2) 。
SPACE()
The syntax for the SPACE() function is:
SPACE(N)
The function outputs a string consisting of N number of space characters.
例:

STRCMP()
The syntax for the STRCMP() function is:
STRCMP(expr1,expr2)The function compares the two expressions and outputs:
-
0- If the two expressions are the same. -1- If the first expression is smaller than the second depending on the current sort order.-
1- If the second expression is smaller than the first one.
例:

In this example, the output is 1 because the second argument is smaller than the first one.
SUBSTRING(), i.e., SUBSTR(), MID()
The syntax for the SUBSTRING() function is:
SUBSTRING(str, pos, length)または:
SUBSTRING(str FROM pos FOR length)The function extracts a substring from a string, starting at a specified position.
The length argument is optional and used to return a substring length characters long from the str string, starting at pos 位置。
The pos argument specifies from which position to extract the substring. If pos is a positive number, the function extracts a substring from the beginning of the string. If pos is a negative number, the function extracts a substring from the end of the string.
例:

MID(str,pos,length) and SUBSTR() are synonyms for SUBSTRING(str,pos,length) 。
SUBSTRING_INDEX()
The syntax for the SUBSTRING_INDEX() function is:
SUBSTRING_INDEX(str,delim,count)
The function outputs a substring from the str string before a specified count number of delim delimiter occurs.
If the count argument is positive, the function outputs everything left of the final delimiter, counting from the left side.
If the count argument is negative, the function outputs everything right of the final delimiter, counting from the right side.
SUBSTRING_INDEX() searches for the delimiter in a case-sensitive fashion, and it is multibyte safe.
例:
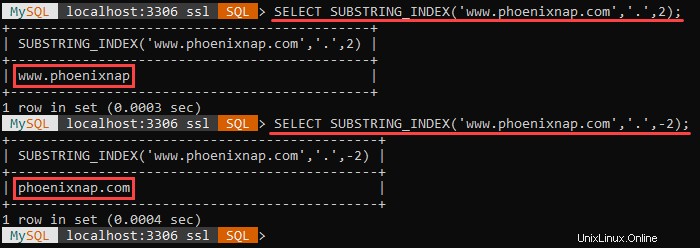
The example above shows the different outputs when the count argument is positive and negative.
TO_BASE64()
The syntax for the TO_BASE64() function is:
TO_BASE64(str)The function encodes a string argument to a base-64 encoded form and returns the result. If the argument isn't a string, the function converts it to a string before base-64 encoding.
If the argument is NULL , the result is NULL 。
TO_BASE64() is the reverse of FROM_BASE64() 。
例:

The output is a base-64 encoded string.
TRIM()
The syntax for the TRIM() function is:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
The function removes all remstr prefixes and suffixes from the specified str string and outputs the result.
Unless specifying the BOTH, LEADING ,or TRAILING specifiers, the function assumes BOTH 。
The remstr argument is optional, and omitting it removes the space characters from the string.
TRIM() is multibyte safe.
例:

In this example, the function removes the specified leading prefix from the string.
UPPER(), i.e., UCASE()
The syntax for the UPPER() function is:
UPPER(str)
The function changes all characters of the specified str string to uppercase and outputs the result. The default character set mapping it uses is utf8mb4. UPPER() is multibyte safe.
例:

The UCASE() function is a synonym for UPPER() 。
UNHEX()
The syntax for the UNHEX() function is:
UNHEX(str)The function interprets each pair of characters in a string argument as a hexadecimal number and converts it to the byte represented by the number. The output is a binary result.
If the str argument contains non-hexadecimal digits, the output is NULL 。 A NULL output can also occur if the argument is a BINARY 列。
UNHEX() is the opposite of HEX() 。 However, you shouldn't use UNHEX() to inverse the HEX() result of numeric arguments. Instead, use the mathematical function CONV(HEX(N),16,10) 。
例:

WEIGHT_STRING()
The syntax for the WEIGHT_STRING() function is:
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])str- The input string argument.AS- Optional clause, permits casting the input string to a binary or non-binary string, and to a specific length.flags- Optional argument, currently unused.
The function outputs the weight string for the input str string. The output value represents the string's sorting and comparison value.
If used, the AS BINARY(N) argument measures the length in bytes rather than characters, and right-pads with 0x00 bytes to the specified length.
On the other hand, the AS CHAR(N) argument measures the characters' length and right-pads with spaces to the specified length.
N has a minimum value of 1. If N is less than the input string length, the string is truncated without issuing a warning.
If the input string is a non-binary value (CHAR , VARCHAR , or TEXT ) , the output contains the collation weights for the string. If the input string is a binary value (BINARY , VARBINARY , or BLOB ), the output is the same as the input string because the weight for each byte in a binary string is the byte value.
If the input string is NULL , the output is NULL 。
Important:WEIGHT_STRING() is a debugging function intended for internal use and collation testing and debugging. Its behavior is subject to change between different MySQL versions.
例:

In this example, we used HEX() to display the output because HEX() can display binary results containing nonprinting values in a printable form.