
このチュートリアルでは、Debian11にApacheHadoopをインストールする方法を紹介します。知らない人のために、ApacheHadoopはオープンソースのJavaベースのソフトウェアプラットフォームです。ビッグデータアプリケーションのデータ処理とストレージを管理します。単一のサーバーから数千台のマシンにスケールアップするように設計されており、それぞれがローカルの計算とストレージを提供します。
この記事は、少なくともLinuxの基本的な知識があり、シェルの使用方法を知っていること、そして最も重要なこととして、サイトを独自のVPSでホストしていることを前提としています。インストールは非常に簡単で、ルートアカウントで実行されていますが、そうでない場合は、'sudoを追加する必要があります。 ルート権限を取得するコマンドに‘。 Debian 11(Bullseye)にApacheHadoopを段階的にインストールする方法を紹介します。
前提条件
- 次のオペレーティングシステムのいずれかを実行しているサーバー:Debian 11(Bullseye)。
- 潜在的な問題を防ぐために、OSの新規インストールを使用することをお勧めします。
- サーバーへのSSHアクセス(またはデスクトップを使用している場合はターミナルを開く)
non-root sudo userまたはroot userへのアクセス 。non-root sudo userとして行動することをお勧めします ただし、ルートとして機能するときに注意しないと、システムに害を及ぼす可能性があるためです。
Debian11BullseyeにApacheHadoopをインストールする
ステップ1.ソフトウェアをインストールする前に、次のaptを実行して、システムが最新であることを確認することが重要です。 ターミナルのコマンド:
sudo apt update sudo apt upgrade
ステップ2.Javaをインストールします。
Apache HadoopはJavaベースのアプリケーションです。したがって、システムにJavaをインストールする必要があります:
sudo apt install default-jdk default-jre
Javaのインストールを確認します:
java -version
ステップ3.Hadoopユーザーを作成します。
次のコマンドを実行して、Hadoopという名前の新しいユーザーを作成します。
adduser hadoop
次に、ユーザーが作成されたら、Hadoopユーザーに切り替えます。
su - hadoop
Hadoopはノード、リモート、またはローカルマシンを管理するためにsshアクセスを必要とするため、sshキーを生成します。Hadoopのセットアップの単一ノードに対して構成します。ローカルホストにアクセスできるようにします:
ssh-keygen -t rsa
その後、authorized_keysファイルに権限を付与します:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
次に、次のコマンドを使用してパスワードなしのSSH接続を確認します。
ssh your-server-IP-address
ステップ4.Debian11にApacheHadoopをインストールします。
まず、Hadoopユーザーに切り替え、次のwgetを使用して、公式ページから最新バージョンのHadoopをダウンロードします。 コマンド:
su - hadoop wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz
次に、次のコマンドを使用して、ダウンロードしたファイルを抽出します。
tar -xvzf hadoop-3.3.1.tar.gz
解凍したら、現在のディレクトリをHadoopフォルダに変更します:
su root cd /home/hadoop mv hadoop-3.3.1 /usr/local/hadoop
次に、次のコマンドを使用して、ログを保存するディレクトリを作成します。
mkdir /usr/local/hadoop/logs
Hadoopディレクトリの所有権をHadoopに変更します:
chown -R hadoop:hadoop /usr/local/hadoop su hadoop
その後、Hadoop環境変数を構成します:
nano ~/.bashrc
次の構成を追加します:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
ファイルを保存して閉じます。次に、環境変数をアクティブにします:
source ~/.bashrc
ステップ5.ApacheHadoopを構成します。
- Java環境変数の構成:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
次の構成を追加します:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
次に、Javaxアクティベーションファイルをダウンロードする必要があります:
cd /usr/local/hadoop/lib sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Apache Hadoopのバージョンを確認します:
hadoop version
出力:
Hadoop 3.3.1
- core-site.xmlファイルを構成します:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
次のファイルを追加します:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration> - hdfs-site.xmlファイルを構成します:
構成する前に、ノードメタデータを保存するためのディレクトリを作成します:
mkdir -p /home/hadoop/hdfs/{namenode,datanode}
chown -R hadoop:hadoop /home/hadoop/hdfs 次に、hdfs-site.xmlを編集します ファイルを作成し、ディレクトリの場所を定義します:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
次の行を追加します:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration> - mapred-site.xmlファイルを構成します:
次に、mapred-site.xmlを編集します。 ファイル:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
次の構成を追加します:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> - yarn-site.xmlファイルを構成します:
yarn-site.xmlを編集する必要があります ファイルを作成し、YARN関連の設定を定義します:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
次の構成を追加します:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> - HDFSNameNodeをフォーマットします。
次のコマンドを実行して、HadoopNamenodeをフォーマットします。
hdfs namenode -format
- Hadoopクラスターを起動します。
次に、以下のコマンドを使用してNameNodeとDataNodeを起動します。
start-dfs.sh
次に、YARNリソースとノードマネージャーを起動します:
start-yarn.sh
次のコマンドで確認できるようになりました:
jps
出力:
hadoop@idroot.us:~$ jps 58000 NameNode 54697 DataNode 55365 ResourceManager 55083 SecondaryNameNode 58556 Jps 55365 NodeManager
ステップ6.HadoopWebインターフェースへのアクセス。
正常にインストールされたら、Webブラウザーを開き、URL http://your-server-ip-address:9870を使用してApacheHadoopにアクセスします。 。 Hadoop Webインターフェースにリダイレクトされます:
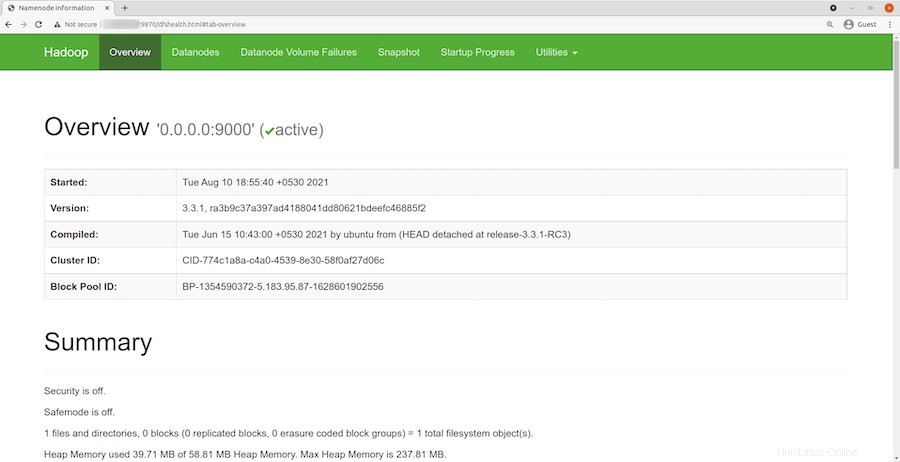
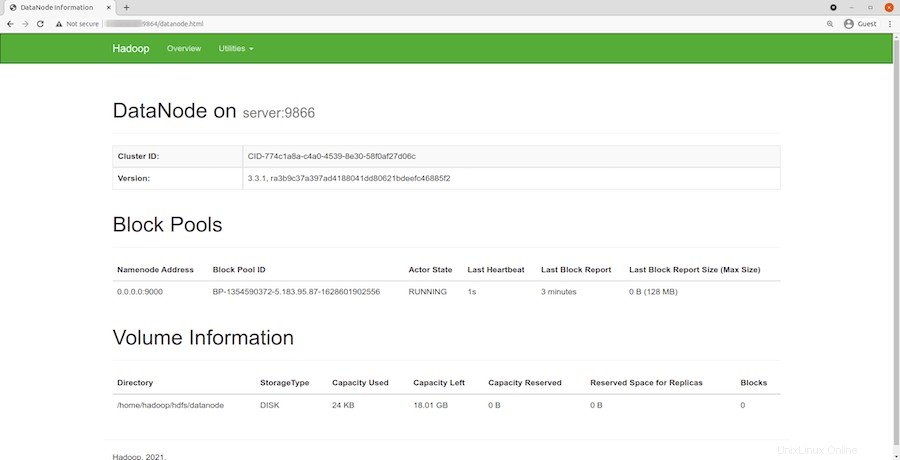
ローカルホストのURLまたはIPをナビゲートして、個々のデータノードにアクセスします:http://your-server-ip-address:9864
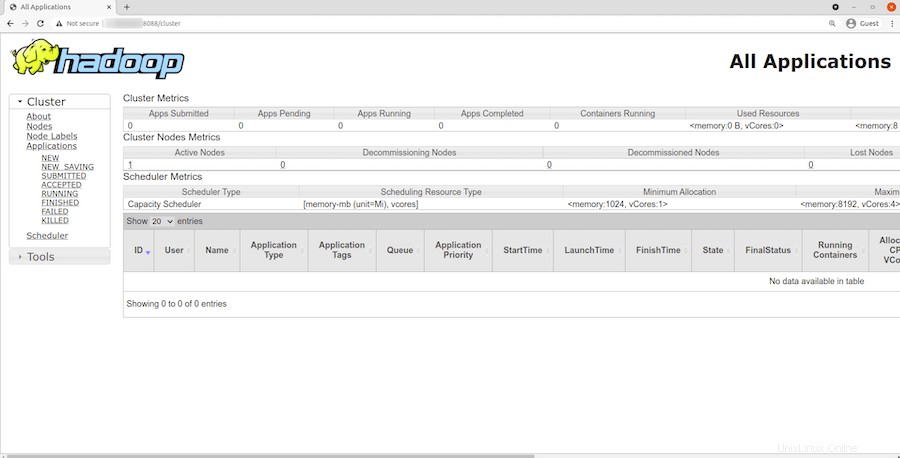
YARNリソースマネージャーにアクセスするには、URL http://your-server-ip-adddress:8088を使用します 。次の画面が表示されます。
おめでとうございます!Hadoopが正常にインストールされました。Debian11Bullseyeに最新バージョンのApache Hadoopをインストールするためにこのチュートリアルを使用していただき、ありがとうございます。追加のヘルプや役立つ情報については、公式のApacheを確認することをお勧めします。ウェブサイト。