ここでは、Ubuntu20.04または18.04にApacheSparkをインストールする方法を説明します。コマンドは、Linux Mint、Debian、およびその他の同様のLinuxシステムに適用できます。
Apache Sparkは、データ処理エンジンと呼ばれる汎用のデータ処理ツールです。データエンジニアやデータサイエンティストが、テラバイト範囲の大量のデータに対して非常に高速なデータクエリを実行するために使用します。これは、クラスターベースの計算のフレームワークであり、クラスターで使用可能なRAMを使用して、従来のHadoop Map / Reduceと競合し、ジョブの実行を高速化します。
さらに、Sparkは、SQLを介してデータを制御し、(ほぼ)リアルタイムでストリーミングしてデータを処理するオプションを提供し、独自のグラフデータベースと機械学習ライブラリを提供します。このフレームワークは、この目的のためにメモリ内テクノロジーを提供します。つまり、クエリとデータをクラスタノードのメインメモリに直接保存できます。
Apache Sparkは、大量のデータを迅速に処理するのに理想的です。 Sparkのプログラミングモデルは、クラスター内で分散して動作するコレクションクラスであるResilient Distributed Datasets(RDD)に基づいています。このオープンソースプラットフォームは、Java、Scala、Python、Rなどのさまざまなプログラミング言語をサポートしています。
Ubuntu20.04にApacheSparkをインストールする手順
ここに記載されている手順は、Linux Mint、Debian、および同様のLinuxを含む、21.04/18.04などの他のUbuntuバージョンで使用できます。
1。他の依存関係でJavaをインストールする
ここでは、Apache Sparkの要件である最新の利用可能なバージョンのJaveを、その機能を拡張するためのGitとScalaなどの他のものとともにインストールしています。
sudo apt install default-jdk scala git
2。 Ubuntu20.04にApacheSparkをダウンロード
次に、Sparkの公式Webサイトにアクセスして、入手可能な最新バージョンをダウンロードします。ただし、このチュートリアルを書いている間、最新バージョンは3.1.2でした。したがって、ここでは同じものをダウンロードしています。UbuntuシステムでSparkのインストールを実行しているときに異なる場合は、それを実行してください。このツールのダウンロードリンクをコピーして、wgetで使用するだけです。 または、システムに直接ダウンロードします。
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3。 Sparkを/opt
に抽出します抽出したフォルダを誤って削除しないように、安全な場所、つまり / optに配置しましょう。 ディレクトリ。
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
また、Sparkがフォルダ内に書き込めるように、フォルダの権限を変更してください。
sudo chmod -R 777 /opt/spark
4。 Sparkフォルダをシステムパスに追加します
ここで、ファイルを / optに移動しました。 ディレクトリ、ターミナルでSparkコマンドを実行するには、そのパス全体を毎回言及する必要があります。これは煩わしいことです。これを解決するために、Sparkの環境変数を構成します そのホームパスをシステムのprofile/bashrcファイルに追加します。これにより、どのディレクトリにいるかに関係なく、ターミナルのどこからでもコマンドを実行できます。
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
シェルのリロード:
source ~/.bashrc
5。 UbuntuでApacheSparkマスターサーバーを起動します
Sparkの可変環境はすでに構成されているので、スクリプトを実行してスタンドアロンのマスターサーバーを起動しましょう。
start-master.sh
Spark Master Web UIとリッスンポートを変更します(オプション、必要な場合にのみ使用)
カスタムポートを使用する場合は、以下に示すオプションまたは引数を使用できます。
–ポート –リッスンするサービスのポート(デフォルト:マスターの場合は7077、ワーカーの場合はランダム)
–webui-port – Web UIのポート(デフォルト:マスターの場合は8080、ワーカーの場合は8081)
例 –8082でSparkWeb UIを実行し、ポート7072をリッスンさせたい場合、起動するコマンドは次のようになります。
start-master.sh --port 7072 --webui-port 8082
6。 Spark Masterにアクセス(spark:// Ubuntu:7077)–Webインターフェイス
それでは、ポート番号 8080で実行されているSparkマスターサーバーのWebインターフェイスにアクセスしてみましょう。 。したがって、ブラウザでhttp://127.0.0.1:8080を開きます。 。
私たちのマスターはspark:// Ubuntuで実行されています :7077、ここで Ubuntu システムのホスト名です 場合によっては異なる可能性があります。
CLIサーバーを使用していて、サーバーのIPアドレスにアクセスできる他のシステムのブラウザーを使用する場合は、最初に 8080を開きます。 ファイアウォールで。これにより、Spark Webインターフェイスにリモートでアクセスできるようになります– http://your-server-ip-addres:8080
sudo ufw allow 8080
7。スレーブワーカースクリプトを実行する
Sparkスレーブワーカーを実行するには、 / optにコピーしたディレクトリで利用可能なスクリプトを開始する必要があります。 。コマンド構文は次のようになります:
コマンド構文:
start-worker.sh spark://hostname:port
上記のコマンドで、ホスト名を変更します およびポート 。ホスト名がわからない場合は、「hostname」と入力するだけです。 ターミナルで。 マスターのデフォルトポート 実行中は7077、上のスクリーンショットで確認できます 。
したがって、ホスト名はubuntuであるため、コマンドは次のようになります。
start-worker.sh spark://ubuntu:7077
Webインターフェイスを更新します ワーカーIDが表示されます とメモリの量 それに割り当てられた:
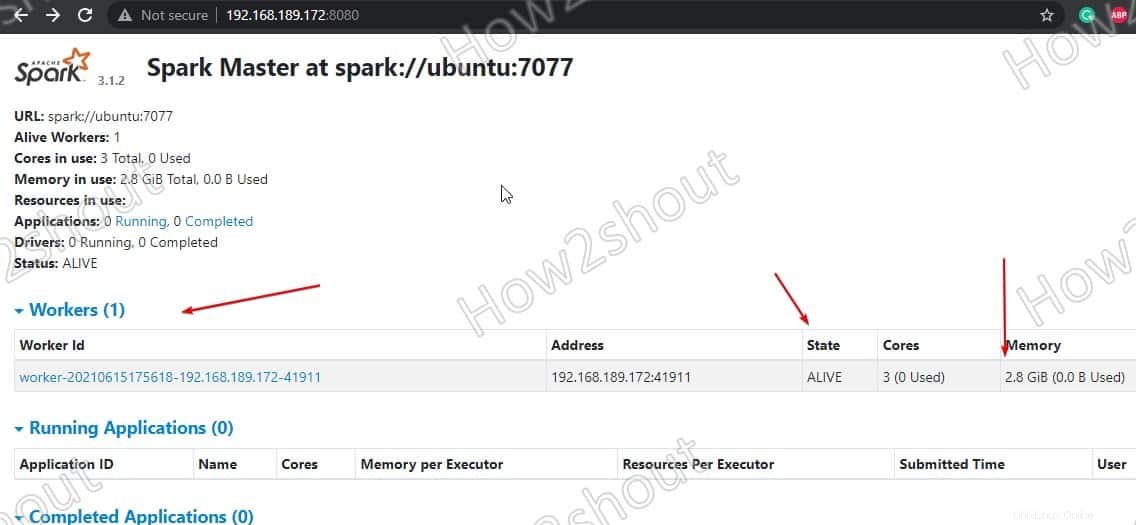
必要に応じて、ワーカーに割り当てられているメモリ/RAMを変更できます。そのためには、提供したいRAMの量でワーカーを再起動する必要があります。
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
SparkShellを使用する
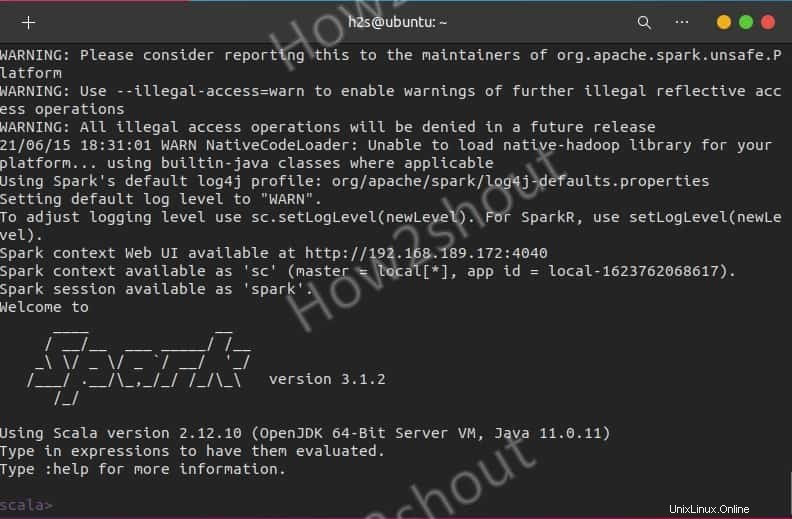
Sparkシェルを使用してプログラミングを開始したい場合は、次のように直接入力してアクセスできます。
spark-shell
サポートされているオプションを確認するには、次のように入力します-:help シェルの使用を終了するには– :quite
ScalaではなくPythonシェルから始めるには、次を使用します:
pyspark
サーバーの開始コマンドと停止コマンド
マスター/ワーカーを開始または停止する場合 インスタンスの場合は、対応するスクリプトを使用します:
stop-master.sh stop-worker.sh
一度に停止するには
stop-all.sh
または一度に開始する:
start-all.sh
最後の考え:
このようにして、UbuntuLinuxにApacheSparkをインストールして使用を開始できます。詳細については、公式ドキュメントを参照してください。 。ただし、Hadoopと比較すると、Sparkはまだ比較的若いため、いくつかのラフなエッジを考慮する必要があります。ただし、実際にはすでに何度も証明されており、ジョブの高速実行とデータのキャッシュを通じて、ビッグデータまたは高速データの分野で新しいユースケースを可能にします。そして最後に、Hadoop環境で個別に操作および操作する必要があるツール用の統一されたAPIを提供します。