リレーショナルデータベースに適さないデータがある場合は、NoSQLソリューションを探している可能性があります。 NoSQLオプションは多様であり、Aerospike、MongoDB、Redisなど、さまざまな方法でビッグデータの問題を解決しようとしています。この記事では、cassandraを使用したレプリケーションに焦点を当てます。このデータベースは実際にはギリシャ神話にちなんで名付けられました。カサンドラは常に未来を正しく予測した予言者でしたが、誰もが彼女を信じていませんでした。したがって、このデータベースの作成者は、NoSQLが将来リレーショナルデータベースに取って代わると予測していますが、RDBMSの人々がそれらを信じることを期待していません。
要件
この記事に従うには、以前のcassandraセットアップガイドを使用して、3つのノードを1つずつセットアップする必要があります。 3つのノードすべてが稼働していて、それぞれにsshセッションがある3つのターミナルウィンドウが必要です。その後、Cassandraノードを1つのクラスターに接続し始めます。
クラスターの構築
Cassandraユーザーとしてログインすると、3つのノードのそれぞれでCassandra構成を編集する必要があります。このファイルの名前はcassandra.yaml
です。nano ~/conf/cassandra.yamlこれは、3台のサーバーすべてで構成する必要があります。シード行は1つのサーバーに入力してからコピーできますが、各サーバーのIPアドレスは本物で入力する必要があります。
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "your-server-ip,your-server-ip-2,your-server-ip-3"
listen_address: your-server-ip
rpc_address: your-server-ipエントポイントスニッチを設定するには、このワンライナーを3つのノードすべてに貼り付けます。
sed -i 's/endpoint_snitch: SimpleSnitch/endpoint_snitch: GossipingPropertyFileSnitch/g' ~/conf/cassandra.yamlそして、このコマンドを使用して、ファイルの最後にブートストラップ行を追加します。
echo 'auto_bootstrap: false' >> ~/conf/cassandra.yamlセットアップしたスニッチのデータセンター名は互換性がなく、datacenter1ではなくdc1であるため、3つのノードすべてで修正しましょう。
sed -i 's/dc=dc1/dc=datacenter1/g' ~/conf/cassandra-rackdc.properties必要に応じて3つのノードすべてを再起動すると、その後、sh bin/nodetoolステータスで次のようになります。
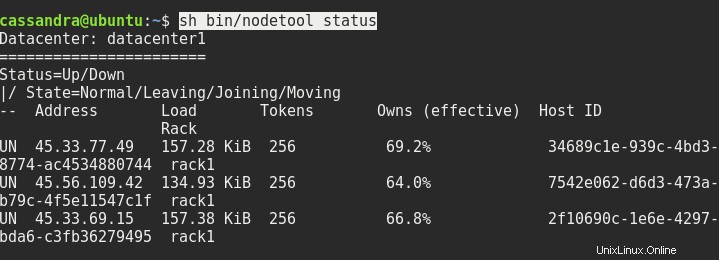
次に行う必要があるのは、一方のノードからもう一方のノードにコンソールに接続することです。次のように、cqlshの後にサーバーのアドレスとポート9042を入力する必要があります。
cqlsh ip.addr.of.node 9042cqlshのみを使用したローカルホストログインは機能しません。
レプリケーションの設定
なぜデフォルトのスニッチ構成を変更したのか疑問に思われる場合は、ここで説明します。 Cassandraには一般に2つのレプリケーション戦略があります。 SimpleStrategyおよびNetworkTopologyStrategy。最初はデフォルトのスニッチを使用し、2番目は設定したスニッチを使用します。クラスターのスケーリングを容易にする場合は、この高度な戦略が必要です。この戦略を使用すると、別のデータセンターにノードを追加して、世界中のクラスターにまたがることができます。
したがって、cqlshコンソール内で次のように入力する必要があります:
CREATE KEYSPACE linoxide WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};NetworkTopologyStrategyでレプリカが設定されたlinoxideという名前の新しいキースペースが作成され、datacenter1に3つのレプリカが作成されます。
では、作成したものを見てみましょう。コマンドは太字で、残りは出力されます。
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | replication
--------------------+----------------+---------------------------------------------------------------------------------------
linoxide | True | {'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy', 'datacenter1': '3'}
system_auth | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'}
system_schema | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_distributed | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'}
system | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_traces | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'}cqlshを終了し、nodetoolコマンドをもう一度発行して、クラスターの変化を確認します。
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 45.33.77.49 250.7 KiB 256 100.0% 34689c1e-939c-4bd3-8774-ac4534880744 rack1
UN 45.56.109.42 188.02 KiB 256 100.0% 7542e062-d6d3-473a-b79c-4f5e11547c1f rack1
UN 45.33.69.15 236.58 KiB 256 100.0% 2f10690c-1e6e-4297-bda6-c3fb36279495 rack1すべてのノードに100%のデータがあり、以前の66%から増加していることに注意してください。これは、設定したレプリケーション係数3によるもので、各ノードにデータのコピーが1つあります。
結論
そこで、レプリケーションを使用してCassandraクラスターをセットアップしました。ここから、ノード、ラック、データセンターを追加したり、任意の量のデータをインポートしたり、すべてまたは一部のデータセンターのレプリケーション係数を変更したりできます。これを行う方法については、Cassandraの公式ドキュメントを参照してください。このガイドがデータベーステクノロジーの未来に飛び込むのに役立ち、Cassandraを信じることにしたことを願っています。読んでいただきありがとうございます。良い一日を。