Scrapyは、Webサイトからデータを抽出するために使用されるオープンソースソフトウェアです。 ScrapyフレームワークはPythonで開発されており、クロールジョブを高速でシンプルかつ拡張可能な方法で実行します。仮想ボックスに仮想マシン(VM)を作成し、Ubuntu14.04LTSをインストールしました。
Scrapyのインストール
Scrapyは、Python、開発ライブラリ、pipソフトウェアに依存しています。 Pythonの最新バージョンはUbuntuにプリインストールされています。そのため、Scrapyをインストールする前に、pipおよびpython開発者ライブラリをインストールする必要があります。
Pipは、pythonpackageindexerのeasy_installに代わるものです。 Pythonパッケージのインストールと管理に使用されます。
pipパッケージをインストールするには、次を実行します:
$ sudo apt-get install python-pip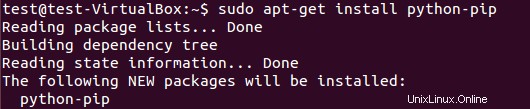
次のコマンドを使用して、Python開発ライブラリをインストールする必要があります。このパッケージがインストールされていない場合、scrapyフレームワークをインストールすると、python.hヘッダーファイルに関するエラーが発生します。
$ sudo apt-get install python-dev
Scrapyフレームワークは、debパッケージまたはソースコードからインストールできます。ただし、pip(Pythonパッケージマネージャー)を使用してdebパッケージをインストールしました。
$ sudo pip install scrapy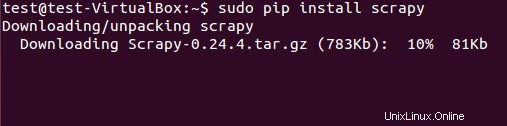
Scrapyの正常なインストールには時間がかかります。

Scrapyフレームワークを使用したデータ抽出
(基本チュートリアル)
fatwallet.com Webサイトからストア名(カードを提供している)アイテムを抽出するためにScrapyを使用します。まず、次のコマンドを使用して、新しいScrapyプロジェクト「store_name」を作成しました。
$ sudo scrapy startproject store_name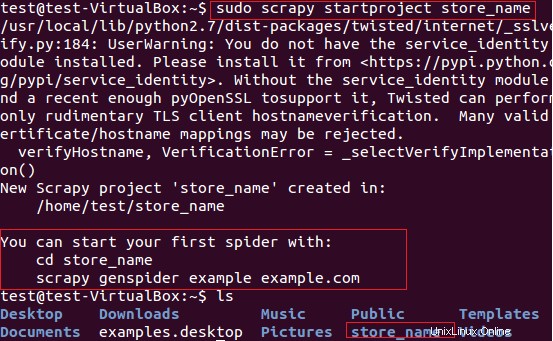
上記のコマンドは、現在のパスに「store_name」というタイトルのディレクトリを作成します。プロジェクトのこのメインディレクトリには、次の図6に示すファイル/フォルダが含まれています。
$ sudo ls –lR store_name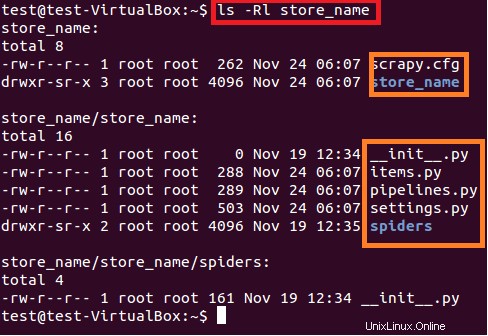
各ファイル/フォルダの簡単な説明を以下に示します:
- scrapy.cfgはプロジェクト構成ファイルです
- store_name /は、メインディレクトリ内の別のディレクトリです。このディレクトリには、プロジェクトのPythonコードが含まれています。
- store_name / items.pyには、スパイダーによって抽出されるアイテムが含まれています。
- store_name/pipelines.pyはパイプラインファイルです。
- store_nameプロジェクトの設定はstore_name/settings.pyファイルにあります。
- およびstore_name / spiders /ディレクトリには、クロール用のスパイダーが含まれています
fatwallet.comサイトからカードのストア名を抽出することに関心があるため、ファイルの内容を次のように更新しました。
import scrapy
class StoreNameItem(scrapy.Item):
name = scrapy.Field() # extract the names of Cards storeこの後、プロジェクトのstore_name /spiders/ディレクトリに新しいスパイダーを作成する必要があります。 Spiderは、次の必須属性で構成されるPythonクラスです。
-
スパイダーの名前(name)
- クロール用のスパイダーの開始URL(start_urls)
-
そして、ページ応答から目的のアイテムを抽出するための正規表現で構成される解析メソッド。解析方法はスパイダーの重要な部分です。
store_name / spiders /ディレクトリの下にスパイダー「store_name.py」を作成し、fatwallet.comサイトからストア名を抽出するために次のPythonコードを追加しました。スパイダーの出力はファイル( StoreName.txt )に書き込まれます。 。
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|\
//tr[@class="storeListRow even"]|\
//tr[@class="storeListRow even last"]|\
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"\n")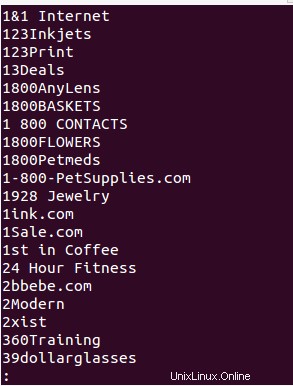
注:このチュートリアルの目的は、ScrapyFrameworkを理解することだけです