はじめに
Apache Hiveは、Hadoop分散ファイルシステムに保存されているデータのクエリ、管理、分析に使用されるエンタープライズデータウェアハウスシステムです。
Hiveクエリ言語(HiveQL)は、Hiveコマンドラインインターフェイスシェルでのクエリを容易にします。 Hadoopは、HiveQLをブリッジとして使用して、リレーショナルデータベース管理システムと通信し、SQLのようなコマンドに基づいてタスクを実行できます。
この簡単なガイドは、Ubuntu20.04にApacheHiveをインストールする方法を示しています。 。

前提条件
Apache HiveはHadoopに基づいており、完全に機能するHadoopフレームワークが必要です。
UbuntuにApacheHiveをインストールする
Apache Hiveを構成するには、最初にHiveをダウンロードして解凍する必要があります。次に、次のファイルと設定をカスタマイズする必要があります。
- .bashrcを編集します ファイル
- hive-config.shを編集します ファイル
- Hiveディレクトリを作成 HDFSで
- hive-site.xmlを構成します ファイル
- Derbyデータベースを開始します
ステップ1:ハイブをダウンロードして解凍する
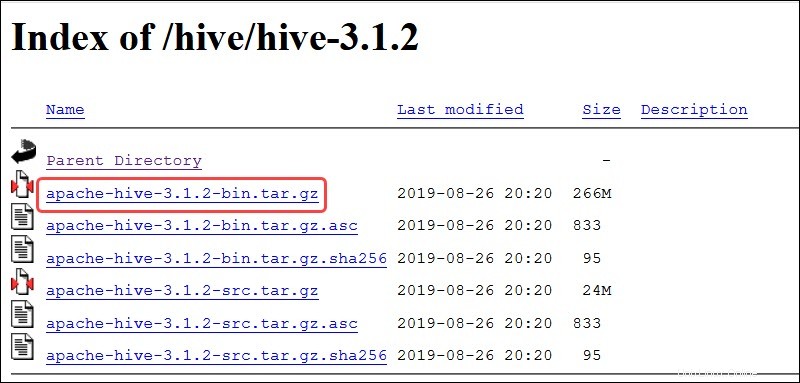
Apache Hiveの公式ダウンロードページにアクセスして、Hadoopエディションに最適なHiveバージョンを決定します。必要なバージョンを決定したら、今すぐリリースをダウンロード!を選択します オプション。
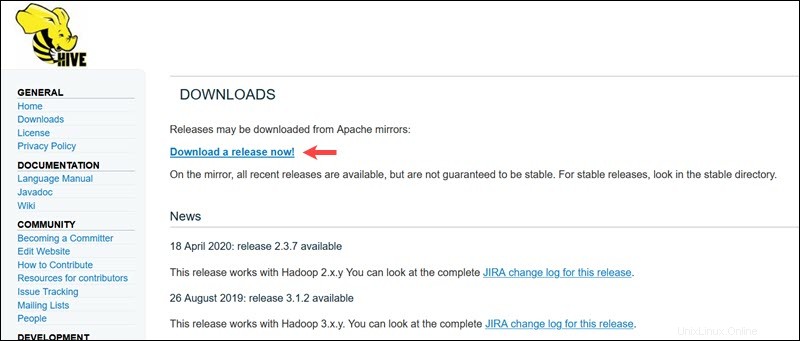
次のページのミラーリンクは、利用可能なHivetarパッケージを含むディレクトリにつながります。このページには、ミラーサイトから取得したファイルの整合性を検証する方法に関する役立つ手順も記載されています。
このガイドで紹介されているUbuntuシステムには、すでに Hadoop 3.2.1があります。 インストールされています。このHadoopバージョンは、 Hive 3.1.2と互換性があります リリース。
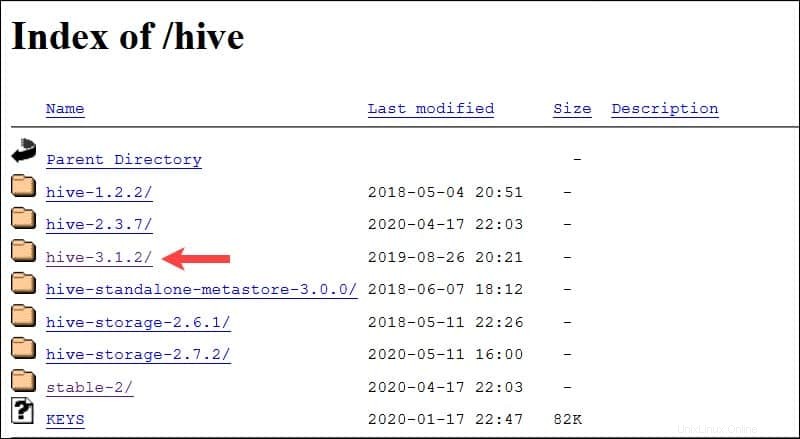
apache-hive-3.1.2-bin.tar.gzを選択します ダウンロードプロセスを開始するためのファイル。
または、Ubuntuコマンドラインにアクセスし、 wgetを使用して圧縮されたHiveファイルをダウンロードします。 コマンドの後にダウンロードパスが続く:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz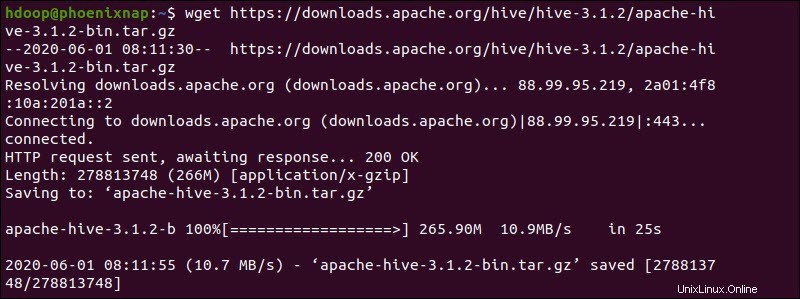
ダウンロードプロセスが完了したら、圧縮されたHiveパッケージを解凍します。
tar xzf apache-hive-3.1.2-bin.tar.gzこれで、Hiveバイナリファイルは apache-hive-3.1.2-binに配置されます。 ディレクトリ。

ステップ2:Hive環境変数(bashrc)を構成する
$HIVE_HOME 環境変数は、クライアントシェルを apache-hive-3.1.2-binに転送する必要があります ディレクトリ。 .bashrcを編集します 選択したテキストエディタを使用したシェル構成ファイル(nanoを使用します):
sudo nano .bashrc次のHive環境変数を.bashrcに追加します ファイル:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binHadoop環境変数は同じファイル内にあります。
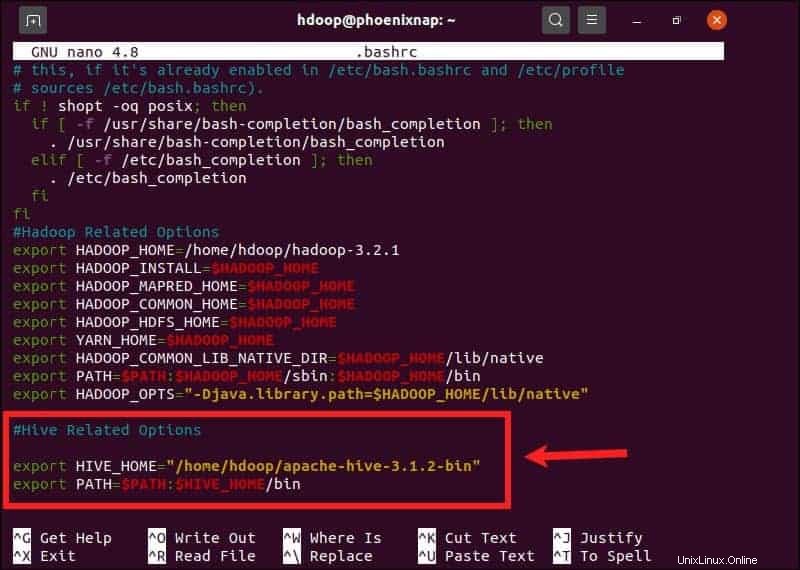
.bashrcを保存して終了します Hive変数を追加したらファイルします。次のコマンドを使用して、現在の環境に変更を適用します。
source ~/.bashrcステップ3:hive-config.shファイルを編集する
Apache Hiveは、Hadoop分散ファイルシステムと対話できる必要があります。 hive-config.shにアクセスします 以前に作成した$HIVE_HOMEを使用したファイル 変数:
sudo nano $HIVE_HOME/bin/hive-config.sh
HADOOP_HOMEを追加します 変数とHadoopディレクトリへのフルパス:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
編集内容を保存して、 hive-config.shを終了します ファイル。
ステップ4:HDFSでHiveディレクトリを作成する
HDFSレイヤーにデータを保存するために2つの別々のディレクトリを作成します。
- 一時的なtmp ディレクトリには、Hiveプロセスの中間結果が保存されます。
- 倉庫 ディレクトリには、Hive関連のテーブルが保存されます。
tmpディレクトリの作成
tmpを作成します HDFSストレージレイヤー内のディレクトリ。このディレクトリには、HiveがHDFSに送信する中間データが保存されます。
hdfs dfs -mkdir /tmptmpグループメンバーに書き込みおよび実行権限を追加します:
hdfs dfs -chmod g+w /tmp権限が正しく追加されたかどうかを確認します:
hdfs dfs -ls /出力は、ユーザーが書き込みと実行のアクセス許可を持っていることを確認します。

倉庫ディレクトリの作成
倉庫を作成します / user / hive /内のディレクトリ 親ディレクトリ:
hdfs dfs -mkdir -p /user/hive/warehouse書き込みを追加 および実行 倉庫へのアクセス許可 グループメンバー:
hdfs dfs -chmod g+w /user/hive/warehouse権限が正しく追加されたかどうかを確認します:
hdfs dfs -ls /user/hive出力は、ユーザーが書き込みと実行のアクセス許可を持っていることを確認します。

ステップ5:hive-site.xmlファイルを構成する(オプション)
Apache Hiveディストリビューションには、デフォルトでテンプレート構成ファイルが含まれています。テンプレートファイルは、Hive conf内にあります。 ディレクトリとアウトラインのデフォルトのHive設定。
次のコマンドを使用して、正しいファイルを見つけます。
cd $HIVE_HOME/conf
ls を使用して、フォルダに含まれるファイルを一覧表示します コマンド。

hive-default.xml.templateを使用します hive-site.xmlを作成します ファイル:
cp hive-default.xml.template hive-site.xmlhive-site.xmlにアクセスします nanoテキストエディタを使用したファイル:
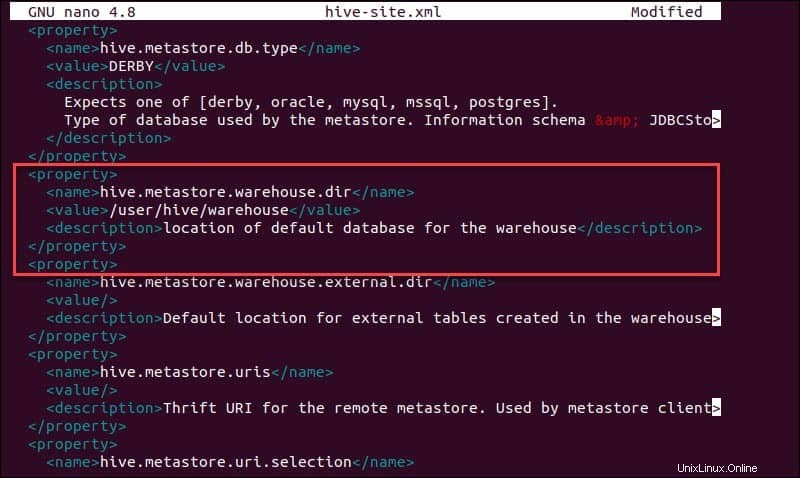
sudo nano hive-site.xml実際のApacheHadoopクラスターではなくスタンドアロンモードでHiveを使用することは、初心者にとって安全なオプションです。 hive.metastore.warehouse.dir を設定することにより、HDFSレイヤーではなくローカルストレージを使用するようにシステムを構成できます。 ハイブの場所へのパラメータ値倉庫 ディレクトリ。
ステップ6:Derbyデータベースを開始する
Apache Hiveは、Derbyデータベースを使用してメタデータを格納します。 Hive binからDerbyデータベースを開始します schematoolを使用するディレクトリ コマンド:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaプロセスが完了するまでに少し時間がかかる場合があります。
Derbyは、Hiveのデフォルトのメタデータストアです。 MySQLやPostgreSQLなどの別のデータベースソリューションを使用する場合は、 hive-site.xmlでデータベースタイプを指定できます。 ファイル。
Hiveのグアバ非互換性エラーを修正する方法
Derbyデータベースが正常に開始されない場合は、次の内容でエラーが発生する可能性があります。
「スレッド「main」java.lang.NoSuchMethodErrorの例外:com.google.common.base.Preconditions.checkArgument(ZLjava / lang / String; Ljava / lang / Object;)V」
このエラーは、HadoopとHiveの間に非互換性の問題がある可能性が高いことを示しています guava バージョン。
グアバ瓶を見つけます Hive libのファイル ディレクトリ:
ls $HIVE_HOME/lib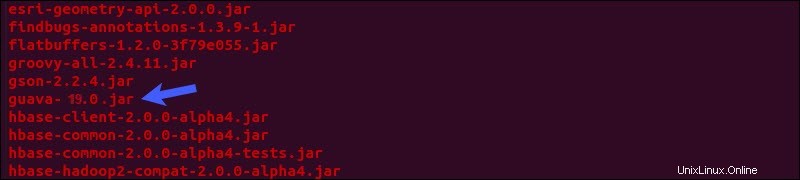
グアバ瓶を見つけます Hadoop lib内のファイル ディレクトリも:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
リストされている2つのバージョンには互換性がなく、エラーが発生しています。既存のグアバを削除します Hive libからのファイル ディレクトリ:
rm $HIVE_HOME/lib/guava-19.0.jarグアバをコピーします Hadoop libからのファイル Hive libへのディレクトリ ディレクトリ:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
schematoolを使用します もう一度コマンドを実行して、Derbyデータベースを開始します。
$HIVE_HOME/bin/schematool -dbType derby -initSchemaUbuntuでHiveクライアントシェルを起動
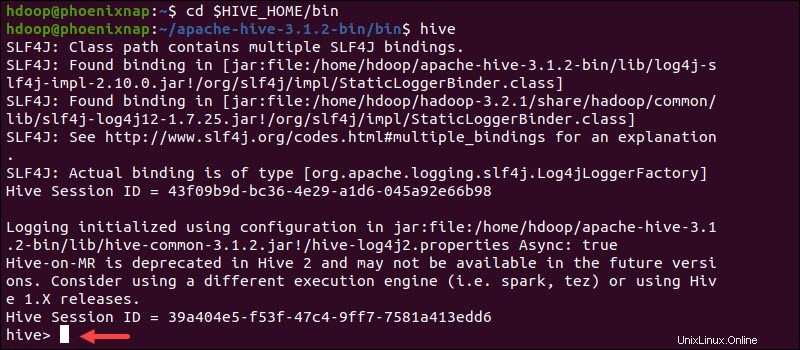
次のコマンドを使用して、Hiveコマンドラインインターフェイスを起動します。
cd $HIVE_HOME/binhiveこれで、SQLのようなコマンドを発行し、HDFSと直接対話できるようになりました。