はじめに
Elasticsearchは、クラスターにデプロイされたリアルタイムのスケーラブルな検索エンジンです。 Kubernetesオーケストレーションと組み合わせると、Elasticsearchの構成、管理、スケーリングが簡単になります。
デフォルトでElasticsearchクラスターをデプロイすると、3つのポッドが作成されます。各ポッドは、マスター、データ、クライアントの3つの機能すべてを提供します。ただし、ベストプラクティスは、役割ごとに複数の専用Elasticsearchポッドを手動でデプロイすることです。
この記事では、Elasticsearchを7つのポッドのKubernetesに手動でデプロイし、事前に作成されたHelmチャートを使用する方法について説明します。

前提条件
- Kubernetesクラスター(Minikubeを使用)
- Helmパッケージマネージャー。
- kubectlコマンドラインツール。
- コマンドラインまたはターミナルへのアクセス。
KubernetesにElasticsearchを手動でデプロイする方法
ベストプラクティスは、Elasticsearchクラスターで7つのポッドを使用することです:
- クラスターを管理するための3つのマスターポッド。
- データを保存してクエリを処理するための2つのデータポッド。
- トラフィックを誘導するための2つのクライアント(または調整)ポッド。
7つの専用ポッドを使用してElasticsearchをKubernetesに手動でデプロイするのは簡単なプロセスであり、役割ごとにHelm値を設定する必要があります。
ステップ1:Kubernetesを設定する
1.クラスターには大量のリソースが必要です。 Minikube CPUを最小4に設定し、メモリを8192MBに設定します:
minikube config set cpus 4
minikube config set memory 8192
2.ターミナルを開き、次のパラメーターを使用してminikubeを起動します。
minikube start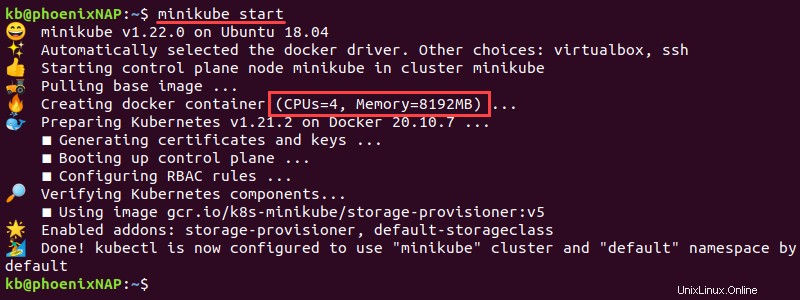
インスタンスは、構成されたメモリとCPUから始まります。
3.Minikubeにはvalues.yamlが必要です Elasticsearchを実行するファイル。次のファイルをダウンロードします:
curl -O https://raw.githubusercontent.com/elastic/helm-charts/master/elasticsearch/examples/minikube/values.yaml
このファイルには、3つのポッド構成すべてについて次のステップで使用される情報が含まれています。
ステップ2:ポッドの役割ごとに値を設定する
1. values.yamlの内容をコピーします cpを使用したファイル 3つの異なるポッド構成ファイルへのコマンド:
cp values.yaml master.yaml
cp values.yaml data.yaml
cp values.yaml client.yaml
2. lsを使用して4つのYAMLファイルを確認します コマンド:
ls -l *.yaml3. master.yamlを開きます テキストエディタでファイルを作成し、最初に次の構成を追加します。
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
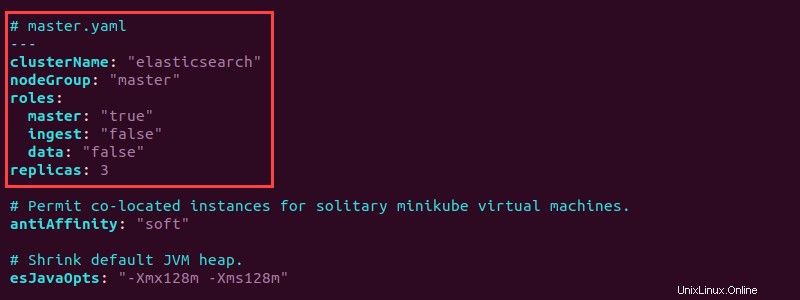
構成により、ノードグループがマスターに設定されます elasticsearchで クラスタ化し、マスターの役割を "true"に設定します 。さらに、 master.yaml 3つのマスターノードレプリカを作成します。
完全なmaster.yaml 次のようになります:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
# Permit co-located instances for solitary minikube virtual machines.
antiAffinity: "soft
# Shrink default JVM heap.
esJavaOpts: "-Xmx128m -Xms128m"
# Allocate smaller chunks of memory per pod.
resources:
requests:
cpu: "100m"
memory: "512M"
limits:
cpu: "1000m"
memory: "512M"
# Request smaller persistent volumes.
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 100M
4.ファイルを保存して閉じます。
5. data.yamlを開きます ファイルを作成し、上部に次の情報を追加して、データポッドを構成します。
# data.yaml
---
clusterName: "elasticsearch"
nodeGroup: "data"
roles:
master: "false"
ingest: "true"
data: "true"
replicas: 2
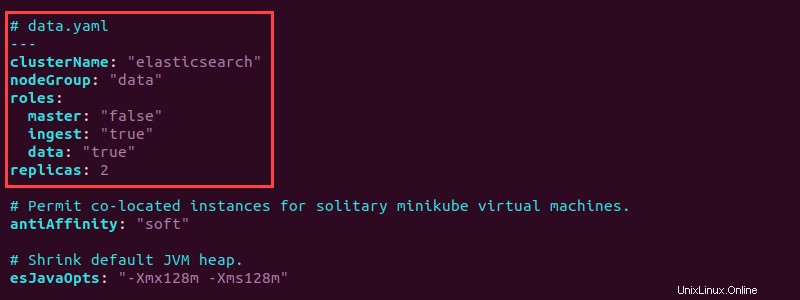
セットアップにより、2つのデータポッドレプリカが作成されます。データと取り込みの両方の役割を"true"に設定します 。ファイルを保存して閉じます。
6. client.yamlを開きます ファイルを作成し、上部に次の構成情報を追加します。
# client.yaml
---
clusterName: "elasticsearch"
nodeGroup: "client"
roles:
master: "false"
ingest: "false"
data: "false"
replicas: 2
service:
type: "LoadBalancer"
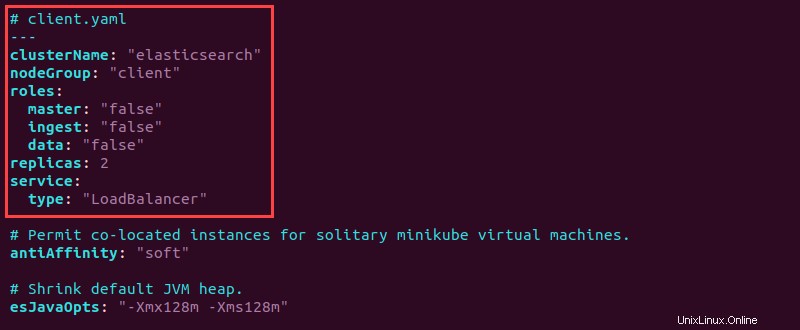
7.ファイルを保存して閉じます。
クライアントのすべての役割が"false"に設定されています クライアントがサービスリクエストを処理するため。 サービスタイプは"LoadBalancer"として指定されます すべてのノード間でサービスリクエストのバランスをとる。
ステップ3:ロールごとにElasticsearchポッドをデプロイする
1. Helmリポジトリを追加します:
helm repo add elastic https://helm.elastic.co
2. helm installを使用します 前の手順で作成したカスタムYAMLファイルごとに1回ずつ、3回コマンドを実行します。
helm install elasticsearch-multi-master elastic/elasticsearch -f ./master.yaml
helm install elasticsearch-multi-data elastic/elasticsearch -f ./data.yaml
helm install elasticsearch-multi-client elastic/elasticsearch -f ./client.yaml
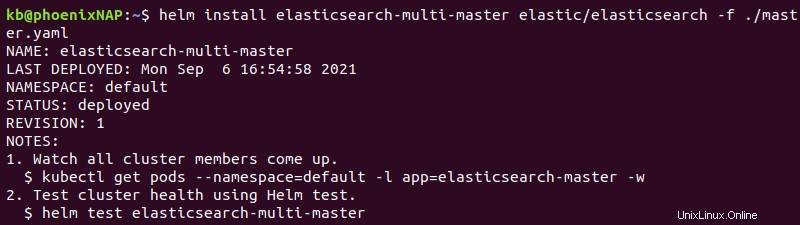
出力には、展開の詳細が出力されます。
3.クラスターメンバーがデプロイされるのを待ちます。次のコマンドを使用して、進行状況を調べ、完了を確認します。
kubectl get pods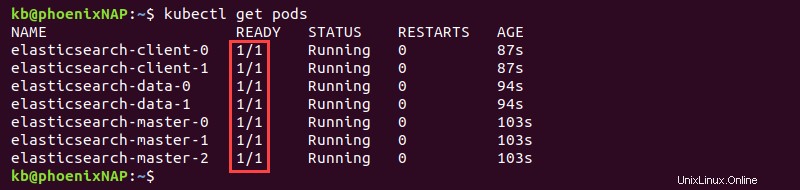
出力には準備完了が表示されます 値が1/1の列 7つのポッドすべての展開が完了したら。
ステップ4:接続をテストする
1. Elasticsearchにローカルでアクセスするには、ポート 9200を転送します kubectlを使用する コマンド:
kubectl port-forward service/elasticsearch-master
コマンドは接続を転送し、開いたままにします。ターミナルウィンドウを実行したままにして、次の手順に進みます。
2.別のターミナルタブで、次のコマンドで接続をテストします。
curl localhost:9200出力には、展開情報が出力されます。
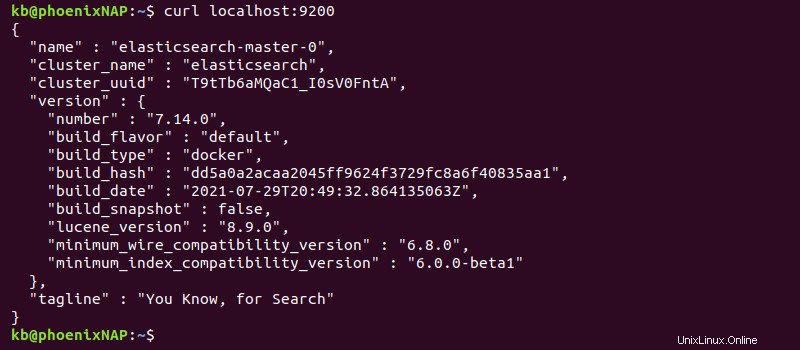
または、 localhost:9200にアクセスします ブラウザから。
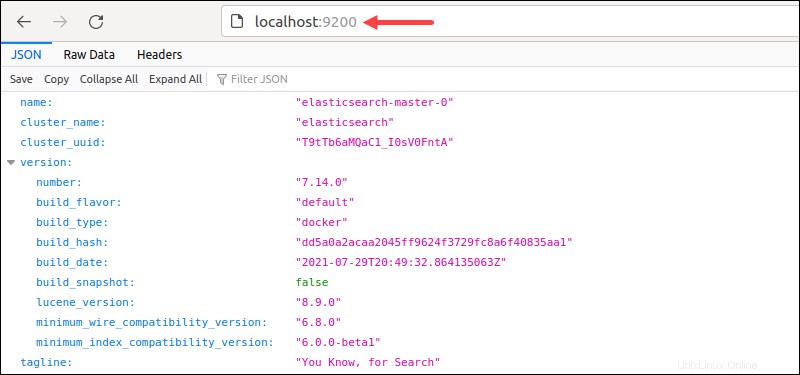
出力には、クラスターの詳細がJSON形式で表示され、デプロイが成功したことが示されます。
ビルド済みのヘルムチャートを使用して7つのポッドでElasticsearchをデプロイする方法
Elasticsearchを7つの専用ポッドにデプロイするためのビルド済みのHelmチャートは、Bitnamiリポジトリで入手できます。この方法でチャートをインストールすると、構成ファイルを手動で作成する必要がなくなります。
ステップ1:Kubernetesを設定する
1.少なくとも4つのCPUと8192MBのメモリを割り当てます:
minikube config set cpus 4
minikube config set memory 8192
2. Minikubeを起動します:
minikube startMinikubeインスタンスは、指定された構成で開始されます。
ステップ2:Bitnamiリポジトリを追加してElasticsearchチャートをデプロイする
1.次のコマンドでBitnamiHelmリポジトリを追加します:
helm repo add bitnami https://charts.bitnami.com/bitnami
2.次のコマンドを実行してチャートをインストールします:
helm install elasticsearch --set master.replicas=3,coordinating.service.type=LoadBalancer bitnami/elasticsearch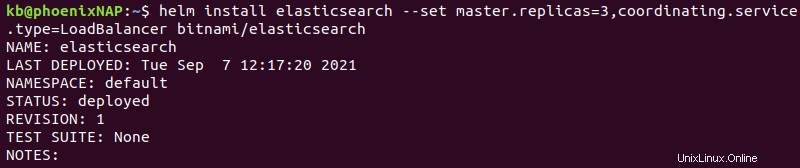
このコマンドには次のオプションがあります。
- Elasticsearchはリリース名
elasticsearchでインストールされます 。 -
master.replicas=33つのマスターレプリカをクラスターに追加します。 3つのマスターノードを使用することをお勧めします。 -
coordinating.service.type=LoadBalancerすべてのノード間でサービスリクエストのバランスをとるようにクライアントノードを設定します。
3.次の方法で展開を監視します:
kubectl get pods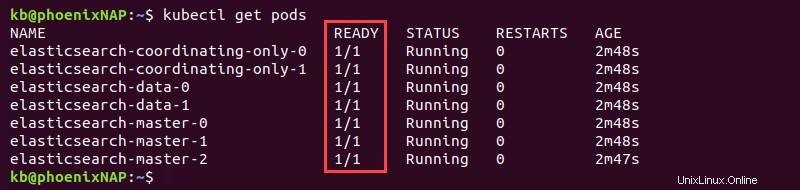
7つのポッドは1/1を示しています 準備完了 Elasticsearchが完全にデプロイされたときの列。
ステップ3:接続をテストする
1.接続をポート9200に転送します :
kubectl port-forward svc/elasticsearch-master 9200接続を開いたままにして、次の手順に進みます。
2.別のターミナルタブで、次の接続を確認します。
curl localhost:9200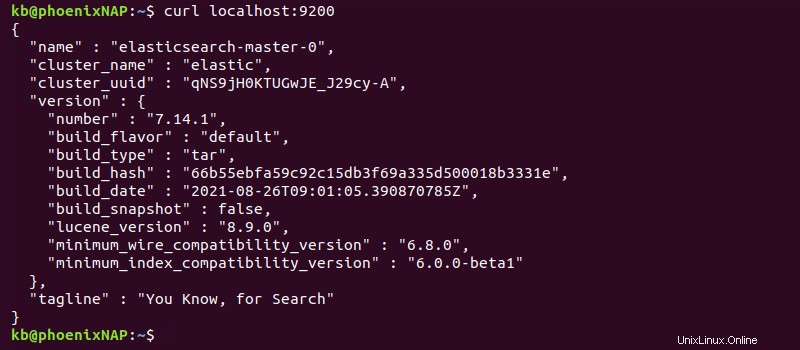
または、ブラウザから同じアドレスにアクセスして、JSON形式でデプロイ情報を表示します。