はじめに
Hiveの用語では、外部テーブルはHiveで管理されないテーブルです。それらの目的は、外部ファイルからメタストアへのデータのインポートを容易にすることです。
外部テーブルデータは外部に保存されますが、Hiveメタストアにはメタデータスキーマのみが含まれます。したがって、外部テーブルを削除してもデータには影響しません。
このチュートリアルでは、Hiveで外部テーブルを作成、クエリ、およびドロップする方法を学習します。

前提条件
- Ubuntu18.04LTS以降
- sudo権限を持つコマンドラインへのアクセス
- ApacheHadoopがインストールされて実行されている
- ApacheHiveがインストールされ実行されている
注: このチュートリアルでは、Ubuntu20.04を使用します。ただし、Hiveはすべてのオペレーティングシステムで同じように動作します。これは、外部テーブルの作成、クエリ、および削除のプロセスを、Windows、Mac OS、その他のLinuxディストリビューションなどのHiveに適用できることを意味します。
Hiveでの外部テーブルの作成–構文の説明
Hiveで外部テーブルを作成するときは、次の情報を提供する必要があります。
- テーブルの名前 –
create external tableコマンドはテーブルを作成します。同じ名前のテーブルがシステムにすでに存在する場合、これによりエラーが発生します。これを回避するには、if not existsを追加します ステートメントに。テーブル名では大文字と小文字は区別されません。 - 列の名前とタイプ –テーブル名と同様に、列名では大文字と小文字が区別されません。列タイプは、
intなどの値です。 、char、string、など - 行形式 –行はネイティブまたはカスタムのSerDe(Serializer / Deserializer)形式を使用します。行形式が定義されていない場合、または区切り文字として指定されている場合は、ネイティブSerDeが使用されます。
- フィールド終了文字 –これは
charテーブルの値を行で区切る文字を入力します。 - ストレージ形式 – textfile、sequencefile、jsonfileなどのストレージ形式を指定できます。
- 場所 –これは、テーブルデータを含むファイルのHDFSディレクトリの場所です。
この情報をHiveに提供するための正しい構文は次のとおりです。
create external table if not exists [external-table-name] (
[column1-name] [column1-type], [column2-name] [column2-type], …)
comment '[comment]'
row format [format-type]
fields terminated by '[termination-character]'
stored as [storage-type]
location '[location]';Hive外部テーブルの作成–例
実用的な例として、このチュートリアルでは、CSVファイルから外部テーブルにデータをインポートする方法を示します。
ステップ1:データファイルを準備する
1.「countries.csv」というタイトルのCSVファイルを作成します:
sudo nano countries.csv2.リスト内の国ごとに、行番号、国の名前、首都、人口を百万単位で記入します。
1,USA,Washington,328
2,France,Paris,67
3,Spain,Madrid,47
4,Russia,Moscow,145
5,Indonesia,Jakarta,267
6,Nigeria,Abuja,196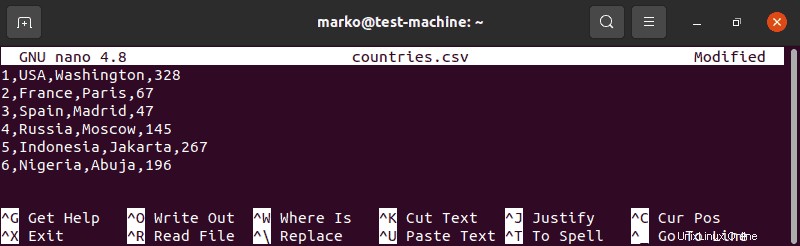
3.ファイルを保存し、その場所をメモします。
ステップ2:ファイルをHDFSにインポートする
1.HDFSディレクトリを作成します。このディレクトリを、作成したファイルのHDFSの場所として使用します。
hdfs dfs -mkdir [hdfs-directory-name]2. CSVファイルをHDFSにインポートします:
hdfs dfs -put [original-file-location] [hdfs-directory-name]
3. -lsを使用します ファイルがHDFSフォルダーにあることを確認するコマンド:
hdfs dfs -ls [hdfs-directory-name]
出力には、現在ディレクトリにあるすべてのファイルが表示されます。
注: HDFSの詳細については、「HDFSとは」を参照してください。 Hadoop分散ファイルシステムガイド。
ステップ3:外部テーブルを作成する
1.データファイルをHDFSにインポートした後、Hiveを起動し、上記の構文を使用して外部テーブルを作成します。
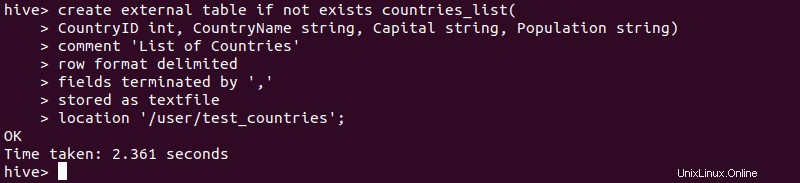
2.外部テーブルの作成が成功したことを確認するには、次のように入力します。
select * from [external-table-name];出力には、テーブルにインポートしたCSVファイルのデータが一覧表示されます。
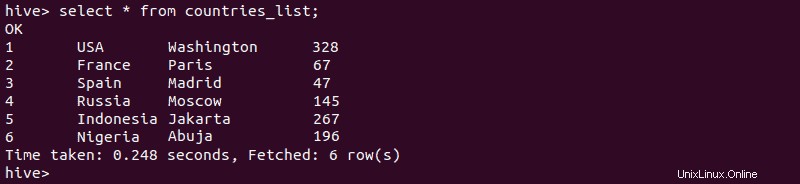
3.外部テーブルのデータを使用して管理対象テーブルを作成する場合は、次のように入力します。
create table if not exists [managed-table-name](
[column1-name] [column1-type], [column2-name] [var2-name], …)
comment '[comment]';
4.次に、外部テーブルからデータをインポートします。
insert overwrite table [managed-table-name] select * from [external-table-name];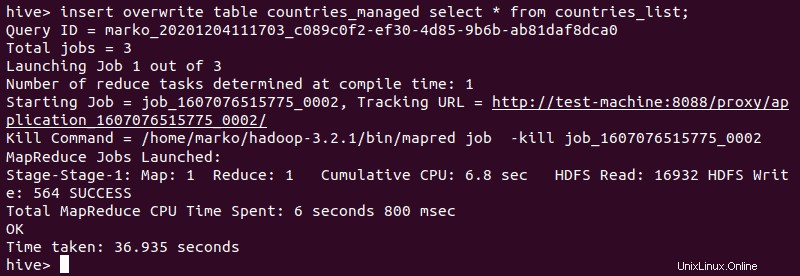
5.データが管理対象テーブルに正常に挿入されていることを確認します。
select * from [managed-table-name];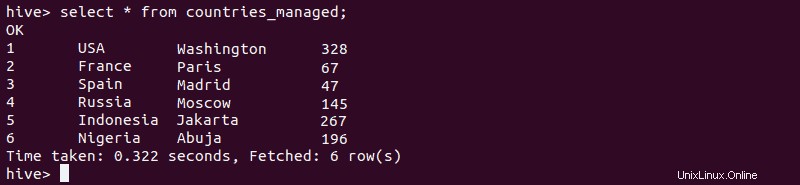
Hive外部テーブルをクエリする方法
テーブルに保存されているすべてのデータを表示するには、 select * fromを使用します コマンドの後にテーブル名が続きます。 Hiveは、検索を絞り込み、好みに応じてデータを並べ替えることができるクエリコマンドの広範なリストを提供します。
たとえば、 whereを使用できます select * fromの後のコマンド 条件を指定するには:
select * from [table_name] where [condition];Hiveは、クエリで指定された条件を満たす行のみを出力します:

アスタリスクの代わりに 「すべてのデータ」を表す文字。より具体的な限定詞を使用できます。アスタリスクを列名( CountryName など)に置き換えます 、上記の例から)は、選択した列のデータのみを表示します。
その他の便利なクエリ関数とその構文は次のとおりです。
| 関数 | 構文 |
|---|---|
| 複数の条件に従ってテーブルをクエリする | select * from [table_name] where [condition1] and [condition2]; |
| 注文テーブルデータ | select [column1_name], [column2_name] from [table_name] order by [column_name]; |
| テーブルデータを降順で並べ替える | select [column1_name], [column2_name] from [table_name] order by [column_name] desc; |
| 行数を表示 | select count(*) from [table_name]; |
ハイブ外部テーブルを削除する方法
1. Hiveでの外部テーブルのドロップは、管理対象テーブルで使用されるのと同じドロップコマンドを使用して実行されます。
drop table [table_name];出力は、操作の成功を確認します:

2.ドロップされたテーブルをクエリすると、エラーが返されます:

ただし、外部テーブルのデータはシステムに残り、同じ場所に別の外部テーブルを作成することで取得できます。