もちろん、コマンドターミナルを使用して、ApacheKafkaをRockyLinuxまたはAlmaLinux8サーバーにインストールする手順は次のとおりです。
Apache Kafkaは、分散ストリーミングプラットフォームを介したデータストリームの保存と処理を可能にするオープンソースソフトウェアです。簡単に言うと、Apache Kafkaは、送信者と受信者の間のメッセージングシステムとして機能するイベントストリーミングプラットフォームであり、フォールトトレランスとスケーラビリティの機能が高く、同じように最適化された分散アーキテクチャに基づいているためです。
このシステムは元々LinkedInによってメッセージキューとして開発されましたが、Apache Software Foundationのプロジェクトであるため、オープンソースであり、さまざまな機能を備えた強力なストリーミングプラットフォームです。 Kafkaクラスターへのデータの書き込み、データの読み取り、またはサードパーティシステムとの間でのデータのインポートとエクスポートを行うためのインターフェイスを提供します。低レイテンシと高スループットにより、リアルタイムストリームを簡単に処理できます。
これらのインターフェースにより、ユーザーはサードパーティのシステムからデータストリームをロードしたり、これらのシステムにエクスポートしたりすることもできます。これにより、ApacheKafkaはビッグデータ環境の大量のデータやアプリケーションに適しています。
Webサイトのアクティビティをリアルタイムで追跡する、分散アプリケーションを監視する、さまざまなソースからのログファイルを集約する、分散システムでデータを同期する、モデルをリアルタイムでトレーニングするなど、さまざまなアプリケーションに使用できます。その他…
Apache Kafkaは、これら4つの主要なインターフェース(API –アプリケーションプログラミングインターフェース)を提供します。各APIの詳細については、公式ドキュメントページをご覧ください:
- 管理API
- プロデューサーAPI
- コンシューマーAPI
- Streams API
- Connect API
このチュートリアルに従う必要があるもの:
- Rocky、AlmaLinux 8、またはその他のRHELベースのサーバー、可能であれば、サーバーをクリーンアップします。
- sudoアクセス権を持つユーザー。
RockyLinux8にApacheKafkaをインストールする手順
所定のガイドは、CentOS8およびOracleLinux8を含むすべてのRHEL8ベースのLinuxシステムに適用され、必要に応じてKafkaをインストールします。
1。システムの更新
さらに移動する前に、system updateコマンドを実行して、インストールされているすべてのパッケージが最新であることを確認してください。以下のコマンドを実行すると、リポジトリキャッシュも更新されます。
sudo dnf update
2。 Javaをインストールする
Apache Kafkaを実行するにはJavaが必要です。したがって、最初にJavaをローカル環境にインストールする必要があり、Java 8以上である必要があります。JAVAを取得するためのパッケージがすでに存在するため、3番目のリポジトリを追加する必要はありません。したがって、システムベースのリポジトリで、指定されたコマンドを使用しましょう。
Java11の場合
sudo dnf install java-11-openjdk
16などの最新バージョンの場合は、次のコマンドを使用します。
sudo dnf install epel-release
sudo dnf install java-latest-openjdk
3。 RockyLinux8またはAlmalinuxで最新のApacheKafkaをダウンロード
Apache Kafkaは、公式Webサイトでtarballファイルとして入手できます。したがって、公式Webサイトにアクセスして、最新バージョンをダウンロードしてください。任意のミラーリンクをコピーして、wgetを使用することもできます ここで行ったように、コマンドラインを使用してダウンロードするコマンド:
sudo dnf install wget nano
wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
ダウンロードしたファイルを抽出します
tar -xf kafka_*tgz
ファイルを表示するには:
ls
/usr/local/に移動します Kafkaフォルダを誤って削除しないようにするためです。
sudo mv kafka_2.13-3.0.0/ /usr/local/kafka
4。 ZookeeperとKafkaのシステムサービスを作成する
テストのためだけに、ZookeeperとKafkaの両方のサービススクリプトを直接、手動で実行できますが、本番サーバーの場合は、バックグラウンドで実行する必要があります。したがって、両方のスクリプトのsystemdユニットを作成します。
システムファイルZookeeperを作成する
将来の公式ウェブサイトによると、KafkaはZookeeperを必要としませんが、この記事を書いている間は必要です。したがって、最初にZookeeperのサービスファイルを作成します。
sudo nano /etc/systemd/system/zookeeper.service
コピー-以下の行を貼り付けます:
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/bin/bash /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/bin/bash /usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
保存 Ctr + Oを押してファイルを閉じます 、 Enterを押します キーを押してから、 Ctrl + Xを使用して終了します 。
次に、Kafkasystemdファイルを作成します
sudo nano /etc/systemd/system/kafka.service
次の行を貼り付けます。 注 – Java_Homeを変更します 、他のバージョンを使用している場合。これを見つけるには、次のコマンドを使用できます– sudo find /usr/ -name *jdk
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/jre-11-openjdk" ExecStart=/usr/bin/bash /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/bin/bash /usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
Ctrl + Oでファイルを保存します Enterを押します キーを押してから、 Ctrl + Xを使用します 同じを終了します。
デーモンをリロード
上記の変更をシステムに反映してサービスファイルを使用するには、システムデーモンを1回リロードします。
sudo systemctl daemon-reload
5。 RockyLinuxでZookeeperとKafkaサーバーを起動する
それでは、両方のサーバーサービスを起動して有効にし、システムの再起動後もアクティブになるようにします。
sudo systemctl start zookeeper sudo systemctl start kafka
sudo systemctl enable zookeeper sudo systemctl enable kafka
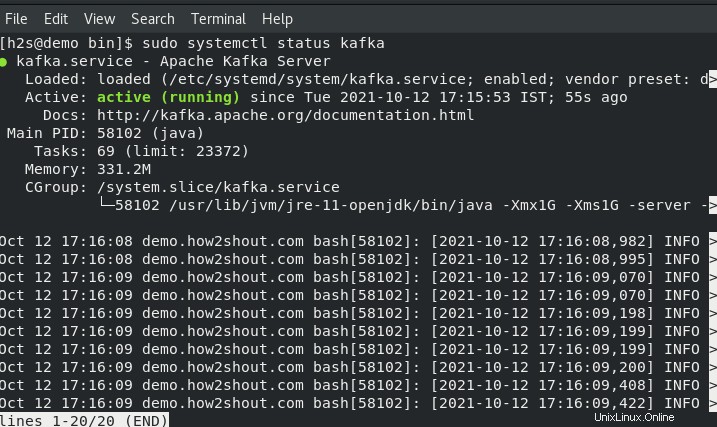
サービスステータスの確認:
sudo systemctl status zookeeper
sudo systemctl status kafka
6。 Kafkaでテストトピックを作成する–RockyまたはAlmaLinux
Kafkaを使用すると、さまざまなマシン間でイベントの読み取り、書き込み、保存、および処理を行うことができますが、これらのイベントを保存するには、「トピック」と呼ばれる場所またはフォルダーが必要です。 「。したがって、サーバーターミナルで次のコマンドを使用して少なくとも1つのトピックを作成し、後で同じコマンドを使用して、必要な数のトピックを作成できます。
私たちの最初のトピック名が– testevent だとしましょう 。したがって、同じ実行を作成するには:
Kafkaディレクトリに移動します。
cd / usr / local / kafka /
トピックスクリプトを使用します:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic testevent

必要な数のトピックを作成した後、それらをすべてリストするには、次のコマンドを使用できます。
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
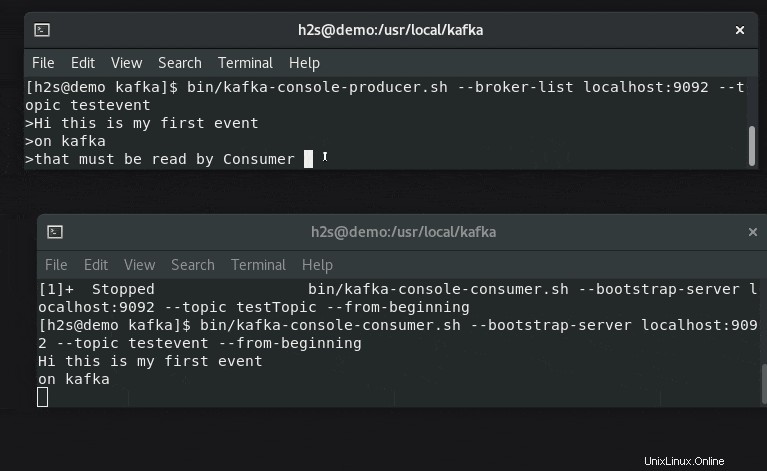
7。 Kafkaプロデューサーを使用してイベントを作成し、コンシューマーと一緒に読む
Kafkaは2つのAPIを提供しています-プロデューサー および消費者 、どちらの場合も、コマンドラインクライアントを提供します。プロデューサーはイベントの作成に責任があり、コンシューマーはそれらを使用してプロデューサーによって生成されたデータを表示または読み取ります。
2つのターミナルタブまたはセッションを開いて、イベントジェネレータとリーダーの設定をリアルタイムで理解します。
#1つの最初の端末:
テストするには、Producerスクリプトを使用していくつかのイベントを作成しましょう:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testevent
ストリーミングして消費者側に表示するテキストを入力します。
#もう一方の端末で
実行 メッセージまたは生成されたイベントデータをリアルタイムでチェックするためのトピック名とともに以下に示すコマンド:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testevent --from-beginning