カーネルがユーザー プログラム、つまりシステム コールに代わって実行されている場合、カーネル空間は使用されますか?それとも、すべてのカーネル スレッド (スケジューラなど) のアドレス空間ですか?
はい、はい。
先に進む前に、メモリについてこれを述べる必要があります。
メモリ取得は 2 つの異なる領域に分かれています:
- ユーザー スペース これは、通常のユーザー プロセスが実行される一連の場所 (つまり、カーネル以外のすべて) です。カーネルの役割は、このスペースで実行されているアプリケーションが相互に干渉しないように管理すること、およびマシンを管理することです。
- カーネル空間 、カーネルのコードが保存され、実行される場所です。
ユーザー空間で実行されているプロセスは、メモリの限られた部分にしかアクセスできませんが、カーネルはすべてのメモリにアクセスできます。ユーザー空間で実行されているプロセスもしません カーネル空間にアクセスできます。ユーザー空間プロセスは、カーネルのごく一部にしかアクセスできません カーネルによって公開されたインターフェース経由 - システム コール .プロセスがシステム コールを実行すると、ソフトウェア割り込みがカーネルに送信され、適切な割り込みハンドラーがディスパッチされ、ハンドラーの終了後に作業が続行されます。
カーネル スペース コードには、「カーネル モード」で実行するプロパティがあります。これは、(通常のデスクトップ (x86) コンピュータでは) リング 0 で実行されるコードと呼ばれるものです。 . 通常、x86 アーキテクチャには 4 つの保護リングがあります .リング 0 (カーネル モード)、リング 1 (仮想マシンのハイパーバイザーまたはドライバーによって使用される可能性があります)、リング 2 (ドライバーによって使用される可能性がありますが、それについてはよくわかりません)。リング 3 は、典型的なアプリケーションが実行されるものです。これは最小特権のリングであり、そこで実行されているアプリケーションはプロセッサの命令のサブセットにアクセスできます。リング 0 (カーネル空間) は最も特権的なリングであり、マシンのすべての命令にアクセスできます。たとえば、「プレーンな」アプリケーション (ブラウザなど) は x86 アセンブリ命令 lgdt を使用できません。 グローバル記述子テーブルまたは hlt をロードする プロセッサを停止します。
それが最初のものである場合、通常のユーザープログラムは3GBを超えるメモリを持つことができないということですか(分割が3GB + 1GBの場合)?また、その場合、1 GB のカーネル空間が論理的にマップされるため、ハイ メモリのページはどの仮想メモリ アドレスにマップされるので、カーネルはハイ メモリをどのように使用できますか?
これに対する回答については、こちらの wag による優れた回答を参照してください
CPU リングが最も明確な違いです
x86 保護モードでは、CPU は常に 4 つのリングの 1 つにあります。 Linux カーネルは 0 と 3 のみを使用します:
- カーネルの場合は 0
- ユーザー向け 3
これは、カーネルとユーザーランドの最も厳密で迅速な定義です。
Linux がリング 1 と 2 を使用しない理由:https://stackoverflow.com/questions/6710040/cpu-privilege-rings-why-rings-1-and-2-arent-used
現在のリングはどのように決定されますか?
現在のリングは次の組み合わせによって選択されます:
-
グローバル記述子テーブル:GDT エントリのメモリ内テーブルで、各エントリにはフィールド
Privlがあります リングをエンコードします。LGDT 命令は、アドレスを現在の記述子テーブルに設定します。
参照:http://wiki.osdev.org/Global_Descriptor_Table
-
GDT 内のエントリのインデックスを指すセグメント レジスタ CS、DS など。
例:
CS = 0GDT の最初のエントリが実行中のコードに対して現在アクティブであることを意味します。
各リングでできることは?
CPU チップは、次のように物理的に構築されています。
-
リング0はなんでもできる
-
リング 3 は複数の命令を実行できず、複数のレジスタに書き込むことができません。最も顕著な例:
-
自分のリングを変更することはできません!そうしないと、リング 0 に設定され、リングが役に立たなくなる可能性があります。
つまり、現在のリングを決定する現在のセグメント記述子を変更することはできません。
-
ページ テーブルを変更できません:https://stackoverflow.com/questions/18431261/how-does-x86-paging-work
つまり、CR3 レジスタを変更できず、ページング自体がページ テーブルの変更を防ぎます。
これにより、セキュリティやプログラミングの容易さのために、1 つのプロセスが他のプロセスのメモリを認識できなくなります。
-
割り込みハンドラを登録できません。これらはメモリ位置への書き込みによって構成されますが、これもページングによって防止されます。
ハンドラーはリング 0 で実行され、セキュリティ モデルを破ります。
つまり、LGDT および LIDT 命令は使用できません。
-
inのような IO 命令は実行できません およびout、したがって、任意のハードウェア アクセスがあります。そうしないと、たとえば、プログラムがディスクから直接読み取ることができる場合、ファイルのアクセス許可は役に立たなくなります。
より正確には、Michael Petch のおかげです。OS がリング 3 で IO 命令を許可することは実際に可能であり、これは実際にはタスク状態セグメントによって制御されます。
不可能なことは、そもそもリング 3 が許可を持っていなかった場合に、リング 3 が許可を与えることです。
Linux は常にそれを許可しません。参照:https://stackoverflow.com/questions/2711044/why-doesnt-linux-use-the-hardware-context-switch-via-the-tss
-
プログラムとオペレーティング システムはリング間でどのように移行しますか?
-
CPU の電源がオンになると、リング 0 で初期プログラムの実行が開始されます (まあまあですが、これは適切な概算です)。この初期プログラムをカーネルと考えることができます (ただし、通常はリング 0 にあるカーネルを呼び出すのはブートローダーです)。
-
ユーザーランド プロセスがファイルへの書き込みなどの処理をカーネルに実行させたい場合、
int 0x80などの割り込みを生成する命令を使用します。 またはsyscallカーネルに信号を送ります。 x86-64 Linux syscall の hello world の例:.data hello_world: .ascii "hello world\n" hello_world_len = . - hello_world .text .global _start _start: /* write */ mov $1, %rax mov $1, %rdi mov $hello_world, %rsi mov $hello_world_len, %rdx syscall /* exit */ mov $60, %rax mov $0, %rdi syscallコンパイルして実行:
as -o hello_world.o hello_world.S ld -o hello_world.out hello_world.o ./hello_world.outGitHub アップストリーム。
これが発生すると、CPU はカーネルが起動時に登録した割り込みコールバック ハンドラを呼び出します。ハンドラーを登録して使用する具体的なベアメタルの例を次に示します。
このハンドラーはリング 0 で実行され、カーネルがこのアクションを許可するかどうかを決定し、アクションを実行して、リング 3 でユーザーランド プログラムを再起動します。 x86_64
-
execのとき システムコールが使用されます (またはカーネルが/initを開始するとき) )、カーネルは新しいユーザーランド プロセスのレジスタとメモリを準備し、エントリ ポイントにジャンプして CPU をリング 3 に切り替えます -
プログラムが (ページングのために) 禁止されているレジスタまたはメモリ アドレスへの書き込みなどのいたずらをしようとすると、CPU はリング 0 でカーネル コールバック ハンドラも呼び出します。
しかし、ユーザーランドがいたずらだったので、今度はカーネルがプロセスを強制終了するか、シグナルで警告を発する可能性があります。
-
カーネルが起動すると、一定の周波数でハードウェア クロックが設定され、定期的に割り込みが生成されます。
このハードウェア クロックは、リング 0 を実行する割り込みを生成し、どのユーザーランド プロセスが起動するかをスケジュールできるようにします。
このようにして、プロセスがシステム コールを作成していない場合でもスケジューリングを行うことができます。
リングを複数持つ意味は何ですか?
カーネルとユーザーランドを分離することには、主に 2 つの利点があります:
- 一方が他方に干渉しないという確信が持てるほど、プログラムを作成しやすくなります。たとえば、あるユーザーランド プロセスは、ページングのために別のプログラムのメモリを上書きすることや、別のプロセスに対してハードウェアを無効な状態にすることを心配する必要はありません。
- より安全です。例えば。ファイルのアクセス許可とメモリの分離により、ハッキング アプリによる銀行データの読み取りを防ぐことができます。もちろん、これはカーネルを信頼していることを前提としています。
どうやって遊ぶの?
リングを直接操作するのに適したベア メタル セットアップを作成しました:https://github.com/cirosantilli/x86-bare-metal-examples
残念ながら、ユーザーランドの例を作成する忍耐力はありませんでしたが、ページングのセットアップまで行ったので、ユーザーランドは実現可能です。プル リクエストをお待ちしております。
あるいは、Linux カーネル モジュールはリング 0 で実行されるため、それらを使用して特権操作を試すことができます。制御レジスタを読み取る:https://stackoverflow.com/questions/7415515/how-to-access-the-control-registers-cr0-cr2-cr3-from-a-program-getting-segmenta/7419306#7419306
これは、ホストを停止せずに試すための便利な QEMU + Buildroot セットアップです。
カーネル モジュールの欠点は、他の kthreads が実行されており、実験に干渉する可能性があることです。しかし理論的には、カーネル モジュールですべての割り込みハンドラを引き継いでシステムを所有することができます。これは実際には興味深いプロジェクトです。
ネガティブ リング
負のリングは Intel のマニュアルでは実際には言及されていませんが、実際にはリング 0 自体よりもさらに機能を備えた CPU モードが存在するため、「負のリング」の名前にぴったりです。
一例は、仮想化で使用されるハイパーバイザー モードです。
詳細については、以下を参照してください:
- https://security.stackexchange.com/questions/129098/what-is-protection-ring-1
- https://security.stackexchange.com/questions/216527/ring-3-exploits-and-existence-of-other-rings
アーム
ARM では、リングは代わりに例外レベルと呼ばれますが、主な考え方は同じままです。
ARMv8 には 4 つの例外レベルがあり、一般的に次のように使用されます。
-
EL0:ユーザーランド
-
EL1:カーネル (ARM 用語では「スーパーバイザー」)。
svcで入力 以前はswiと呼ばれていた命令 (SuperVisor Call) これは、Linux システム コールを行うために使用される命令です。 Hello world ARMv8 の例:こんにちは。S
.text .global _start _start: /* write */ mov x0, 1 ldr x1, =msg ldr x2, =len mov x8, 64 svc 0 /* exit */ mov x0, 0 mov x8, 93 svc 0 msg: .ascii "hello syscall v8\n" len = . - msgGitHub アップストリーム。
Ubuntu 16.04 で QEMU を使ってテストしてください:
sudo apt-get install qemu-user gcc-arm-linux-gnueabihf arm-linux-gnueabihf-as -o hello.o hello.S arm-linux-gnueabihf-ld -o hello hello.o qemu-arm hello以下は、SVC ハンドラーを登録して SVC 呼び出しを行う具体的なベアメタルの例です。
-
EL2:Xen などのハイパーバイザー。
hvcで入力 命令 (ハイパーバイザー呼び出し)。OS にとってのハイパーバイザーは、ユーザーランドにとっての OS と同じです。
たとえば、Xen を使用すると、Linux や Windows などの複数の OS を同じシステムで同時に実行できます。また、Linux がユーザーランド プログラムに対して行うのと同じように、セキュリティとデバッグの容易さのために OS を互いに分離します。
ハイパーバイザーは、今日のクラウド インフラストラクチャの重要な部分です。ハイパーバイザーは、単一のハードウェアで複数のサーバーを実行できるようにし、ハードウェアの使用率を常に 100% 近くに保ち、多くの費用を節約します。
たとえば AWS は、KVM への移行がニュースになった 2017 年まで Xen を使用していました。
-
EL3:さらに別のレベル。 TODO の例。
smcで入力 命令 (セキュア モード コール)
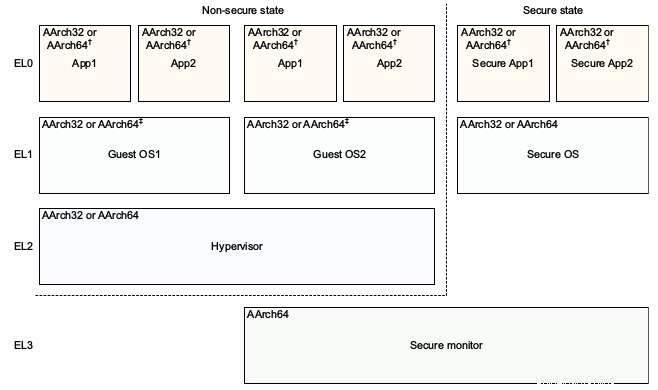
The ARMv8 Architecture Reference Model DDI 0487C.a - Chapter D1 - The AArch64 System Level Programmer's Model - 図 D1-1 はこれを美しく示しています:
ARMv8.1 Virtualization Host Extensions (VHE) の登場により、ARM の状況は少し変わりました。この拡張により、カーネルを EL2 で効率的に実行できます:
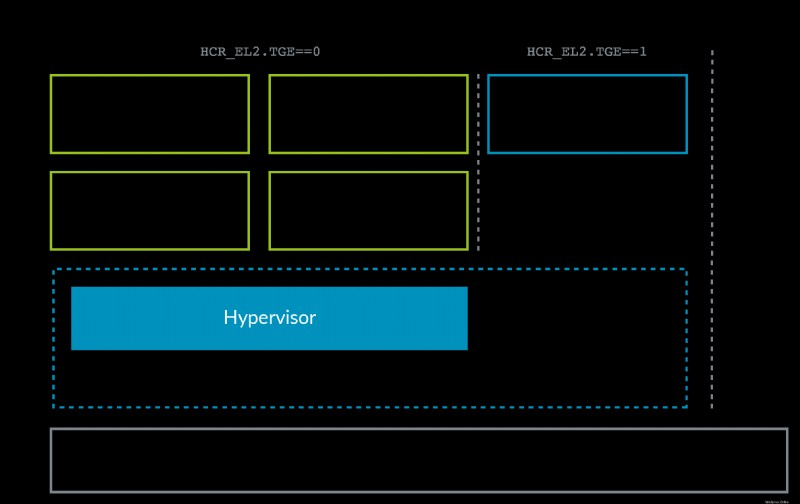
VHE が作成されたのは、KVM などの Linux カーネル内仮想化ソリューションが Xen よりも優位に立ったため (前述の AWS の KVM への移行を参照)、ほとんどのクライアントは Linux VM のみを必要とし、ご想像のとおり、オールインワンであるためです。プロジェクトでは、KVM は Xen よりもシンプルで潜在的に効率的です。そのため、ホストの Linux カーネルは、そのような場合にハイパーバイザーとして機能します。
おそらく後知恵の恩恵により、ARM は x86 よりも特権レベルの命名規則が優れていることに注意してください。負のレベルは必要ありません:0 が低く、3 が最高です。高いレベルは、低いレベルよりも頻繁に作成される傾向があります。
現在の EL は MRS で照会できます 命令:https://stackoverflow.com/questions/31787617/what-is-the-current-execution-mode-exception-level-etc
ARM では、チップ領域を節約する機能を必要としない実装を可能にするために、すべての例外レベルが存在する必要はありません。 ARMv8 の「例外レベル」には次のように書かれています:
<ブロック引用>実装には、すべての例外レベルが含まれているとは限りません。すべての実装には、EL0 と EL1 を含める必要があります。EL2 と EL3 はオプションです。
たとえば、QEMU のデフォルトは EL1 ですが、EL2 と EL3 はコマンド ライン オプションで有効にできます。
Ubuntu 18.10 でテストされたコード スニペット。
<ブロック引用>
それが最初のものである場合、通常のユーザー プログラムは 3GB (分割が 3GB + 1GB の場合) を超えるメモリを持つことができないということですか?
はい、これは通常の Linux システムの場合です。ある時点で、ユーザーとカーネルのアドレス空間を完全に独立させる「4G/4G」パッチのセットが浮かんでいました (カーネルがユーザーメモリにアクセスするのが難しくなったため、パフォーマンスが犠牲になりました)。それらはアップストリームにマージされ、x86-64 の台頭とともに関心が薄れました
<ブロック引用>また、その場合、1 GB のカーネル空間が論理的にマップされるため、ハイ メモリのページはどの仮想メモリ アドレスにマップされるので、カーネルはハイ メモリをどのように使用できますか?
Linux が以前 (アドレス空間に比べてメモリが小さいシステムでも) 動作していた方法は、物理メモリ全体がアドレス空間のカーネル部分に永続的にマップされるというものでした。これにより、カーネルは再マッピングなしですべての物理メモリにアクセスできましたが、多くの物理メモリを備えた 32 ビット マシンには明らかに対応していません。
そのため、低メモリと高メモリの概念が生まれました。 「低」メモリは、カーネルのアドレス空間に永続的にマップされます。 「高」メモリではありません。
プロセッサがシステム コールを実行しているとき、プロセッサはカーネル モードで実行されていますが、現在のプロセスのコンテキスト内にとどまっています。そのため、現在のプロセスのカーネル アドレス空間とユーザー アドレス空間の両方に直接アクセスできます (前述の 4G/4G パッチを使用していないと仮定します)。これは、「高い」メモリがユーザーランド プロセスに割り当てられても問題がないことを意味します。
カーネルの目的で「高」メモリを使用することは、より大きな問題です。現在のプロセスにマップされていない上位メモリにアクセスするには、一時的にカーネルのアドレス空間にマップする必要があります。これは、余分なコードとパフォーマンスの低下を意味します。