私はあなたの質問に興味をそそられ、ちょっと夢中になりました。このソリューションは、クリック可能なインデックスと色で強調表示されたコードを含む素敵な PDF ファイルを生成します。現在のディレクトリとサブディレクトリ内のすべてのファイルを検索し、それぞれの PDF ファイルにセクションを作成します (検索コマンドをより具体的にする方法については、以下の注を参照してください)。
以下がインストールされている必要があります (インストール手順は Debian ベースのシステム用ですが、これらはディストリビューションのリポジトリで利用できるはずです):
-
pdflatex、colorとlistingssudo apt-get install texlive-latex-extra latex-xcolor texlive-latex-recommendedこれにより、基本的な LaTeX システムがインストールされていない場合もインストールされます。
これらをインストールしたら、このスクリプトを使用して、ソース コードで LaTeX ドキュメントを作成します。トリックは listings を使用することです (texlive-latex-recommended の一部 ) および color (latex-xcolor によってインストールされます) ) LaTeX パッケージ。 \usepackage[..]{hyperref} これにより、目次のリストがクリック可能なリンクになります。
#!/usr/bin/env bash
tex_file=$(mktemp) ## Random temp file name
cat<<EOF >$tex_file ## Print the tex file header
\documentclass{article}
\usepackage{listings}
\usepackage[usenames,dvipsnames]{color} %% Allow color names
\lstdefinestyle{customasm}{
belowcaptionskip=1\baselineskip,
xleftmargin=\parindent,
language=C++, %% Change this to whatever you write in
breaklines=true, %% Wrap long lines
basicstyle=\footnotesize\ttfamily,
commentstyle=\itshape\color{Gray},
stringstyle=\color{Black},
keywordstyle=\bfseries\color{OliveGreen},
identifierstyle=\color{blue},
xleftmargin=-8em,
}
\usepackage[colorlinks=true,linkcolor=blue]{hyperref}
\begin{document}
\tableofcontents
EOF
find . -type f ! -regex ".*/\..*" ! -name ".*" ! -name "*~" ! -name 'src2pdf'|
sed 's/^\..//' | ## Change ./foo/bar.src to foo/bar.src
while read i; do ## Loop through each file
name=${i//_/\\_} ## escape underscores
echo "\newpage" >> $tex_file ## start each section on a new page
echo "\section{$i}" >> $tex_file ## Create a section for each filename
## This command will include the file in the PDF
echo "\lstinputlisting[style=customasm]{$i}" >>$tex_file
done &&
echo "\end{document}" >> $tex_file &&
pdflatex $tex_file -output-directory . &&
pdflatex $tex_file -output-directory . ## This needs to be run twice
## for the TOC to be generated
ソースファイルを含むディレクトリでスクリプトを実行します
bash src2pdf
all.pdf というファイルが作成されます 現在のディレクトリに。システムで見つけたいくつかのランダムなソース ファイル (具体的には、vlc-2.0.0 のソースからの 2 つのファイル) でこれを試しました。 ) そして、これは結果の PDF の最初の 2 ページのスクリーンショットです:
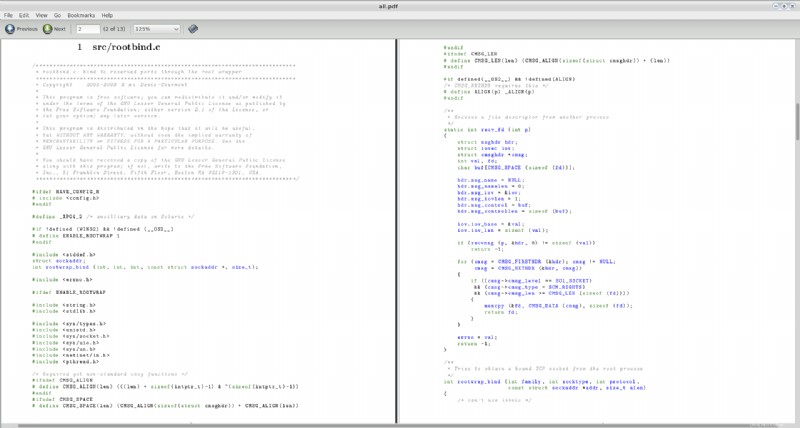
いくつかのコメント:
- ソース コード ファイル名にスペースが含まれていると、スクリプトは機能しません。ソース コードについて話しているので、そうではないと仮定します。
! -name "*~"を追加しました バックアップファイルを避けるため。-
より具体的な
findを使用することをお勧めします コマンドを使用してファイルを検索しないと、任意のランダム ファイルが PDF に含まれます。すべてのファイルに特定の拡張子 (.c) が付いている場合 と.h例)、findを置き換える必要があります。 このようなスクリプトでfind . -name "*\.c" -o -name "\.h" | sed 's/^\..//' | listingsで遊んでみる 必要に応じて正確に調整できます。
(StackOverflow から)
for i in *.src; do echo "$i"; echo "---"; cat "$i"; echo ; done > result.txt
これにより、以下を含む result.txt が生成されます:
- ファイル名
- セパレータ (---)
- .src ファイルの内容
- すべての *.src ファイルが完了するまで、先頭から繰り返します
ソース コードの拡張子が異なる場合は、必要に応じて変更してください。また、エコー ビットを編集して必要な情報を追加することもできます ("filename $1" をエコーするか、セパレータを変更するか、ファイルの終わりのセパレータを追加します)。
リンクには他の方法がありますので、好きな方法を使用してください。多少の学習曲線はありますが、これが最も柔軟だと思います。
コードは bash ターミナルから完全に実行されます (VirtualBox Ubuntu でテスト済み)
ファイル名を気にせず、マージされたファイルの内容だけを気にする場合:
cat *.src > result.txt
提案された別の方法は次のとおりです。
grep "" *.src > result.txt
これは、すべての行にファイル名のプレフィックスを付けます。これは、一部の人にとっては良いことですが、個人的には情報が多すぎると感じているため、最初の提案が上記の for ループである理由です。
StackOverflow フォーラムの人々に感謝します。
編集:最終結果として特にHTMLまたはPDFを求めていることに気付きました。私が見たいくつかの解決策は、テキストファイルをPostScriptに印刷してから、PostscriptをPDFに変換することです.私が見たいくつかのコード:
groff -Tps result.txt > res.ps
それから
ps2pdf res.ps res.pdf
(ghostscript が必要です)
これがお役に立てば幸いです。
遅すぎることはわかっていますが、解決策を探している人にはこれが役立つかもしれません。
@terdon の回答に基づいて、仕事をする BASH スクリプトを作成しました:https://github.com/eljuanchosf/source-code-to-pdf