まさにそれを行う perl ワンライナーを自分で書き、元の文字も出力します。 (STDIN からのファイルが必要です)
perl -C7 -ne 'for(split(//)){print sprintf("U+%04X", ord)." ".$_."\n"}'
ただし、これよりも優れた方法があるはずです。
いくつかの一般的なスマイリーのコード ポイントが必要で、これを思いつきました:
echo -n "" | # -n ignore trailing newline \
iconv -f utf8 -t utf32be | # UTF-32 big-endian happens to be the code point \
xxd -p | # -p just give me the plain hex \
sed -r 's/^0+/0x/' | # remove leading 0's, replace with 0x \
xargs printf 'U+%04X\n' # pretty print the code point
U+1F60A
これは「SMILING FACE WITH SMILING EYES」のコード ポイントです。
Neftas の回答に触発されて、単一の文字ではなく文字列で機能する少し単純なソリューションを次に示します。
iconv -f utf8 -t utf32le | hexdump -v -e '8/4 "0x%04x " "\n"' | sed -re"s/0x / /g"
# ^
# The number `8` above determines the number of columns in the output. Modify as needed.
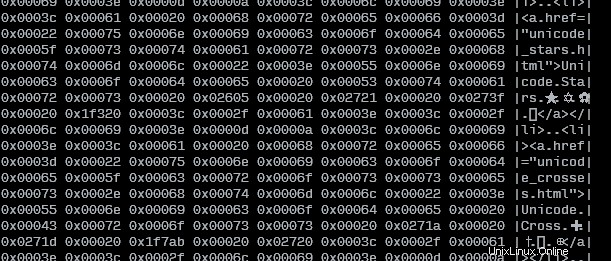
また、標準入力またはファイルから読み取り、Unicode 値とともに元のテキストを表示する Bash スクリプトも作成しました。
COLWIDTH=8
SHOWTEXT=true
tmpfile=$(mktemp)
cp "${1:-/dev/stdin}" "$tmpfile"
left=$(set -o pipefail; iconv -f utf8 -t utf32le "$tmpfile" | hexdump -v -e $COLWIDTH'/4 "0x%05x " "\n"' | sed -re"s/0x / /g")
if [ $? -gt 0 ]; then
echo "ERROR: Could not convert input" >&2
elif $SHOWTEXT; then
right=$(tr [:space:] . < "$tmpfile" | sed -re "s/.{$COLWIDTH}/|&|\n/g" | sed -re "s/^.{1,$((COLWIDTH+1))}\$/|&|/g")
pr -mts" " <(echo "$left") <(echo "$right")
else
echo "$left"
fi
rm "$tmpfile"