Java プロセスによって使用される仮想メモリは、Java ヒープだけではありません。 JVM には、ガベージ コレクター、クラス ローディング、JIT コンパイラなどの多くのサブシステムが含まれており、これらすべてのサブシステムが機能するには、一定量の RAM が必要です。
JVM は RAM の唯一の消費者ではありません。ネイティブ ライブラリ (標準の Java クラス ライブラリを含む) も、ネイティブ メモリを割り当てる場合があります。そして、これはネイティブ メモリ トラッキングからも見えません。 Java アプリケーション自体も、直接 ByteBuffers を使用してオフヒープ メモリを使用できます。
では、Java プロセスで何がメモリを消費するのでしょうか?
JVM パーツ (主にネイティブ メモリ トラッキングで表示)
<オール>
最も明白な部分。これは、Java オブジェクトが存在する場所です。ヒープは最大で -Xmx かかります
- ガベージ コレクター
GC 構造とアルゴリズムには、ヒープ管理用に追加のメモリが必要です。これらの構造は、Mark Bitmap、Mark Stack (オブジェクト グラフのトラバース用)、Remembered Sets (領域間参照の記録用) などです。それらのいくつかは直接調整可能です。 -XX:MarkStackSizeMax 、その他はヒープレイアウトに依存します。大きいほど G1 領域 (-XX:G1HeapRegionSize )、小さいほど記憶されたセットです。
GC メモリのオーバーヘッドは、GC アルゴリズムによって異なります。 -XX:+UseSerialGC と -XX:+UseShenandoahGC オーバーヘッドが最小です。 G1 または CMS は、合計ヒープ サイズの約 10% を簡単に使用する可能性があります。
- コード キャッシュ
動的に生成されたコードが含まれます:JIT コンパイルされたメソッド、インタープリター、およびランタイム スタブ。そのサイズは -XX:ReservedCodeCacheSize に制限されています (デフォルトでは 240M)。 -XX:-TieredCompilation をオフにする コンパイルされたコードの量を減らし、コード キャッシュの使用量を減らします。
- コンパイラ
JIT コンパイラー自体も、そのジョブを実行するためにメモリーを必要とします。階層化コンパイルをオフにするか、コンパイラ スレッドの数を減らすことで、これを再び減らすことができます:-XX:CICompilerCount .
- クラスの読み込み
クラスのメタデータ (メソッドのバイトコード、シンボル、定数プール、注釈など) は、Metaspace と呼ばれるオフヒープ領域に格納されます。より多くのクラスがロードされるほど、より多くのメタスペースが使用されます。総使用量は -XX:MaxMetaspaceSize で制限できます (デフォルトでは無制限) および -XX:CompressedClassSpaceSize (デフォルトでは 1G)。
- シンボル テーブル
JVM の 2 つの主要なハッシュテーブル:シンボル テーブルには名前、署名、識別子などが含まれ、文字列テーブルにはインターンされた文字列への参照が含まれます。ネイティブ メモリ トラッキングが文字列テーブルによる大量のメモリ使用を示している場合、アプリケーションが String.intern を過度に呼び出している可能性があります。 .
- スレッド
スレッド スタックは、RAM の使用も担当します。スタックサイズは -Xss によって制御されます .デフォルトはスレッドあたり 1M ですが、幸いなことにそれほど悪くはありません。 OS はメモリ ページを遅延して、つまり最初の使用時に割り当てるため、実際のメモリ使用量ははるかに少なくなります (通常、スレッド スタックあたり 80 ~ 200 KB)。 Java スレッド スタックに属する RSS の量を見積もるスクリプトを作成しました。
ネイティブ メモリを割り当てる JVM パーツは他にもありますが、通常、総メモリ消費量に大きな影響を与えることはありません。
直接バッファ
アプリケーションは、ByteBuffer.allocateDirect を呼び出してオフヒープ メモリを明示的に要求できます。 .デフォルトのオフヒープ制限は -Xmx です 、ただし -XX:MaxDirectMemorySize でオーバーライドできます . Direct ByteBuffers は Other に含まれています NMT 出力のセクション (または Internal JDK 11 より前)
使用された直接メモリの量は、JMX を介して表示されます。 JConsole または Java Mission Control で:
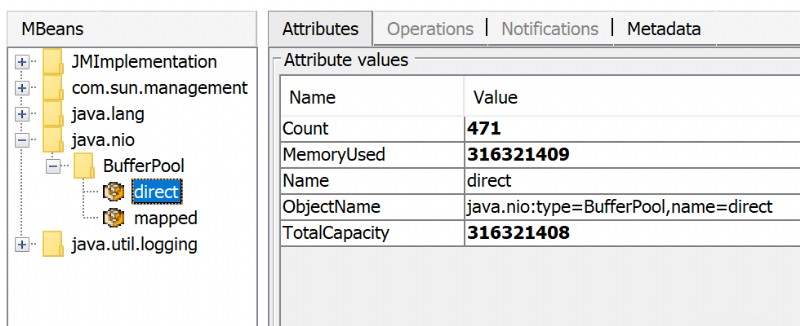
直接の ByteBuffers 以外に MappedByteBuffers がある場合があります - プロセスの仮想メモリにマップされたファイル。 NMT はそれらを追跡しませんが、MappedByteBuffers も物理メモリを使用できます。そして、摂取できる量を制限する簡単な方法はありません。プロセスメモリマップを見ると、実際の使用量を確認できます:pmap -x <pid>
Address Kbytes RSS Dirty Mode Mapping
...
00007f2b3e557000 39592 32956 0 r--s- some-file-17405-Index.db
00007f2b40c01000 39600 33092 0 r--s- some-file-17404-Index.db
^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^
ネイティブ ライブラリ
System.loadLibrary によって読み込まれた JNI コード JVM側からの制御なしで、必要なだけオフヒープメモリを割り当てることができます。これは、標準の Java クラス ライブラリにも関係します。特に、クローズされていない Java リソースは、ネイティブ メモリ リークの原因となる可能性があります。典型的な例は ZipInputStream です または DirectoryStream .
JVMTI エージェント、特に jdwp デバッグ エージェント - 過度のメモリ消費を引き起こす可能性もあります。
この回答では、async-profiler を使用してネイティブ メモリ割り当てをプロファイリングする方法について説明しています。
アロケータの問題
プロセスは通常、OS から直接 (mmap によって) ネイティブ メモリを要求します。 システムコール) または malloc を使用して - 標準の libc アロケータ。次に、malloc mmap を使用して OS から大量のメモリを要求します 、独自の割り当てアルゴリズムに従ってこれらのチャンクを管理します。問題は、このアルゴリズムが断片化と過剰な仮想メモリの使用につながる可能性があることです。
jemalloc 代替アロケータである は、通常の libc malloc よりもスマートに見えることがよくあります。 、だから jemalloc に切り替える 無料でフットプリントが小さくなる可能性があります。
結論
考慮すべき要素が多すぎるため、Java プロセスの完全なメモリ使用量を推定する保証された方法はありません。
Total memory = Heap + Code Cache + Metaspace + Symbol tables +
Other JVM structures + Thread stacks +
Direct buffers + Mapped files +
Native Libraries + Malloc overhead + ...
JVM フラグによって特定のメモリ領域 (コード キャッシュなど) を縮小または制限することは可能ですが、他の多くの領域は JVM の制御からまったく外れています。
Docker の制限を設定する 1 つの可能なアプローチは、プロセスの「通常の」状態で実際のメモリ使用量を監視することです。 Java メモリ消費に関する問題を調査するためのツールと手法があります:ネイティブ メモリ トラッキング、pmap、jemalloc、async-profiler。
更新
これは、Java プロセスのメモリ フットプリントに関するプレゼンテーションの記録です。
このビデオでは、Java プロセスでメモリを消費する可能性があるもの、特定のメモリ領域のサイズを監視および制限する方法、Java アプリケーションでネイティブ メモリ リークをプロファイリングする方法について説明します。
https://developers.redhat.com/blog/2017/04/04/openjdk-and-containers/:
<ブロック引用>-Xmx=1g を指定すると、JVM が 1gbof メモリよりも多くのメモリを使用するのはなぜですか?
-Xmx=1g を指定すると、JVM に 1GB のヒープを割り当てるように指示されます。 JVM に全体のメモリ使用量を 1 GB に制限するように指示しているわけではありません。カード テーブル、コード キャッシュ、およびその他のあらゆる種類のオフ ヒープ データ構造があります。合計メモリ使用量を指定するために使用するパラメータは、-XX:MaxRAM です。 -XX:MaxRam=500m の場合、ヒープは約 250MB になることに注意してください。
Java はホストのメモリ サイズを認識し、コンテナのメモリ制限を認識しません。メモリ プレッシャが発生しないため、GC は使用済みメモリを解放する必要もありません。 XX:MaxRAMを願っています メモリフットプリントを削減するのに役立ちます。最終的には、GC 構成を微調整できます (-XX:MinHeapFreeRatio ,-XX:MaxHeapFreeRatio 、...)
多くの種類のメモリ メトリックがあります。 Docker が RSS メモリ サイズを報告しているようです。これは、jcmd によって報告された「コミットされた」メモリとは異なる場合があります。 (Docker の古いバージョンでは、メモリ使用量として RSS+cache が報告されます)。良い議論とリンク:Docker コンテナで実行されている JVM の常駐セット サイズ (RSS) と Java 合計コミット メモリ (NMT) の違い
(RSS) メモリは、コンテナー内の他のユーティリティ (シェル、プロセス マネージャーなど) によっても消費される可能性があります。コンテナー内で他に何が実行されているのか、コンテナー内でプロセスを開始する方法はわかりません。
TL;DR
メモリの詳細な使用状況は、Native Memory Tracking (NMT) の詳細 (主にコード メタデータとガベージ コレクター) によって提供されます。それに加えて、Java コンパイラーとオプティマイザー C1/C2 は、要約で報告されていないメモリーを消費します。
JVM フラグを使用してメモリ フットプリントを削減できます (ただし影響はあります)。
Docker コンテナのサイジングは、アプリケーションに予想される負荷でテストして行う必要があります。
各コンポーネントの詳細
共有クラス スペース クラスは別の JVM プロセスによって共有されないため、コンテナー内で無効にすることができます。次のフラグを使用できます。共有クラス スペース (17MB) が削除されます。
-Xshare:off
ガベージ コレクター serial は、ガベージ コレクション処理中の一時停止時間が長くなる代わりに、最小限のメモリ フットプリントしかありません (1 つの図で GC を比較した Aleksey Shipilëv を参照)。次のフラグで有効にできます。使用される GC スペース (48MB) まで節約できます。
-XX:+UseSerialGC
C2 コンパイラ メソッドを最適化するかどうかを決定するために使用されるプロファイリング データを減らすために、次のフラグで無効にすることができます。
-XX:+TieredCompilation -XX:TieredStopAtLevel=1
コードスペースは 20MB 削減されます。さらに、JVM の外部メモリは 80MB 削減されます (NMT 空間と RSS 空間の差)。 最適化コンパイラ C2 には 100MB が必要です。
C1 および C2 コンパイラ 次のフラグで無効にできます。
-Xint
JVM の外部のメモリは、コミットされた合計スペースより少なくなりました。コードスペースは 43MB 削減されます。これは、アプリケーションのパフォーマンスに大きな影響を与えることに注意してください。 C1 および C2 コンパイラを無効にすると、使用されるメモリが 170 MB 削減されます。
Graal VM コンパイラの使用 (C2 の置換) により、メモリ フットプリントが少し小さくなります。コード メモリ空間が 20MB 増加し、外部 JVM メモリから 60MB 減少します。
記事「JVM の Java メモリ管理」では、さまざまなメモリ空間に関する関連情報が提供されています。Oracle では、ネイティブ メモリ トラッキングのドキュメントで詳細を提供しています。高度なコンパイル ポリシーと C2 の無効化のコンパイル レベルに関する詳細は、コード キャッシュ サイズを 5 分の 1 に減らします。両方のコンパイラが無効になっている場合。