2020 年に回答を更新 :
@Owen の回答によると、ORC は独自の Apache プロジェクトとして成長し、成熟しました。 ORC 採用者の完全なリストは、現在、さまざまな種類のビッグ データ テクノロジでサポートされていることを示しています。
@Owen と ORC Apache プロジェクト チームの功績によると、ORC のプロジェクト サイトには、Linux ローカル ファイル システムに保存された ORC ファイルで Java または C++ スタンドアロン ツールを使用する方法に関する完全に維持された最新のドキュメントがあります。これは、元の Hive+ORC Apache wiki ページのたいまつを引き継いだものです。
元の回答の日付:May 30 '14 at 16:27
ORC ファイル ダンプ ユーティリティには、ハイブ (0.11 以降) が付属しています:
hive --orcfiledump <hdfs-location-of-orc-file>
ソースリンク
また、Linux で実行されているデスクトップ アプリケーションで ORC ファイルの内容を表示することもできます。
Parquet や、ORC や AVRO などの他のバイナリ形式のデータを表示するデスクトップ アプリケーションがあります。これは純粋な Java アプリケーションであるため、Linux、Mac、および Windows でも実行できます。詳しくは Bigdata File Viewer をご確認ください。
配列、マップ、構造体などの複雑なデータ型をサポートします。
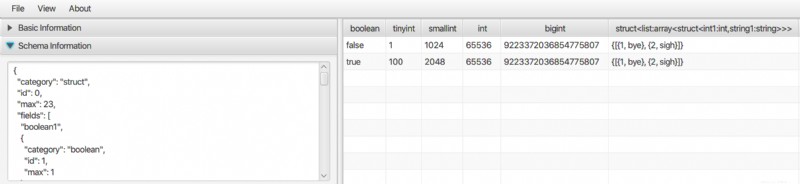
また、orc ファイルの内容を JSON で出力する Linux および MacOS 用のネイティブ実行可能ファイルもあります。 ORC プロジェクト (http://orc.apache.org/) を参照して、C++ ツールをビルドしてください。
% orc-contents examples/TestOrcFile.test1.orc
ネイティブのメタデータ ツールもあります:
% orc-metadata ../examples/TestOrcFile.test1.orc
ORC プロジェクトには、Java から同じことができるスタンドアロンの uber jar もあります。
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc