プロファイラーを使用することが目標である場合は、提案されているもののいずれかを使用してください。
ただし、急いでおり、主観的に遅いプログラムをデバッガーで手動で中断できる場合は、パフォーマンスの問題を見つける簡単な方法があります。
数回停止し、そのたびにコール スタックを確認します。 20% や 50% などの時間の割合を無駄にしているコードがある場合、それは各サンプルの動作でそれを検出する確率です。したがって、それはおおよそ、それが表示されるサンプルのパーセンテージです。知識に基づく推測は必要ありません。何が問題なのか推測できる場合は、それが証明または反証されます。
さまざまなサイズの複数のパフォーマンスの問題が発生する場合があります。それらのいずれかを一掃すると、残りのパーセンテージが大きくなり、その後のパスで見つけやすくなります。この拡大効果 、複数の問題を組み合わせると、本当に大幅なスピードアップ要因になる可能性があります。
注意 :プログラマーは、自分で使用したことがない限り、この手法に懐疑的です。プロファイラーがこの情報を提供すると彼らは言うでしょうが、それは呼び出しスタック全体をサンプリングし、サンプルのランダムなセットを調べさせた場合にのみ当てはまります。 (要約では、洞察が失われます。) コール グラフでは同じ情報が得られません。なぜなら、
<オール>彼らはまた、おもちゃのプログラムでのみ機能すると言いますが、実際にはどのプログラムでも機能し、より大きなプログラムではよりうまく機能するようです。問題ではないものを見つけることもあると言われますが、それは一度何かを見た場合にのみ当てはまります .複数のサンプルで問題が見られる場合、それは本物です。
追伸 これは、Java のようにある時点でスレッド プールのコール スタック サンプルを収集する方法があれば、マルチスレッド プログラムでも実行できます。
追伸 大まかな一般論として、ソフトウェアの抽象化レイヤーが多いほど、それがパフォーマンスの問題の原因であることに気付く可能性が高くなります (そして、スピードアップの機会が得られます)。
追加 :明らかではないかもしれませんが、スタック サンプリング手法は、再帰が存在する場合でも同様に機能します。その理由は、命令を削除することによって節約される時間は、サンプル内で発生する可能性がある回数に関係なく、命令を含むサンプルの割合によって概算されるためです。
私がよく耳にするもう 1 つの反論は次のとおりです。 「.これは、本当の問題が何であるかについての事前の概念を持つことから来ます.パフォーマンスの問題の重要な特性は、期待に反することです.サンプリングは何かが問題であることを伝え、最初の反応は信じられないことです.それは自然なことですが、あなたはできる問題が見つかった場合はそれが本物であることを確認し、その逆も同様です。
追加 :それがどのように機能するかをベイズ的に説明しましょう。命令 I があるとします。 (呼び出しまたはその他) コール スタックにある分数 f 時間の(したがって、それだけの費用がかかります)。簡単にするために、f が何かわからないとします。 ただし、0.1、0.2、0.3、... 0.9、1.0 のいずれかであり、これらの可能性のそれぞれの事前確率が 0.1 であると仮定すると、これらのコストはすべてアプリオリに等しくなる可能性があります。
次に、スタック サンプルを 2 つだけ取得すると、命令 I が表示されます。 両方のサンプルで、観察 o=2/2 を指定 .これにより、頻度 f の新しい見積もりが得られます I の 、これによると:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
最後の列は、たとえば f の確率が>=0.5 は 92% で、以前の仮定の 60% から上昇しています。
事前の仮定が異なるとします。 P(f=0.1) と仮定するとします。 .991 (ほぼ確実) であり、他のすべての可能性はほとんど不可能です (0.001)。言い換えれば、私たちの以前の確信は I 安いです。次に取得します:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
P(f >= 0.5) と表示されるようになりました は 26% で、以前の想定の 0.6% から上昇しています。したがって、ベイズにより、I の推定コストの見積もりを更新できます。 .データ量が少ない場合、修正する価値があるほど十分に大きいというだけで、コストが正確にわかりません。
それを見るさらに別の方法は、継承のルールと呼ばれます。コインを 2 回投げて、2 回とも表が出る場合、そのコインの重み付けの可能性について何がわかりますか?平均値 (number of hits + 1) / (number of tries + 2) = (2+1)/(2+2) = 75% のベータ版ディストリビューションだと言う .
(重要なのは、I が表示されることです 一回以上。 1 回しか表示されない場合、f 以外はあまりわかりません。> 0.)
したがって、非常に少数のサンプルでも、命令のコストについて多くのことを知ることができます。 (そして、平均して、コストに比例した頻度でそれらを確認します。If n サンプルが取得され、f はコスト、I nf+/-sqrt(nf(1-f)) に表示されます サンプル。例、n=10 、 f=0.3 、つまり 3+/-1.4 です サンプル)
追加 :測定とランダム スタック サンプリングの違いを直感的に理解するには:
現在、実時間でもスタックをサンプリングするプロファイラーがありますが、結果は 測定値 (または「ボトルネック」を簡単に隠すことができるホット パスまたはホット スポット) です。彼らがあなたに見せていない (そして彼らは簡単に見せてくれた) ものは、実際のサンプルそのものです。そして、あなたの目標が見つけることなら ボトルネック、確認する必要があるそれらの数は、平均 , 2 をかかる時間の割合で割ったものです。したがって、30% の時間がかかる場合、平均で 2/.3 =6.7 サンプルで表示され、20 サンプルで表示される可能性は 99.2% です。
これは、測定値の調査とスタック サンプルの調査の違いを簡単に示したものです。ボトルネックは、このような 1 つの大きな塊である場合もあれば、多数の小さな塊である場合もありますが、違いはありません。
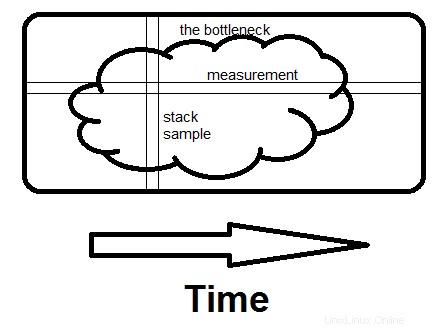
測定は水平です。特定のルーチンにかかる時間の割合を示します。サンプリングは垂直です。その時点でプログラム全体が行っていることを回避する方法がある場合、2 番目のサンプルでそれが見られる場合 、ボトルネックを発見しました。それが違いを生むのです - どれだけ時間が費やされているかだけでなく、費やされた理由全体を見てください.
次のオプションで Valgrind を使用できます
valgrind --tool=callgrind ./(Your binary)
callgrind.out.x というファイルが生成されます .その後、 kcachegrind を使用できます このファイルを読み取るためのツール。それは、どの回線がいくらかかるかなどの結果を含む物事のグラフィカルな分析を提供します.
GCCを使用していると思います。標準的な解決策は、gprof でプロファイリングすることです。
必ず -pg を追加してください プロファイリング前のコンパイル:
cc -o myprog myprog.c utils.c -g -pg
まだ試していませんが、google-perftools について良いことを聞いています。ぜひ試してみる価値があります。
関連する質問はこちら
gprof の場合のその他の流行語 Valgrind、Intel VTune、Sun DTrace.