PDF は、現在、情報を伝達するための最も一般的な形式の 1 つであり、これらの PDF ファイルを操作する必要があることがよくあります。さまざまな目的で PDF ファイルの一部を画像として取得することは、非常に一般的な現象です。 Linux ディストリビューションでは、PDF をイメージに簡単に変換できます。ここで画像ファイルの種類を指定することもできます。 PDF のページ番号に応じて、PDF 全体を複数の画像に変換できます。また、特定のページも変換できます。必要に応じて、それらの中から誰でも選択できます。柔軟に選択できます。
Linux システムでの PDF から画像への変換
前述したように、PDF をいくつかの形式の画像に変換できます。それは、取得したい出力のタイプにのみ依存します。心配しないでください!この投稿では、Linux システムで PDF を画像に変換する方法を説明します。
そのためには、Linux システムに必須のものをいくつか用意する必要があります。 bash または任意のシェルが必要です。出力ファイルをエクスポートする任意のアプリ。また、作業を行うにはいくつかのコマンドを知っている必要があります。詳しく見てみましょう。
1. 「pdftoppm」コマンドの使用
最初に紹介する方法は、「pdftoppm」コマンドを使用する方法です。このコマンドにアクセスするには、コンピューターに「poppler」ツールが必要です。
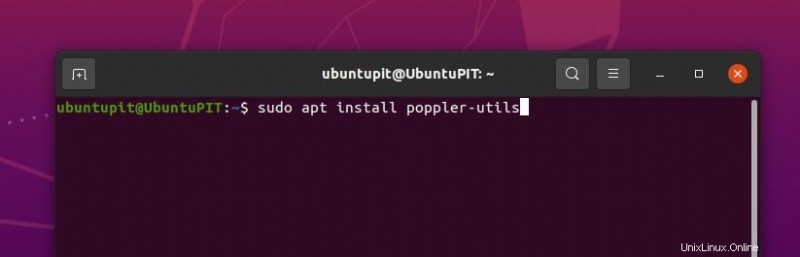
- Debian または Ubuntu の場合、poppler ユーティリティをインストールするコマンドは次のとおりです:
sudo apt install poppler-utils
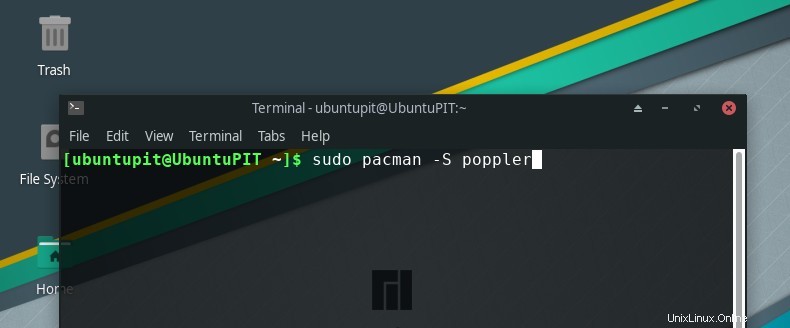
- Arch Linux の場合、ターミナルで次のコマンドを記述する必要があります:
sudo pacman -S poppler
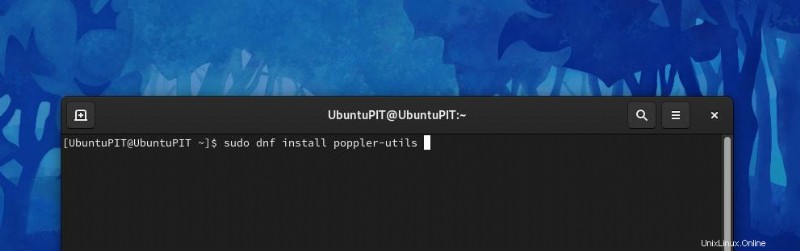
- また、RedHat または CentOS の場合、コマンドは次のようになります:
sudo dnf install poppler-utils
poppler をインストールすると、Ubuntu、Debian ベース、または Arch Linux のいずれかの Linux ディストリビューションで、残りの構文はそれぞれで同じになります。 PDFファイルはさまざまな方法で変換できます。それぞれについて以下で説明します。
a. PDF 全体を画像に変換
この手順では、PDF ファイル全体が画像に変換されます。画像ファイルの種類も選択できます。まず、「pdftoppm」コマンドを使用する必要があります。次に、画像形式を指定します。その後、PDF ファイル名と出力名をそれぞれ記述します。
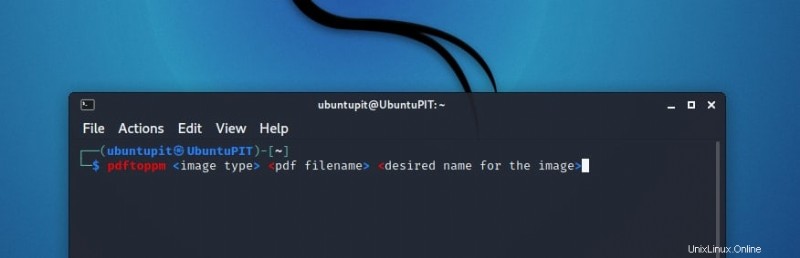
そのための理想的な構文は次のとおりです:
pdftoppm <image type> <pdf filename> <desired name for the image>
たとえば、「Sample.pdf」という名前の PDF があります。では、その PDF 全体を画像に変換するにはどうすればよいでしょうか。ターミナルに書き込むだけです:
pdftoppm -jpeg Sample.pdf images_extracted_from_sample_pdf
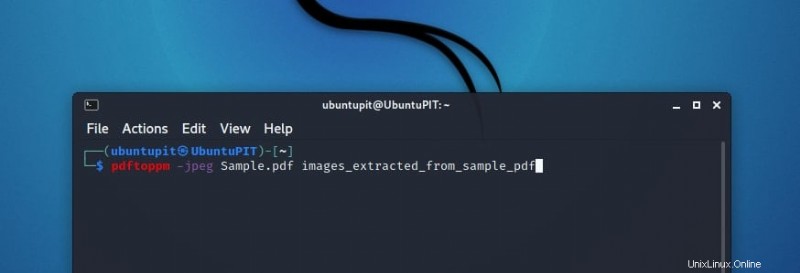
画像の種類は、png などの任意の種類の拡張子にすることができます。ここで重要な点に注意してください。 .jpg ではなく、.jpeg と書く必要があります。短い形式で書くと、ここでエラーが発生します。
PDF ファイルの各ページが jpeg タイプの写真に変換されます。最初のページは「images_extracted_from_sample_pdf-1.jpeg」という名前になります 」、2 番目のものは「images_extracted_from_sample_pdf-2.jpeg」という名前になります
b.大量のページを PDF から画像に変換
PDF ファイル全体を変換する必要はないとしましょう。特定のページのみが画像に変換されます。その方法は?
構文はかなりの名前です。ここに表示される唯一の違いは、変換するページ番号の範囲を指定する必要があることです。
pdftoppm <image type> -f sn -l ln <pdf filename> <desired name for the image>
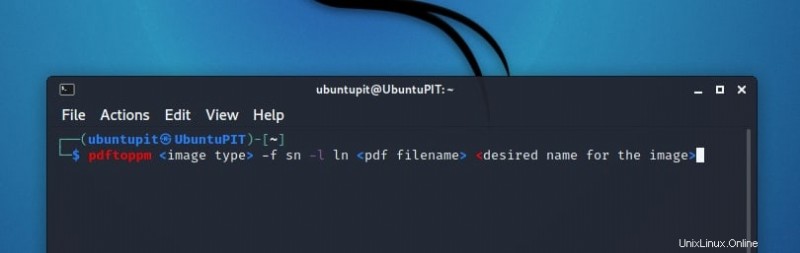
ここで、sn は開始ページ番号を表し、ln は最後のページ番号を表します。
前のセクションで取得した同じ PDF ファイルの 9 ページから 12 ページに変換します。構文は次のようになります:
pdftoppm -jpeg -f 9 -l 12 Sample.pdf images_extracted_from_sample_pdf
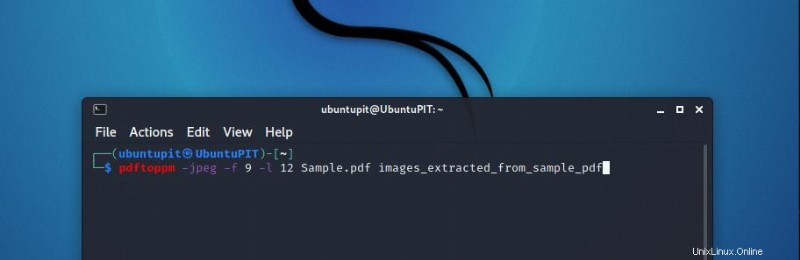
出力名は images_extracted_from_sample_pdf-9.jpeg のようになり、12 までカウントされます。
c. PDF から画像への単一ページの変換
実際、これは最後に見た手順の派生物です。単一ページを変換する構文は同じです。今回は、開始ページ番号と終了ページ番号が同じ数値になります。
pdftoppm <image type> -f x -l x <pdf filename> <desired name for the image>
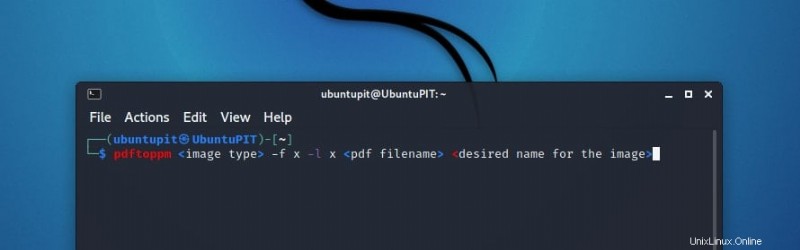
ここで、x は PDF に変換するページ番号を表します。 5 番目のページを変換する場合は、次のように記述する必要があります。
pdftoppm -jpeg -f 5 -l 5 Sample.pdf images_extracted_from_sample_pdf
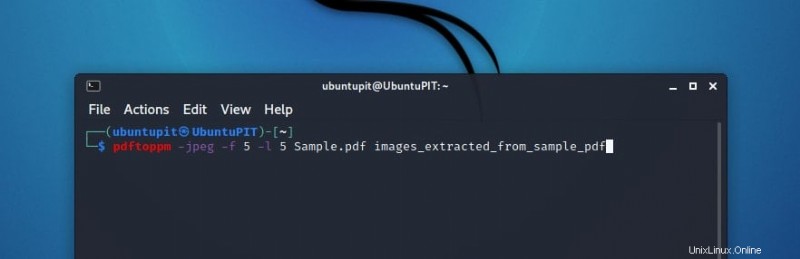
ここで作成される画像ファイルは 1 つだけです。
d.変換された画像ファイルのカスタマイズされた品質
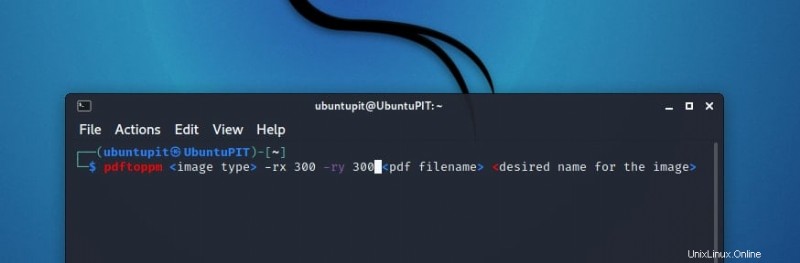
表示される各画像には、その画像に関連する DPI (ドット パー インチ) 値があります。通常、DPI 値が増加すると、画質も向上しますが、大きなスペースが必要になり、その逆も同様です。画像の DPI 値を制御する必要がある場合があります。それを制御する方法は?構文をよく見てください。
pdftoppm <image type> -rx 300 -ry 300 <pdf filename> <desired name for the image>
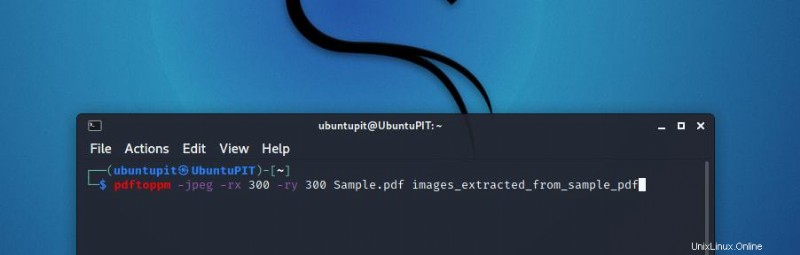
pdftoppm コマンドは、デフォルトで DPI 値が 150 であることを前提としています。これを変更するには、両方の軸の解像度を個別に設定する必要があります。 X 解像度を 300 に、Y 解像度も 350 に設定したいとします。そのためには、-rx および -ry コマンドを使用する必要があります。
以前に使用したファイルの構文は次のようになります:
pdftoppm -jpeg -rx 300 -ry 300 Sample.pdf images_extracted_from_sample_pdf
2. 「変換」コマンドの使用
「convert」コマンドを使用して、Linux システムで PDF を画像に変換することもできます。お使いのコンピューターで convert コマンドを有効にするには、まず ImageMagick をインストールする必要があります。オペレーティング システムによって、Imagemagick のインストールの構文は異なります。
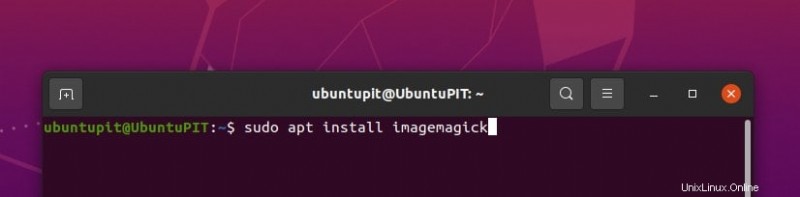
- コンピューターに Ubuntu または Debian ベースのオペレーティング システムがある場合は、シェルを開いて次のように記述します。
sudo apt install imagemagick
- 実行中のオペレーティング システムが RedHat ベースまたは CentOS ベースの場合、最初に、Imagemagick の前提条件として、php-devel、gcc、および php-pear をインストールする必要があります。そのためには、次のように記述してください:
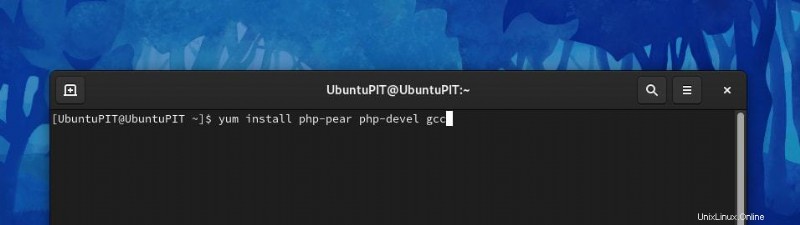
yum install php-pear php-devel gcc
これで、コンピューターに ImageMagic をインストールする準備が整いました。シェルに次の行を記述します:
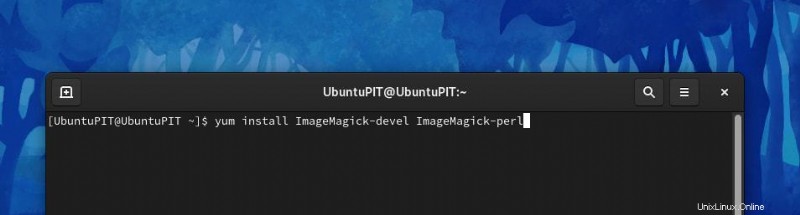
yum install ImageMagick-devel ImageMagick-perl
次のポイントは、ImageMagick の PHP 拡張機能をインストールする必要があるということです。
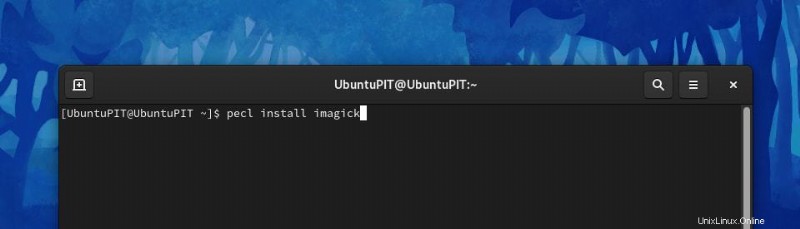
pecl install imagick
そして、最後のステップです。
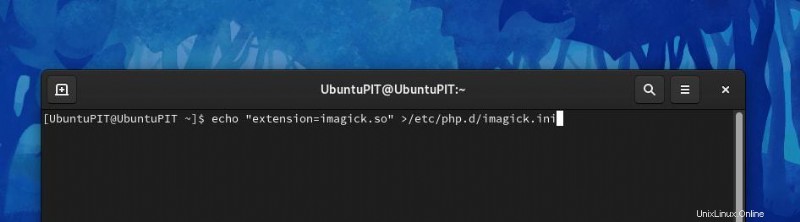
echo “extension=imagick.so” > /etc/php.d/imagick.ini
CentOS または Red Hat の最新バージョンでは、ImageMagick は使用できなくなり、GraphicsMagick に置き換えられました。それをインストールするには、書き留めてください:
dnf info GraphicsMagick
その後、これを完了してください。
dnf install GraphicsMagick GraphicsMagick-devel GraphicsMagick-perl
- Arch Linux を実行しているコンピューターで、ターミナルを開いて書き込み
sudo pacman -S imagemagick

ImageMagick をインストールすると、convert コマンドを使用する準備が整います。
a.ファイル全体を画像に変換
pdftoppm コマンドと同様に、どの Linux ディストリビューションでも、構文は convert コマンドを使用する場合と同じです。一般的な構文は次のとおりです:
convert <pdf filename> <desired name for the image>.<image type>
たとえば、Sample.pdf という名前の PDF があり、それを png タイプの画像に変換したいとします。そのための構文は次のとおりです:
convert Sample.pdf images_extracted_from_sample_pdf.png
抽出された画像の命名形式は、pdftoppm コマンドと同じです。
b.ドキュメントから単一ページを画像に変換
1 ページを画像に変換するには、端末から次の構文を実行します:
convert <pdf filename><page number> <desired name for the image>.<image type>
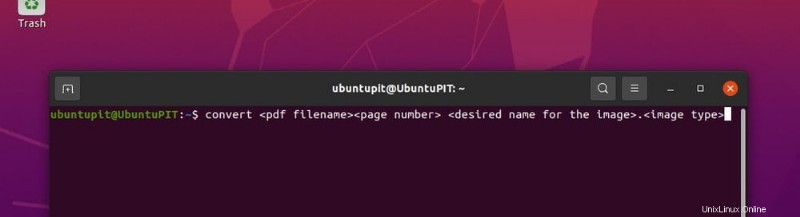
Sample.pdf の 10 ページ目を変換するには、次のように記述する必要があります。
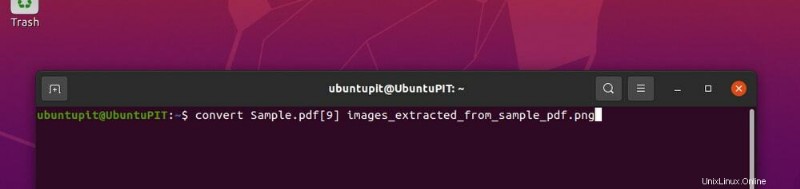
convert Sample.pdf[9] images_extracted_from_sample_pdf.png
重要な注意: ページの番号付けは、ゼロベースの番号付けシステムで行われます。したがって、PDF の最初のページは 0 として番号が付けられ、残りはそこからカウントされます。
c.変換された画像の品質のカスタマイズ
DPI (Dot Per Inch) と圧縮は、convert コマンドを使用して設定できます。両方とも一緒に見ます.
convert -density <DPI value> <pdf filename> -quality <Compression value> <desired name for the image>.<image type>
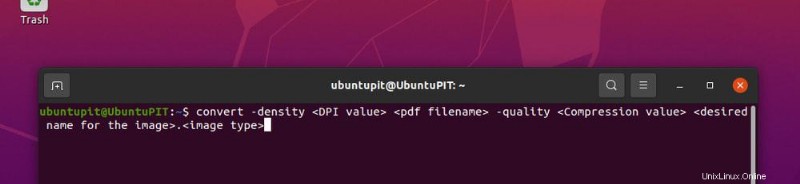
Sample.pdf を圧縮なしで 300 DPI の png タイプの画像に変換するには、コマンド ライン構文は次のようになります。
convert -density 300 Sample.pdf -quality 100 images_extracted_from_sample_pdf.png
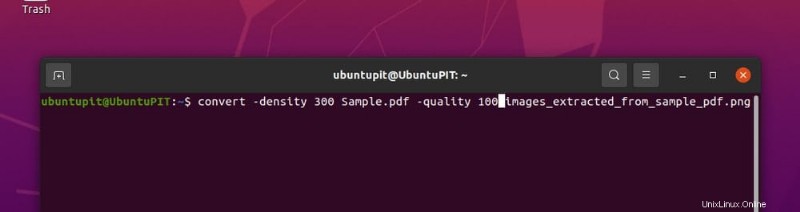
ここで、100 は圧縮を行わないことを意味します。値を 100 未満の任意の数値に設定して、対応するレベルの圧縮を取得できます。
3. GIMP (GNU 画像操作プログラム) を使用して PDF を画像に変換する
GIMP は、どのディストリビューションでも画像を操作できる素晴らしいソフトウェアです。 GIMP をインストールするには、以下の簡単な手順に従ってください。
- Debian または Ubuntu ベースの OS の場合は、ターミナルを開いて次のように記述します:
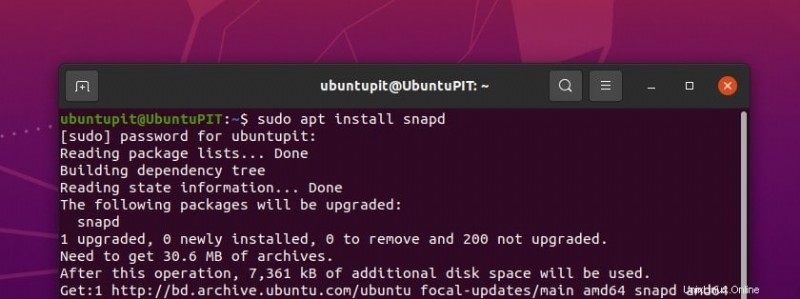
sudo apt install snapd
これが完了したら、GIMP をインストールします。
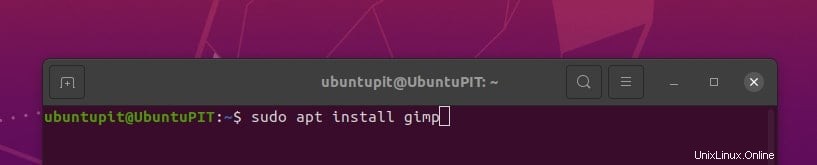
sudo apt install gimp
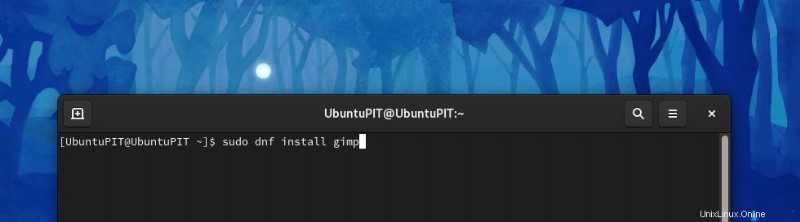
- CentOS または RHEL 8 の場合、構文は次のとおりです:
sudo dnf install gimp
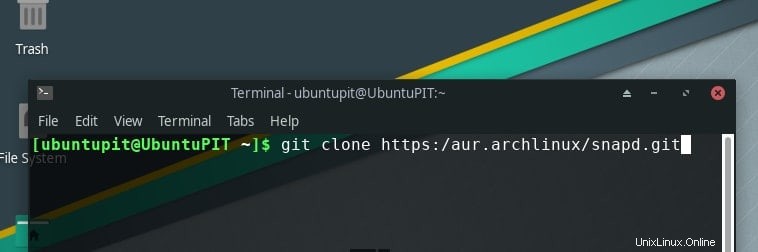
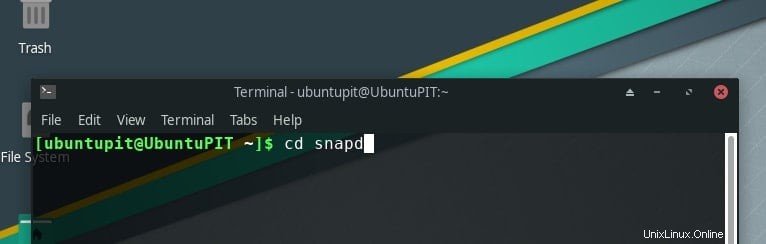
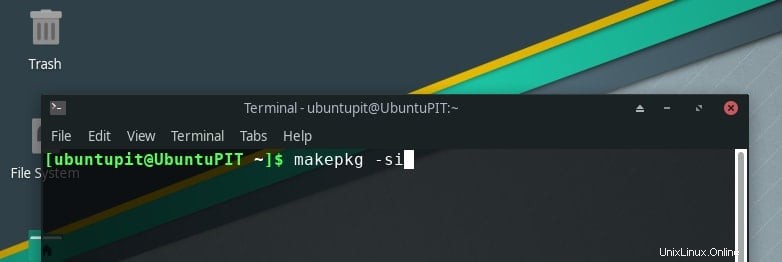
- また、Arch Linux の場合、手順はそれほど単純ではありません。まず、スナップ リポジトリをインストールしてから、そこから GIMP をインストールする必要があります。次の指示をそれぞれ書きます。
git clone https://aur.archlinux/snapd.git cd snapd makepkg -si
/snap へのシンボリック リンクを作成する必要があります。 ディレクトリ。
sudo systemctl enable --now snapd.socket
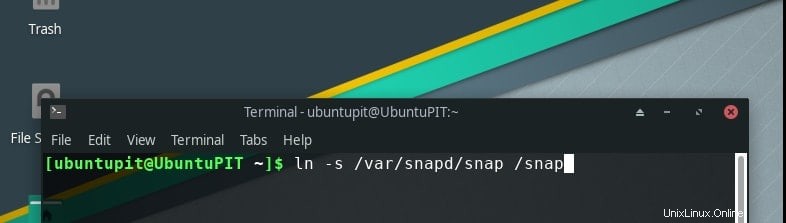
ln -s /var/lib/snapd/snap /snap
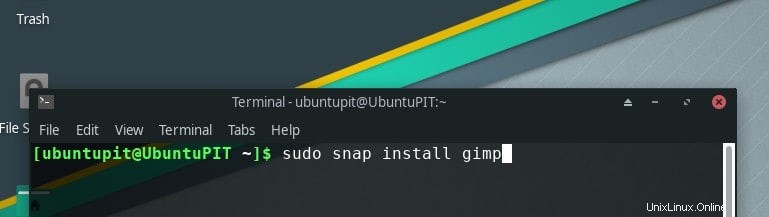
そして、ここで最後のステップに進みます…
sudo snap install gimp
この時点で、GIMP がコンピューターにインストールされており、GIMP を使用する準備ができています。 GIMP フォーム アプリケーション マネージャーを開きます。 「ファイル」オプションに移動し、「開く」をクリックします。このウィンドウから、変換したいドキュメントを検索します。それを選択して先に進みます。
編集メニューからファイルにさまざまな変更を適用できます。 GIMP を使用してファイルを操作することは、この投稿の範囲外のまったく別のトピックです。操作後、再び「ファイル」オプションに移動し、「名前を付けてエクスポート」をクリックします。必要に応じて延長タイプをお選びいただけます。 「エクスポート」をクリックして完了です。
まとめ
これで終わりです。ここでは、PDF ドキュメントを Linux システム用の画像に変換する方法を見てきました。これを行うためのいくつかの手法について説明しましたが、それぞれが効率的で実り多いものです。最も一般的な方法は、柔軟性があるため pdftoppm を使用することです。あなたの仕事に応じて、それらのどれでも行くことができます.
変換作業中に直面した提案や問題など、投稿についてコメントを残してください。また、ここで取り上げるべきものを見逃した場合は、遠慮なくお知らせください。こんにちは!