スピーチは、電子デバイスと対話するための現代の人気のあるスマートな方法です。ご存知のように、さまざまなプラットフォームで利用できるオープン ソースの音声認識ツールが多数あります。この技術は当初から、人間の声を理解する上で同時に改善されてきました。これがまさにその理由だ;今では以前よりも多くの専門家を巻き込んでいます。技術的進歩は、一般の人々にとってそれをより明確にするのに十分強力です.
オープンソースの音声認識ツール
オープンソースの音声認識ツールは、Linux プラットフォームで日常生活で使用する典型的なソフトウェアのようにあまり利用できません。長い調査の結果、いくつかの優れた機能を備えたアプリケーションと簡単な説明を見つけました。以下のポイントを見ていきましょう!
1.カルディ
Kaldi は、ジョン ホプキンス大学のプロジェクトの一環として開始された特殊な種類の音声認識ソフトウェアです。このツールキットには、拡張可能な設計が付属しており、C++ プログラミング言語で記述されています。 Kaldi の機能を強化するための多くの拡張機能を使用して、柔軟で快適な環境をユーザーに提供します。
カルディの注目すべき機能
- Apache ライセンスに基づく、無料で柔軟なオープン ソースの音声認識アプリケーション。
- GNU/Linux、BSD、Microsoft Windows など、複数のプラットフォームで動作します。
- システムへのアプリケーションのインストールと構成をサポートします。
- 音声認識システムに加えて、ディープ ニューラル ネットワークと線形変換もサポートしています。
2. CMUSphinx
CMUS Sphinx には、音声認識に関連するいくつかのビルド済みパッケージを備えた機能強化システムのグループが付属しています。カーネギーメロン大学で開発されたオープンソースプログラムです。この話者に依存しない認識ツールは、フランス語、英語、ドイツ語、オランダ語など、複数の言語で入手できます。

CMUSphinx の注目すべき機能
- 使いやすいインターフェイスを備えた、使いやすく高速な音声認識システムです。
- リソースの少ないプラットフォームでも、柔軟な設計と効率的なシステムが付属しています。
- Sphinxtrain パッケージを通じて音響モデル トレーニング ツールを提供します。
- キーワード スポッティング、発音評価、アラインメントなどの便利なパッケージを使用して、さまざまな種類のタスクを実行するのに役立ちます。
- これは、Windows システムと Linux システムの両方をサポートするクロスプラットフォーム ツールです。
3.ディープスピーチ
DeepSpeech は、音声をテキストに変換するオープン ソースの音声認識エンジンです。 Mozilla による無料のアプリケーションです。デバイスで DeepSearch プロジェクトを実行するには、Python 3.r 以降が必要です。また、Git 拡張ファイル、つまり Git Large File Storage も必要です。システムに対して実行する際に、大きなファイルのバージョン管理に使用されます。
DeepSpeech の注目すべき機能
- DeepSpeech は TensorFlow フレームワークを使用して、音声変換をより快適にします。
- NVIDIA GPU をサポートしているため、より迅速な推論を実行できます。
- DeepSearch 推論は 3 つの異なる方法で使用できます。 Python パッケージ、Node.JS パッケージ、またはコマンドライン クライアント。
- このソフトウェアをシステムで実行するたびに、Python コマンドで仮想環境を有効にする必要があります。
- このアプリケーションを実行するには Linux または Mac 環境が必要です。
4. Wav2レター++
WavLetter++ は、Facebook の AI 研究チームによって開発された最新の人気のある音声認識ツールです。これは、BCD ライセンスに基づく別のオープン ソース プログラムです。この超高速音声認識ソフトウェアは C++ で構築され、多くの機能が導入されています。柔軟な環境で、言語モデリング、機械翻訳、音声合成などの機能をユーザーに提供します。
Wav2Letter++ の注目すべき機能
- 世界中のユーザーを支援するために、Facebook や Google グループなどの人気のあるプラットフォームでアクティブなコミュニティが含まれています。
- WavLetter++ は、最大限の効率を得るために ArrayFire テンソル ライブラリを使用する高速で柔軟なツールキットです。
- wav2letter++ のような高性能フレームワークを使用できるため、研究やモデルのチューニングを成功させるのに役立ちます。
- また、チュートリアル セクションを通じて完全なドキュメントを提供します。
- レシピ フォルダには、WSJ、ティミット、Librispeech の詳細なレシピがあります。
5.ジュリアス
Julius は Lee Akinobu 氏によって開発された比較的古いオープン ソースの音声認識ソフトウェアです。このツールは、京都大学川原研究室の開発者によって C プログラミング言語で書かれています。ボキャブラリーが豊富で高性能な音声認識アプリです。英語と日本語の両方で使用できます。学術的および研究目的で使用する場合は、優れた選択肢となります。
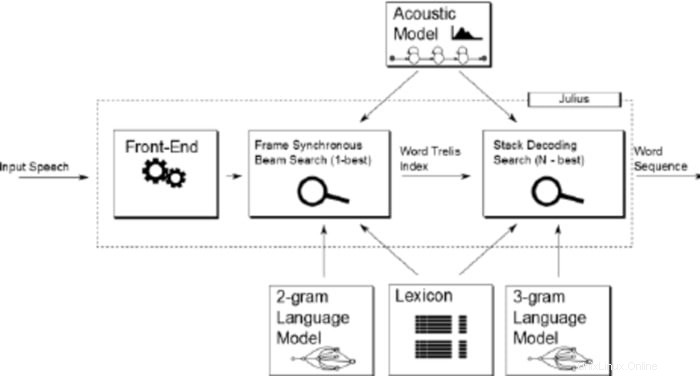
Julius の注目すべき機能
- Julius は、パフォーマンスを調整するためにさまざまな検索パラメーターを設定できる高度に構成可能なアプリケーションです。
- このツールは、リアルタイムで高品質のパフォーマンスを提供する 2 パス戦略に基づいています。
- これは、Linux、BSD、Windows、および Android システムで実行されるクロスプラットフォーム プロジェクトです。
- 文法ベースの認識パーサーである Julian と統合されています。
- ルールベースの文法をサポートするだけでなく、Word グラフ出力、信頼度スコアリング、GMM ベースの入力拒否、その他多くの機能も提供します。
6.サイモン
Simon には、Peter Grasch が開発した最新の使いやすい音声認識ソフトウェアが付属しています。これは、GNU General Public License に基づく別のオープン ソース プログラムです。 Linux システムと Windows システムの両方で Simon を自由に使用できます。また、必要な言語で作業できる柔軟性も提供します。
サイモンの特筆すべき特徴
- Simon は、音声制御の電卓を使用して、さまざまな算術演算を行う機能を提供します。
- Skype やその他の一般的な VOIP プログラムと互換性があり、友人や親戚との簡単なコミュニケーション システムを確立できます。
- ユーザーは、いくつかの簡単な音声コマンドで、スライド ショーやビデオを見たり、音楽を聴いたりすることができます。
- また、新聞を読んだり、インターネットをサーフィンしたりするのに不可欠なツールです。
7.マイクロフト
Mycroft には、音声をテキストに変換するための使いやすいオープン ソースの音声アシスタントが付属しています。これは、Python で書かれた、現代で最も人気のある Linux 音声認識ツールの 1 つと見なされています。これにより、ユーザーは科学プロジェクトまたはエンタープライズ ソフトウェア アプリケーションでこのツールを最大限に活用できます。また、時間、日付、天気などを知らせる実用的なアシスタントとしても使用できます。
Mycroft の注目すべき機能
- Facebook、Github、LinkedIn など、最も人気のあるソーシャル メディアやプロフェッショナル プラットフォームと統合されています。
- このアプリケーションは、さまざまなソフトウェアおよびハードウェア プラットフォームで実行できます。デスクトップでも Raspberry Pi でもかまいません。
- スマートな音声アシスタントであることに加えて、音声録音、機械学習、ソフトウェア ライブラリなどの機能を提供します。
- ユーザーは、Mycroft のインテント パーサーである Adapt を介して、自然言語を機械可読データに変換できます。
8. OpenMindSpeech
Open Mind Speech は、音声を無料でテキストに変換することを目的とした、Linux の重要な音声認識ツールの 1 つです。これは Open Mind Initiative の一部であり、特に開発者向けにその操作を実行します。このプログラムは、現在の名前になる前に、VoiceControl、SpeechInput、FreeSpeech などのさまざまな名前で導入されました。
OpenMindSpeech の注目すべき機能
- 音声認識操作でオーバーフロー環境を使用して、複雑なアプリケーションを柔軟にします。
- Open Mind Speech は、Linux および UNIX ベースのプラットフォームとほぼ互換性があります。
- インターネットを使用して、生データの提供者である電子市民から音声データを収集できます。
9.スピーチコントロール
Speech Control は、任意の Ubuntu ディストリビューションに適した無料の音声認識アプリケーションです。 Qt に基づくグラフィカル ユーザー インターフェイスが付属しています。まだ開発の初期段階ですが、簡単なプロジェクトに使用できます。
SpeechControl の注目すべき機能
- Speech Control は、General Public License (GPL) に基づくオープン ソース プログラムです。
- プロセスをスムーズに実行するための反復タスク ガイダンスを提供する仮想アシスタントとして機能することを目的としています。
- 主に Linux ベースのプラットフォームに適しています。
- また、プロジェクトの詳細を含むわかりやすいユーザー ドキュメントを提供します。
10. Deepspeech.pytorch
Deepspeech.pytorch は、PyTorch 用の DeepSpeech2 の最終的な実装である、もう 1 つの注目すべきオープン ソースの音声認識アプリケーションです。これには、一連の強力なネットワーク ベースの DeepSpeech2 アーキテクチャが含まれています。多くの役立つリソースを備えているため、研究やプロジェクト開発に不可欠な Linux 音声認識ツールの 1 つとして使用できます。
Deepspeech.pytorch の注目すべき機能
- オーディオの読み込み時の堅牢性を高めるのに役立つノイズ増強をサポートします。
- ポスト リクエストをサーバーに送信するために、基本的なサーバー スクリプトが用意されています。
- TEDLIUM、AN4、Voxforge、LibriSpeech など、複数のデータセットのダウンロードをサポートします。
- ノイズ注入によってトレーニング データにノイズを追加できます。
- 科学実験のトレーニングを視覚化するための Visdom と Tensorboard をサポートします。
まとめ
これで、Linux 用のオープン ソース音声認識ツールの最終段階に到達しました。このトピックに関する包括的な情報が得られたことを願っています。上記のアプリケーションは無料で使いやすく、学術的または個人的なプロジェクトの一部になる準備ができています。
どれが一番好きですか?他に選択肢がある場合は、遠慮なくお知らせください。この記事が役に立った場合は、コミュニティと共有してください。それまで、楽しい時間をお過ごしください。ありがとう!