
grep とは?
今日入手する grep ユーティリティは、egrep および fgrep ユーティリティと同じファミリに属する Unix ツールです。これらはすべて、ファイルやテキストに対して反復的な検索タスクを実行するために設計された Unix ツールです。 grep コマンドで特定の検索基準を指定することにより、有用な情報取得のためにファイルとその内容を検索できます。
つまり、GREP は Global Regular Expression Print の略であると言われていますが、このコマンド「grep」はどこから来たのでしょうか? grep は基本的に、非常にシンプルで由緒ある Unix テキスト エディタ ed の特定のコマンドから派生しています。 ed コマンドの実行方法は次のとおりです:
g/re/p
コマンドの目的は、grep を検索することで意味するものと非常に似ています。このコマンドは、特定のテキスト パターンに一致するファイル内のすべての行をフェッチします。
grep コマンドをもう少し調べてみましょう。この記事では、grep ユーティリティのインストールについて説明し、いくつかの例を示して、それをどのように、どのシナリオで使用できるかを正確に理解できるようにします。
この記事に記載されているコマンドと手順を Ubuntu 18.04 LTS システムで実行しました。
grep をインストール
grep ユーティリティはほとんどの Linux システムにデフォルトで付属していますが、システムにインストールされていない場合の手順は次のとおりです。
Dash または Ctrl+Alt+T ショートカットを使用して Ubuntu ターミナルを開きます。次に、apt-get を使用して grep をインストールするために、root として次のコマンドを入力します。
$ sudo apt-get install grep
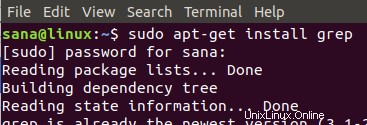
インストール手順中に y/n オプションのプロンプトが表示されたら、y を入力します。その後、システムに grep ユーティリティがインストールされます。
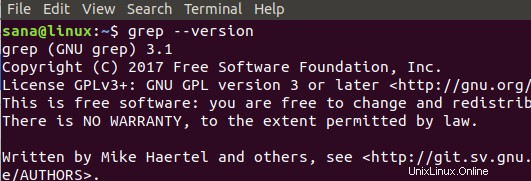
次のコマンドで grep のバージョンを確認することで、インストールを確認できます:
$ grep --version
grep コマンドの使用例と例
grep コマンドは、それを利用できるいくつかのシナリオを提示することで最もよく説明できます。以下にいくつかの例を示します:
ファイルを検索
特定のキーワードを含むファイル名を検索する場合は、次のように grep コマンドを使用してファイル リストをフィルター処理できます。
構文:
$ ls -l | grep -i " 検索ワード”
例:
$ ls -l | grep -i sample
このコマンドは、現在のディレクトリ内にあるファイル名に「private」という単語が含まれるすべてのファイルを一覧表示します。

ファイル内の文字列を検索
grep コマンドを使用して、特定のテキスト文字列を含むファイルから文を取得できます。
構文:
「文字列」ファイル名を grep
例:
$ grep “sample file” sampleFile.txt

私のサンプル ファイル sampleFile.txt には、上記の出力で確認できる文字列「sample file」を含む文が含まれています。キーワードと文字列は、検索結果に色付きで表示されます。
複数のファイルで文字列を検索
同じタイプのすべてのファイルからテキスト文字列を含む文を検索したい場合は、grep コマンドが役に立ちます。
構文 1:
$ grep “string” filenameKeyword*
構文 2:
$ grep "string" *.extension
例1:
$ grep "sample file” sample*

このコマンドは、キーワード「sample」を含むファイル名を持つすべてのファイルから、文字列「sample file」を含むすべての文を取得します。
例 2:
$ grep "sample file” *.txt

このコマンドは、拡張子が .txt のすべてのファイルから、文字列「sample file」を含むすべての文を取得します。
文字列の大文字と小文字を区別せずにファイル内の文字列を検索する
上記の例では、テキスト文字列の大文字と小文字がサンプル テキスト ファイルと同じでした。次のコマンドを入力した場合、ファイル内のテキストが大文字の「Sample」で始まらないため、検索結果はゼロになります。
$ grep "Sample file" *.txt

検索文字列の大文字と小文字を区別せず、-i オプションを使用して文字列に基づいて検索結果を出力するように grep に指示しましょう。
構文:
$ grep -i “文字列” ファイル名
例:
$ grep -i "Sample file" *.txt

このコマンドは、拡張子が .txt のすべてのファイルから、文字列「sample file」を含むすべての文を取得します。これは、検索文字列が大文字か小文字かを考慮しません。
正規表現による検索
grep コマンドを使用すると、start キーワードと end キーワードを使用して正規表現を指定できます。出力は、指定した開始キーワードと終了キーワードの間の式全体を含む文になります。検索コマンドで式全体を記述する必要がないため、この機能は非常に強力です。
構文:
$ grep “startingKeyword.*endingKeyword” filename
例:
$ grep "starting.*.ending" sampleFile.txt

このコマンドは、grep コマンドで指定したファイルから、式 (startingKeyword から始まり、endingKeyword で終わる) を含む文を出力します。
検索文字列の前後に指定した行数を表示する
grep コマンドを使用して、ファイルから検索文字列の前後の N 行を出力できます。検索結果には、検索文字列を含むテキスト行も含まれます。
キー文字列の後の N 行の構文:
$ grep -A
例:
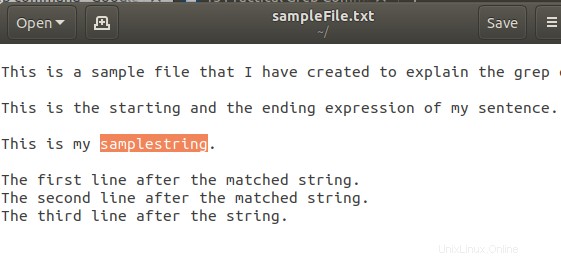
$ grep -A 3 -i "samplestring" sampleFile.txt
サンプル テキスト ファイルは次のようになります。
コマンドの出力は次のようになります:
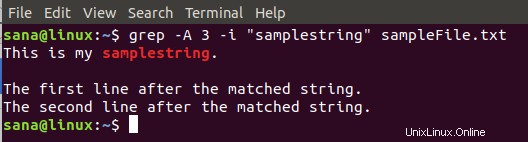
grep コマンドで指定したファイルから、検索文字列を含む行を含む 3 行を表示します。
キー文字列の前の N 行の構文:
$ grep -B
テキスト文字列の「周囲」の N 行を検索することもできます。これは、テキスト文字列の前に N 行、後ろに N 行あることを意味します。
キー文字列の周りの N 行の構文:
$ grep -C
この記事で説明する簡単な例を通して、grep コマンドを理解することができます。その後、それを使用して、ファイルまたはファイルのコンテンツを含む可能性のあるフィルター処理された結果を検索できます。これにより、grep コマンドを習得する前に検索結果全体をざっと見て無駄にしていた時間を大幅に節約できます。