Apache Cassandra は、Facebook (現在は Meta) によって作成された、無料でオープンソースの NoSQL 分散データベース管理システムです。 Cassandra の分散型の性質により、単一障害点のない高可用性と高パフォーマンスが可能になります。
そのスケーラビリティにより、Cassandra は大量のアクティブで重要なデータ セットに適しています。 Apple、Bloomberg、BestBuy、eBay、Netflix、Spotify などの大規模で有名な組織。 Apache Cassandra について知りたい場合は、ここが最適です。
この記事では、Linux システムで Apache Cassandra クラスターをセットアップして構成する方法を学習します。また、コマンドライン ツールを使用して Cassandra を操作する方法も学びます。
前提条件
このチュートリアルの例に従うには、次の要件が整っていることを確認してください。
- 2 つの Linux サーバーが同じネットワークにある必要があります。このチュートリアルでは、次の詳細で 2 つの Rocky Linux (v8.5) サーバーを使用します。
| ホスト名 | IPアドレス |
| cassandra01 | 172.16.1.10 |
| cassandra02 | 172.16.1.15 |
Apache Cassandra のドキュメントには、互換性のある Linux ディストリビューションの規範的なリストは記載されていませんが、Cassandra は CentOS、RHEL、Debian、および SUSE Enterprise Linux で実行できると記載されています。
- sudo 権限または root アカウントへのアクセス権が必要です。
- Nano テキスト エディタまたは任意の Linux ベースのテキスト エディタ。
Java OpenJDK と Python のインストール
Apache Cassandra のインストールに取り掛かる前に、まずソフトウェアの依存関係をインストールします。 Cassandra は Java ベースのアプリケーションであり、最新バージョン (この記事の執筆時点では v4.0) には Java OpenJDK 1.8 と Python 3.6 が必要です。
このチュートリアルでは、RPM ベースの Linux ディストリビューション用の DNF パッケージ マネージャーを使用します。 Ubuntu や Debian などの DEB ベースのディストリビューションでは、Yum または Apt を使用することもできます。ディストリビューションのドキュメントを参照して、使用するパッケージ マネージャーを決定してください。
以下の手順に従って、Java OpenJDK 1.8 と Python 3.6 を各サーバーにインストールします。
1. SSH クライアントを開き、サーバーに接続して、sudo su を実行します。 rootになるコマンド。
ssh example@unixlinux.online_name_or_IP
sudo su
2. 次に、dnf を実行します 以下のコマンドを実行して、Java OpenJDK 1.8 および Python 3.6 パッケージをインストールします。インストールが完了するまで待ちます。
dnf install java-1.8.0-openjdk python36 -y3. 次に、以下のコマンドを実行して Java のバージョンを確認します。
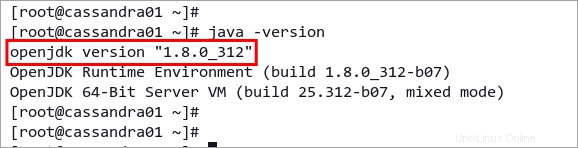
java -version以下に、Java OpenJDK の現在のバージョンが 1.8.0_312 であることを示します。
4. 次に、サーバーのデフォルトの Python インタープリターを Python 3.6 に設定します。これを行うには、alternatives を実行します。 以下のようにコマンドを実行してください。
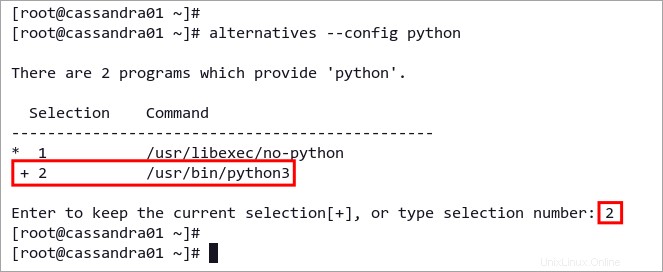
alternatives --config pythonコマンド選択プロンプトで、Python のバージョンに対応する番号を入力します。以下の例は、Python3 がオプション 2 であることを示しています。
5. 最後に、次のコマンドを実行して Python のバージョンを確認します。
python --versionPython 3.x.x が表示されます。 以下のスクリーンショットのように、デフォルトです。
Apache Cassandra NoSQL データベースのインストール
依存関係をインストールし、それらが適切なバージョンであることを確認しました。それでは、Apache Cassandra をインストールしましょう!
Cassandra をインストールするには多くの方法がありますが、最も便利な方法は公式リポジトリを使用する方法です。ただし、最初に実行する必要がある簡単な手順がいくつかあります。 Cassandra NoSQL データベースを Linux システムにインストールするには、次の手順に従います。
1. 次のコマンドを実行して、Cassandra の新しいリポジトリ ファイルを作成します。
nano /etc/yum.repos.d/cassandra.repo2. 次の Cassandra リポジトリ構成をコピーします。このリポジトリは、Rocky Linux を含むほとんどの Red Hat ディストリビューションで利用できます。
[cassandra]
name=Apache Cassandra
baseurl=https://downloads.apache.org/cassandra/redhat/40x/
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://downloads.apache.org/cassandra/KEYS
3. 編集後、Ctrl+X を押してファイルを保存して閉じます。 、 Y 、および Enter .
4. 次に、dnf を実行します。 以下のコマンドを実行して、システムで利用可能なすべてのリポジトリを確認します。
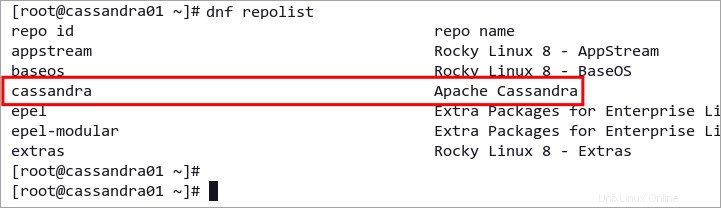
dnf repolist以下に示すように、リポジトリ リストに Apache Cassandra リポジトリが表示されます。
5. 次のコマンドを実行して、Cassandra NoSQL データベースをインストールします。
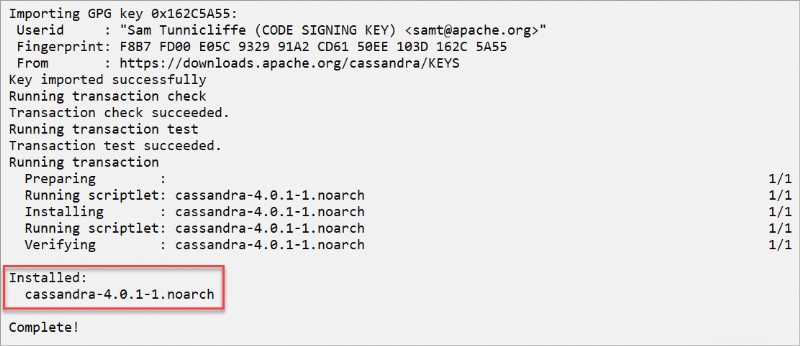
dnf install cassandra -yApache Cassandra をインストールすると、以下のスクリーンショットのような確認メッセージが表示されます。
Apache Cassandra クラスタの構成
Cassandra をインストールしたら、構成 /etc/cassandra/conf/cassandra.yaml を編集する必要があります。 Cassandra クラスターをセットアップします。
Cassandra クラスターを機能させるには、すべてのサーバーでデフォルトの Cassandra 構成を次のように変更する必要があります。
- デフォルトの
cluster_nameを変更します . - サーバーの IP アドレスを
seedsに追加します オプション - デフォルトの
listen_addressを変更します rpc_addressを有効にする クライアント接続用
次に、次の手順に進み、Cassandra クラスターをセットアップします。
1. cassandra01 で 、次のコマンドを実行して Cassandra 構成 cassandra.yaml を開きます 編集用。
nano /etc/cassandra/conf/cassandra.yaml
2. cluster name のデフォルト値を変更します 新しい名前で。このチュートリアルでは、新しいクラスター名 ATA Cluster を使用します .
cluster_name: 'ATA Cluster'
3. ここで、各サーバーの IP アドレスをデフォルトの Cassandra TCP ポート 7000 で seeds に追加します。 以下のオプション。フォーマットは IP:Port,IP:Port のパターンに従います 、デフォルトのポートは 7000 です .
seeds: "172.16.1.10:7000,172.16.1.15:7000"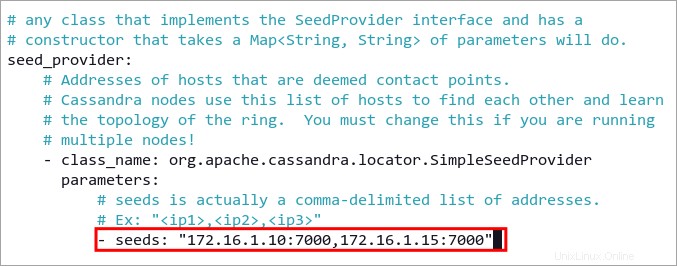
4. 次に、デフォルトの listen_address を変更します サーバーの IP アドレスに、ではなく ローカルホスト。オプション listen_address Cassandra が実行される IP アドレスを定義します。
# for cassandra01
listen_address: 172.16.1.10
# for cassandra02
listen_address: 172.16.1.15
5. 次に、デフォルト オプション rpc_address を変更します。 サーバーのIPアドレス、listen_addressと同じ値 オプション。 Cassandra クラスター環境では、すべてのクライアント接続は、デフォルトの TCP のローカル サーバー IP アドレスを経由します。 ポート 9042 .
# for cassandra01
rpc_address: 172.16.1.10
# for cassandra02
rpc_address: 172.16.1.15
6. Ctrl+X を押して、構成ファイルを保存して閉じます。 、 Y 、および Enter .
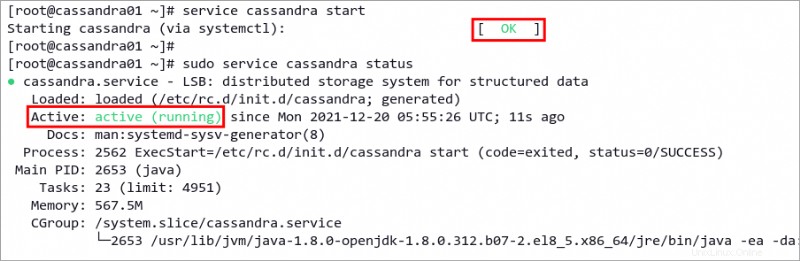
7. Cassandra 構成を編集したら、次のコマンドを実行して Cassandra サービスを開始します。このコマンドは、クラスターを自動的に開始し、IP アドレスが seeds にある他のサーバーに到達します。 オプション。
service cassandra start8. 次に、以下のコマンドを実行して、Cassandra サービスのステータスを確認します。
service cassandra status以下のスクリーンショットのような出力が得られます。ご覧のとおり、Cassandra サービスはアクティブ (実行中) です .
ファイアウォールを使用して Apache Cassandra クラスタを保護する
サービスを保護するためのファイアウォールの設定は、本番環境では不可欠な作業です。これにより、特定の IP アドレスまたはネットワーク範囲からのみ Cassandra クラスターへのアクセスを制限できます。
一般的な Red Hat Linux ディストリビューションでは、firewalld がデフォルトのファイアウォール ソフトウェアです。
デフォルトでは、Cassandra では 2 つの TCP ポートを開く必要があります。ポート 7000 はデフォルトのクラスター ポートで、ポート 9042 はクライアント接続用のネイティブのデフォルト トランスポート ポートです。
以下の手順に従って、ファイアウォールで Cassandra クラスターの展開を保護してください。
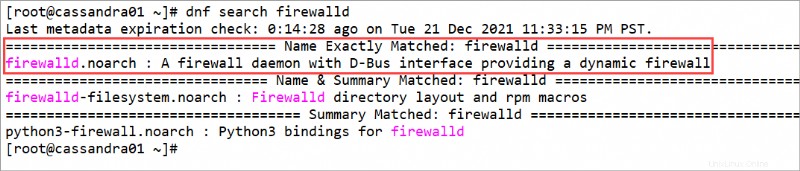
1. まず、すでに firewalld を持っているかどうかを確認します 以下のコマンドを実行して、サーバー上で。
dnf search firewalldIf
firewalldが存在しない場合は、手順 2 と 3 に従います。firewalldの場合 既にサーバーに存在する場合は、代わりに手順 4 にスキップしてください。
2. firewalld がない場合 システムで、次のコマンドを実行してインストールします。
dnf install firewalld -y
3. firewalld を開始します。 以下のコマンドを実行してサービスを開始します。このコマンドは firewalld を開始します SSH や DHCP クライアントなどの重要なポートとサービスを開きます。
systemctl start firewalldデフォルトでは、firewalld はコマンドライン インターフェイス
firewall-cmdを提供します。 ファイアウォール ルールを管理および維持するための
4. 次の firewall-cmd を実行します 新しいゾーンを作成するコマンド Cassandra クラスターの場合、firewalld をリロードします ルール。
# add firewalld zone cassandra-cluster
firewall-cmd --new-zone=cassandra-cluster --permanent
# reload firewalld
firewall-cmd --reload
出力メッセージ success が表示されます 、これは操作が成功したことを意味します。オプション --permanent 新しいファイアウォール ルールを永続的にします。

5. 次に、サーバー ネットワークの CIDR を cassandra-cluster に追加します。 ゾーン。このルールは、CIDR 172.16.1.0/24 のすべてのサーバーまたはクライアントを許可します 話すこと、つながること。単一の IP アドレスを追加するには、IP アドレス 172.16.1.20 を入力します .
firewall-cmd --zone=cassandra-cluster --add-source=172.16.1.0/24 --permanent
6. 次のコマンドを実行して、Cassandra サービス ポート 7000 を追加します。 と 9042 cassandra-cluster に ゾーン。
# add storage_port Apache Cassandra to the zone cassandra_cluster
firewall-cmd --zone=cassandra-cluster --add-port=7000/tcp --permanent
# add Apache Cassandra port for client connections
firewall-cmd --zone=cassandra-cluster --add-port=9042/tcp --permanent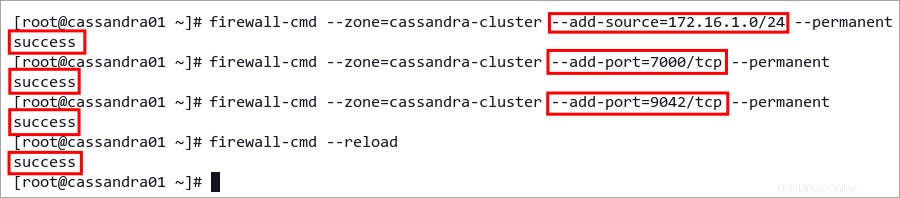
7. 最後に firewalld をリロードします 以下のコマンドを実行して新しい設定を適用するためのルール。
firewall-cmd --reload
Cassandra クラスターは、172.16.1.0/24 を介してのみアクセスできるようになりました
Apache Cassandra クラスターのステータスを確認する
Nodetool は、Cassandra クラスターを管理および監視するためのネイティブ コマンド ユーティリティです。このツールを使用すると、テーブルやキースペース、サーバー メトリック、アプリケーション、クライアント接続メトリックなど、Cassandra クラスターのメトリック ステータスを表示できます。
通常、管理者は nodetool を実行します。 運用中の Cassandra サーバーで直接コマンドを実行して、定期的なデータベースのメンテナンスと監視を実行します。
以下の手順に従って、nodetool を使用して Cassandra クラスターを監視する基本を学びます。
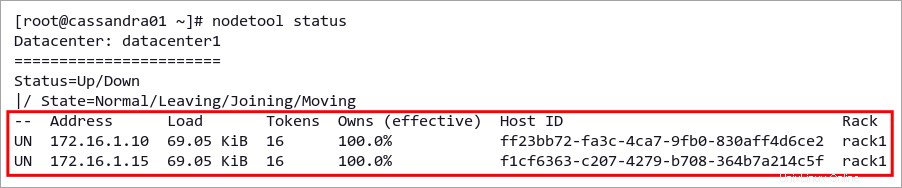
1. 次のコマンドを実行して、Cassandra クラスターのステータスを確認します。
nodetool status以下のスクリーンショットのような出力が得られます。
- う ノードがUPであることを意味します または実行中。
- いいえ ノードがNORMALであることを意味します .
- 住所 ノードの IP アドレスまたは URL です。
- 読み込み Cassandra データ ディレクトリ内のファイルのサイズです。この値は 90 秒ごとに更新されます。
- トークン ノードで利用可能なトークンの数です。
- ホスト ID ノードのネットワーク ID です。各ノードには異なる ID があります。
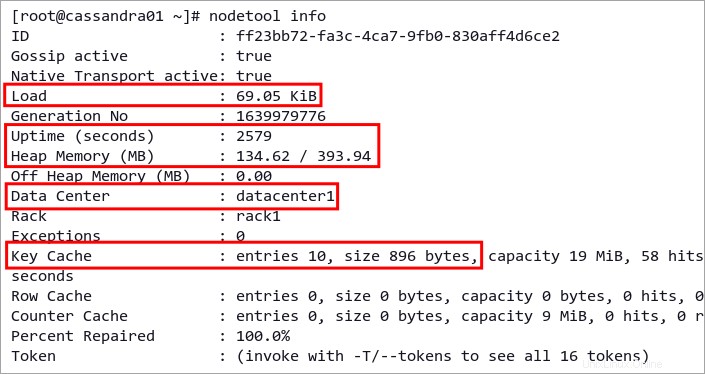
2. 次に、以下のコマンドを実行して、単一ノードに関する詳細情報を取得します。
nodetool info以下に、次のようなノードに関する詳細情報を表示できます。
- 稼働時間
- ヒープメモリ情報
- 読み込み
- キーキャッシュとカウンターキャッシュ
- データセンターの場所
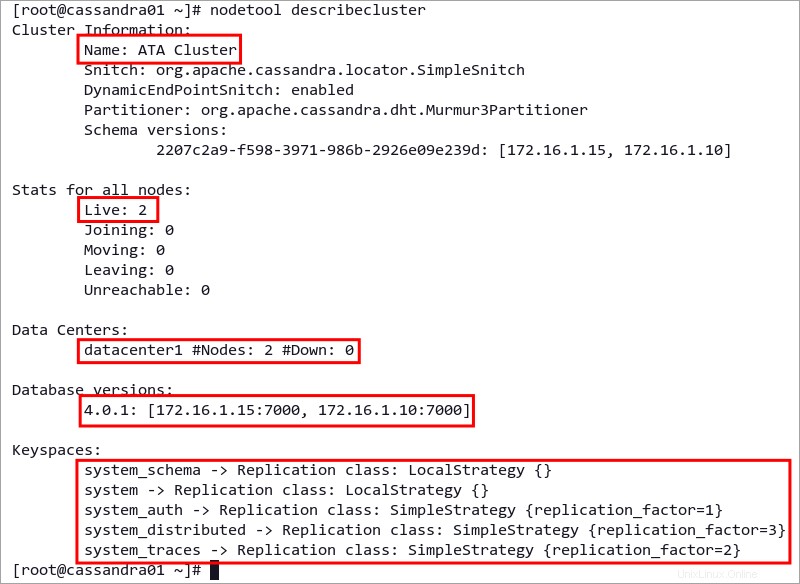
3. 次に、以下のコマンドを実行して、Cassandra クラスターの詳細を表示します。
nodetool describecluster詳細な Cassandra クラスターを以下に示します。
- クラスター情報 名前、デフォルトの Cassandra パーティショナー、スキーマ バージョンなど、Cassandra クラスターに関する基本情報が含まれています。
- すべてのノードの統計 Cassandra クラスタ上のすべてのノードの現在のステータスを示します。
- Cassandra クラスタを複数のデータ センターに構築した場合、データ センターにすべてのデータ センターが表示されます。
- データベースのバージョン セクションには、各クラスタ ノードの Cassandra のバージョンが表示されます。
- Cassandra クラスタで利用可能なすべてのキースペースまたはデータベースのリストは、キースペースの下にあります。 セクション。
Apache Cassandra クラスタへの接続
サーバーに Apache Cassandra パッケージをインストールすると、Cassandra Query Language Shell (CQLSH) もインストールされます。このツールを使用すると、管理者は Apache Cassandra に接続して、データベースまたはキースペースとユーザーを管理できます。
以下の手順に従って、コマンドライン cqlsh を使用して Cassandra クラスターに接続します。 .
1. cqlsh を実行します Cassandra クラスターに接続するための以下のコマンド。 Cassandra IP アドレスを指定します。クライアント接続のデフォルト ポートは 9042 です .
cqlsh 172.16.1.10 9042
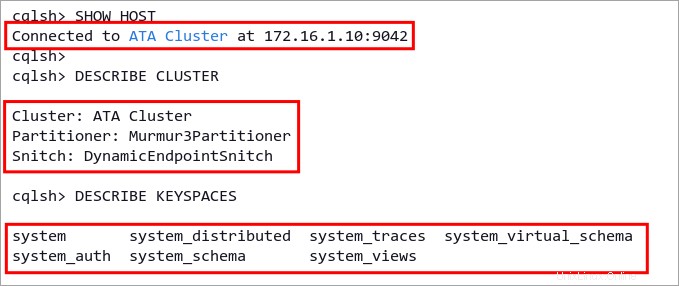
Cassandra クラスターに接続すると、以下のスクリーンショットのような出力が表示されます。この例では、サーバー IP アドレス 172.16.1.10 でクラスター名 ATA クラスターを使用します。 .

2. 次に、次の CQL クエリを実行して、接続先のサーバーを確認し、クラスター名を確認し、Cassandra で使用可能なすべてのキースペースを確認します。
# show detailed host
SHOW HOST
# show cluster name
DESCRIBE CLUSTER
# list all available keyspaces (databases)
DESCRIBE KEYSPACES
以下のスクリーンショットと同様の出力が表示されます。 SHOW HOST クエリは、接続されている場所を示します。クエリ DESCRIBE CLUSTER Cassandra クラスター名とクエリ DESCRIBE KEYSPACES が表示されます Cassandra ノードのキースペースのリストを表示します。
3. 最後に、exit を入力します cqlsh からログアウトするには 環境。
結論
このチュートリアルを通じて、Linux に Apache Cassandra をインストールして構成する方法を学習しました。また、2 つの Linux サーバーを使用して Apache Cassandra クラスターを構成し、Firewalld を使用してデプロイを保護しました。
この時点で、サーバーを追加してデプロイをスケーリングし、データの高可用性、一貫性、および冗長性を提供する準備が整いました。
あなたの次は何ですか?おそらく、Cassandra クラスターで認証と承認を設定することから始めて、アプリケーションのキースペース/データベースのレプリケーションを設定します。その間、nodetool を使用して Apache Cassandra クラスターを維持する方法を学びませんか?