Scrapy は Python で開発されたオープン ソース フレームワークで、Web サイトから情報をすばやく簡単に抽出するための Web スパイダーまたはクローラーを作成できます。
このガイドでは、さまざまな手法を使用して Web ページから情報を抽出するために、Scrapy を使用してサーバー上で Web スパイダーを作成および実行する方法を示します。
まず、SSH 接続を介してサーバーに接続します。まだ行っていない場合は、ガイドに従って SSH で安全に接続することをお勧めします。ローカル サーバーの場合は、次の手順に進み、サーバーのターミナルを開きます。
仮想環境の作成
実際のインストールを開始する前に、システム パッケージを更新してください:
$ sudo apt-get update操作に必要ないくつかの依存関係をインストールして続行します:
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-devインストールが完了したら、virtualenv の構成を開始できます。これは、他のソフトウェアを危険にさらすことなく、Python パッケージを分離した方法でインストールできる Python パッケージです。オプションですが、このステップは Scrapy 開発者に強く推奨されています:
$ sudo pip install virtualenv次に、Scrapy 環境をインストールするためのディレクトリを準備します:
$ sudo mkdir /var/scrapy
$ cd /var/scrapy仮想環境を初期化します:
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.仮想環境を有効にするには、次のコマンドを実行してください:
$ sudo source /var/scrapy/bin/activate「非アクティブ化」コマンドでいつでも終了できます。
Scrapy のインストール
Scrapy をインストールして、新しいプロジェクトを作成します:
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd example新しく作成されたプロジェクト ディレクトリでは、ファイルは次の構造になります:
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.pyテスト目的でのシェルの使用
Scrapy を使用すると、Web ページの HTML コンテンツをダウンロードし、css セレクターなどのさまざまな手法を使用してそれらから情報を推定できます。このプロセスを容易にするために、Scrapy は情報抽出をリアルタイムでテストするための「シェル」を提供します。
このチュートリアルでは、有名なソーシャル Reddit のメイン ページの最初の投稿をキャプチャする方法を説明します:
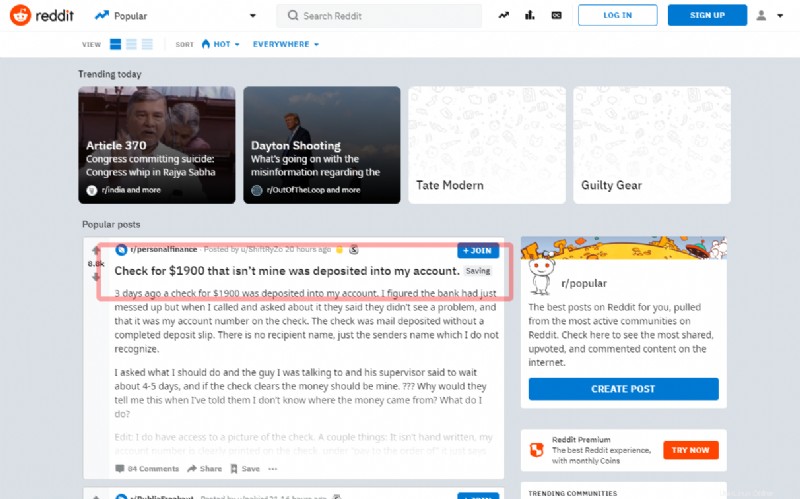
ソースの記述に移る前に、シェルからタイトルを抽出してみてください:
$ sudo scrapy shell "reddit.com"数秒以内に、Scrapy はメイン ページをダウンロードします。したがって、「response」オブジェクトを使用してコマンドを入力します。次の例のように、セレクター "article h3 ::text":を使用して、最初の投稿のタイトルを取得します
>>> response.css('article h3::text')[0].get()セレクターが正常に動作すると、タイトルが表示されます。次に、シェルを終了します:
>>> exit()新しいスパイダーを作成するには、プロジェクト ディレクトリ example/spiders/reddit.py に新しい Python ファイルを作成します:
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )すべてのスパイダーは Scrapy モジュールの Spider クラスを継承し、start_requests メソッドを使用してリクエストを開始します:
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)Scrapy がページの読み込みを完了すると、コールバック関数 (self.parseHome) が呼び出されます。
応答オブジェクトがあれば、関心のあるコンテンツを取得できます:
headline = response.css('article h3::text')[0].get()デモンストレーションのために、「popular.list」ファイルに保存します。
次のコマンドを使用して、新しく作成したスパイダーを開始します:
$ sudo scrapy crawl reddit完了すると、最後に抽出されたタイトルがpopular.listファイルに表示されます:
$ cat popular.listScrapyd のスケジューリング
スパイダーの実行をスケジュールするには、Scrapy が提供するサービス「Scrapy Cloud」(https://scrapinghub.com/scrapy-cloud を参照) を使用するか、オープンソース デーモンをサーバーに直接インストールします。 .
以前に作成した仮想環境にいることを確認し、pip を介して Scrapyd パッケージをインストールします:
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapydインストールが完了したら、次の内容で /etc/systemd/system/scrapyd.service ファイルを作成してサービスを準備します:
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapyd新しく作成したファイルを保存し、次の方法でサービスを開始します:
$ sudo systemctl start scrapydこれで、デーモンが構成され、新しいスパイダーを受け入れる準備が整いました。
サンプル スパイダーをデプロイするには、Scrapy が提供する「scrapyd-client」と呼ばれるツールを使用する必要があります。 pip 経由でインストールを続行します:
$ sudo pip install scrapyd-clientscrapy.cfg ファイルを編集し、展開データを設定して続行します:
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = exampleコマンドを実行するだけでデプロイできます:
$ sudo scrapyd-deployスパイダーの実行をスケジュールするには、scrapyd API を呼び出すだけです:
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit