検索するデータが大量にある場合は、ApacheSolrがまさに必要なものである可能性があります。 Jack Wallenが、この便利なツールを展開する方法を紹介します。
Apache Solrは、全文検索、ヒットハイライト、ファセット検索、リアルタイムインデックス作成、動的クラスタリングを実行できるオープンソースの検索プラットフォームであり、データベース統合、豊富なドキュメント処理、およびユーザーフレンドリーなWebベースのUIが含まれています。検索するデータが大量にある場合は、このツールがまさに必要なものになる可能性があります。 Apache Solorは、トラフィックが多く、拡張性が高く、フォールトトレラントに最適化されています。
オープンソース:必読の記事
ApacheSolrをUbuntuServer22.04(Jammy Jellyfish)のインスタンスにインストールして実行する簡単な手順を説明します。
必要なもの
Apache Solrを正常にインストールするには、UbuntuServer22.04の実行中のインスタンスとsudo権限を持つユーザーが必要です。もちろん、Apache SolrをさまざまなLinuxディストリビューションにインストールすることもできますが、ここでは、選択したサーバーに集中します。
それでは、インストールに取り掛かりましょう。
ApacheSolrのインストール方法
Ubuntu Serverインスタンスにログインし、次のコマンドを使用してJavaをインストールします。
sudo apt-get install default-jdk -y
Javaがインストールされたら、次のコマンドを使用してApacheSolrをダウンロードします。
wget https://downloads.apache.org/lucene/solr/8.11.1/solr-8.11.1.tgz
必ずApacheSolrダウンロードページにアクセスして、アプリケーションの最新バージョンをダウンロードしていることを確認してください。
パッケージがダウンロードされたら、次のコマンドで解凍します:
tar -xvzf solr-8.11.1.tgz
新しく作成されたディレクトリには、ほぼすべてを処理する便利なインストールスクリプトが含まれています。このスクリプトを実行するには、次のコマンドを発行します。
sudo ./solr-8.11.1/bin/install_solr_service.sh solr-8.11.1.tgz
スクリプトが終了したら、次のコマンドでApacheSolrを起動して有効にします。
sudo systemctl enable --now solr
コレクションの作成方法
次に、データを格納するために使用できるコレクションを作成する必要があります。ただし、これを行う前に、インストーラースクリプトの実行中に追加されたsolrユーザーのパスワードを作成する必要があります。これを行うには、次のコマンドを発行します:
sudo passwd solr
ユーザーの新しいパスワードを入力して確認するように求められます。
これで、次のコマンドを使用してコレクションを作成できます:
su - solr -c "/opt/solr/bin/solr create -c datacollection -n data_driven_schema_configs"
solrユーザー用に作成したばかりの新しいパスワードの入力を求められます。
その作成が完了したら、次のコマンドを使用してサンプルデータをコレクションに追加しましょう:
./bin/post -c datacollection example/exampledocs/*
これで、Webベースのインターフェースにアクセスする準備が整いました。
ApacheSolrWebベースのインターフェースにアクセスする方法
Webブラウザーを開き、http:// SERVER:8983をポイントします。 [コアセレクター]ドロップダウンから(図A )、データコレクション(作成したばかり)を選択します。
図A
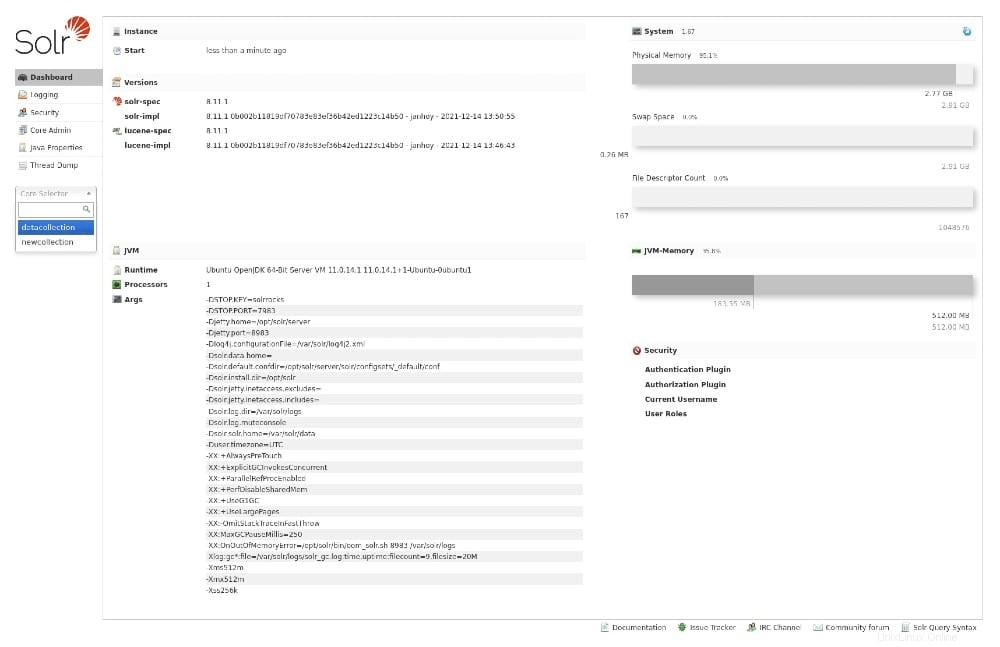
データ収集を選択すると、概要が表示され、すでにデータが含まれていることがわかります。次に、[クエリ]をクリックし、オプションのいずれかを変更して[クエリの実行]をクリックすると、そのデータを検索できます(図B 。
図B
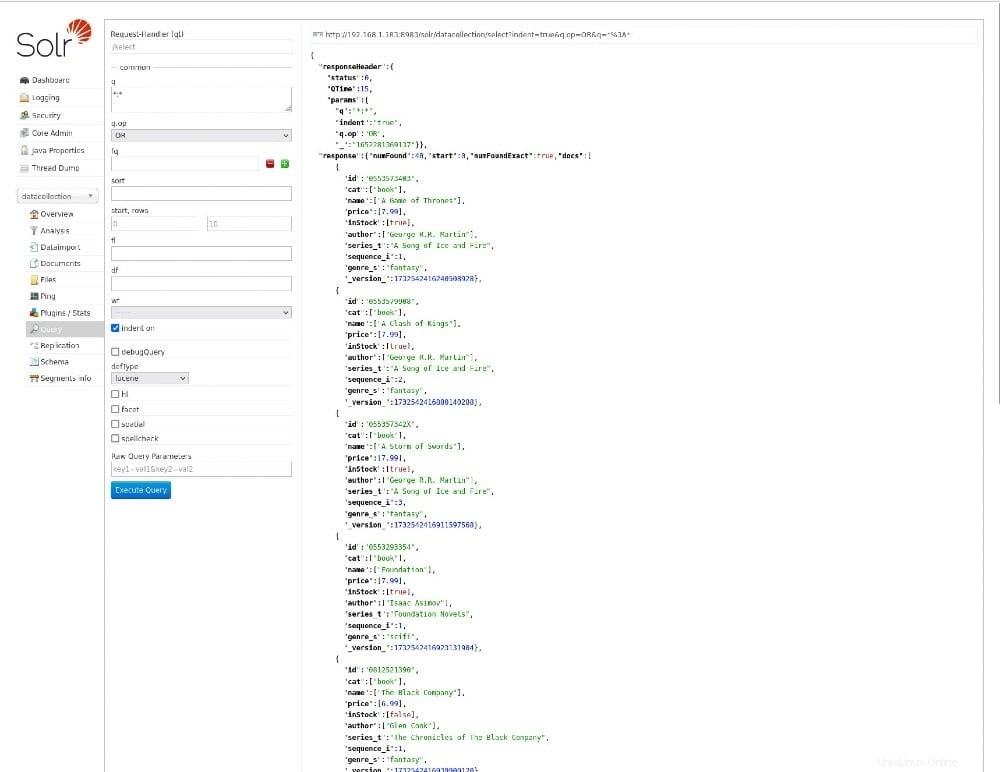
おめでとうございます。これで、Apache Solrが正常にインストールされ、新しいデータコレクションが作成され、サンプルデータが追加され、データに対してクエリが実行されました。
TechRepublicに登録する YouTubeでテクノロジーを機能させる方法 ジャックウォレンからのビジネスプロ向けの最新の技術アドバイス。
ソースリンク