リアルタイムのデータ分析プラットフォームを探しているなら、ジャック・ウォレンはApacheDruidに勝るものはないと考えています。このツールを起動して実行する方法と、サンプルデータをロードする方法を確認してください。
Apache Druidは、大量のデータセットに対する迅速なスライスアンドダイス分析を実現するために設計されたリアルタイム分析データベースです。デスクトップバージョンのLinux(またはGUIを備えたLinuxサーバー)からApache Druidを簡単に実行し、データをロードして解析を開始できます。
Apache Druidには、次のような機能が含まれています。
- ストリーミングとバッチ取り込み
- SQLサポート
- 水平方向のスケーラビリティ
Apache Druidは、リアルタイムの取り込み、高速なクエリ、高い稼働時間を必要とするユースケースに最適なオプションです。
Apache DruidをPop!_OS Linuxで実行するプロセス(ただし、どのLinuxディストリビューションでも実行できます)を説明してから、サンプルデータをロードする方法を説明します。
必要なもの
この機能を実現するために必要なのは、デスクトップ環境を備えたLinuxの実行中のインスタンスと、sudo権限を持つユーザーだけです。
それでおしまい。データベースを魔法のようにしましょう。
Java8のインストール方法
現時点では、ApacheDruidはJava8のみをサポートしているため、Java 8がインストールされ、デフォルトとして設定されていることを確認する必要があります。 UbuntuベースのデスクトップディストリビューションにJava8をインストールするには、マシンにログインし、ターミナルウィンドウを開いて、次のコマンドを発行します。
sudo apt install openjdk-8-jdk -y
インストールが完了したら、Java8をデフォルトとして設定する必要があります。次のコマンドでこれを行います:
sudo update-alternatives --config java
マシンに現在インストールされているすべてのJavaバージョンのリストが表示されます。必ずJava8に対応する番号を選択してください。
ApacheDruidサービスに関する一言
起動するのは、4つのCPUと16GBのRAMを必要とするApacheDruidのマイクロインスタンスです。 Apache Druidには、次の6つの異なるサービス構成があります。
- Nano-クイックスタート:1 CPU、4GB RAM
- マイクロクイックスタート:4 CPU、16GB RAM
- 小:8 CPU、64GB RAM
- 中:16 CPU、128GB RAM
- 大:32 CPU、256GB RAM
- X-Large:64 CPU、512GB RAM
データのサイズとニーズによって異なります。大量のデータを処理する場合は、ApacheDruidをクラスターとしてデプロイすることをお勧めします。ただし、Apache Druidを紹介したばかりなので、マイクロインスタンスは問題ありません。
必読の開発者向け記事
ApacheDruidをダウンロードして解凍する方法
Javaをインストールしたら、ApacheDruidをダウンロードして解凍します。ターミナルウィンドウに戻り、次のコマンドを使用して最新バージョンをダウンロードします(Apache Druidダウンロードページをチェックして、これが最新リリースであることを確認してください)。
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
ダウンロードしたファイルを次のコマンドで解凍します:
tar xvfz apache-druid-0.22.1-bin.tar.gz
次のコマンドで新しく作成されたディレクトリに移動します:
cd apache-druid-0.22.1
次のコマンドでサービスを開始します:
./bin/start-micro-quickstart
ApacheDruidサービスは問題なく起動するはずです。 CTRL + Cでキャンセルするまで、サービスの実行中にターミナルが戻らないことに注意してください。
ApacheDruidコンソールにアクセスする方法
Apache Druidを実行しているのと同じマシンで、Webブラウザーを開き、http://localhost:8888をポイントします。 。残念ながら、Apache Druidは、リモートマシンからアクセスできないように設定されているため、デスクトップマシンにインストールします。
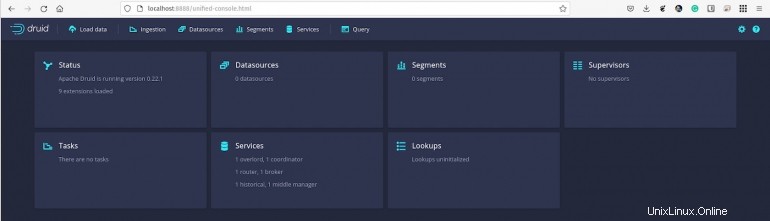
Apache Druidコンソールがあなたを迎えます(図A 。
図A
データの読み込み方法
クイックスタート/チュートリアル/ディレクトリにある事前定義されたデータのサンプルをロードします。サンプルはwikiticker-2015-09-12-sampled.json.gzと呼ばれます。
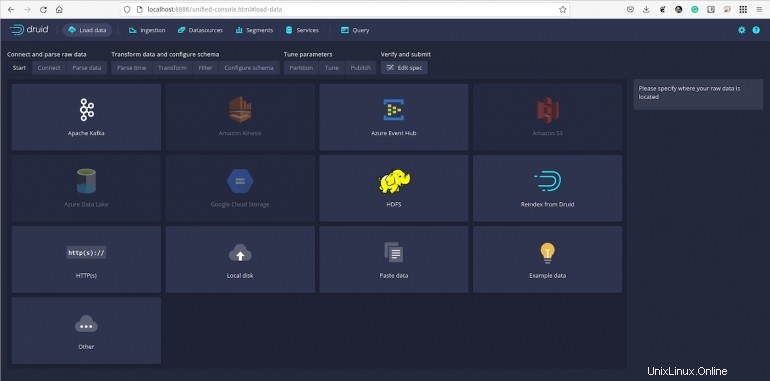
図B
[データの接続](ウィンドウの右側)をクリックしてから、表示されるサイドバー(図C )をクリックします。 )、「quickstart/tutorial」と入力します ベースディレクトリおよびwikiticker-2015-09-12-sampled.json.gzとして [ファイルフィルター]セクションにあります。
図C
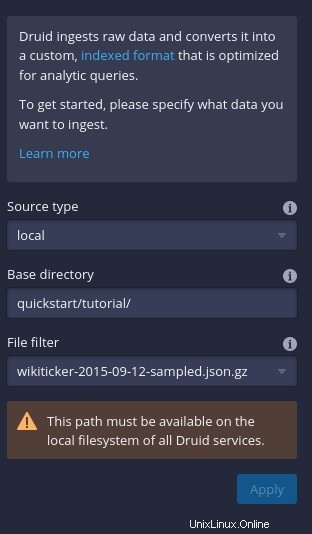
[適用]をクリックすると、メインウィンドウにかなりの量のデータが表示されます(図D 。
図D
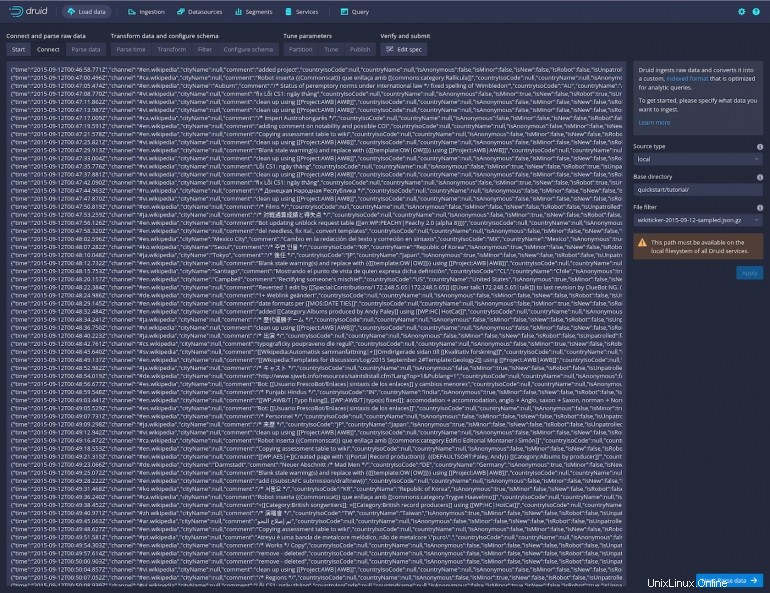
[次へ]をクリックします:右下の[データの解析]をクリックすると、より読みやすい形式でデータのリストが表示されます(図E 。
図E
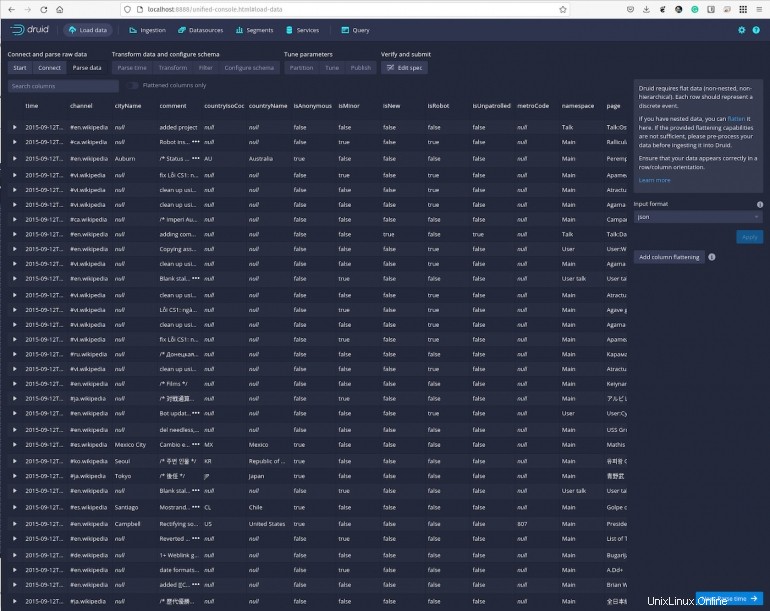
[次へ:時間を解析]をクリックすると、特定のタイムスタンプに対してデータを表示できます(図F 。
図F
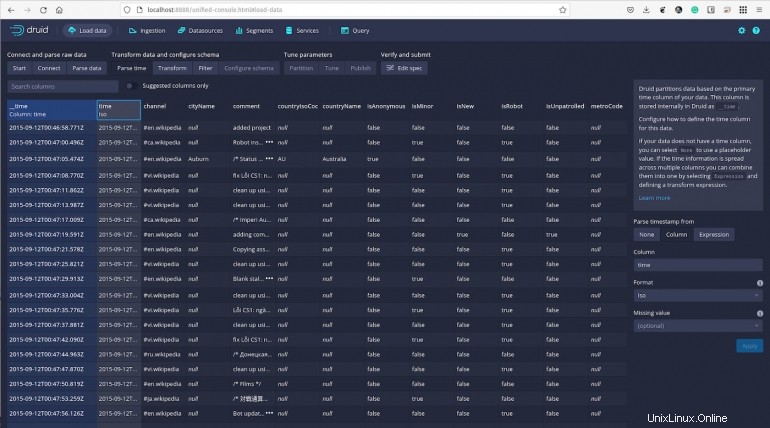
[次へ:変換]をクリックすると、列値の行ごとの変換を実行して、新しい列を作成するか、既存の列を変更できます。
データをクリックし続けると、いつでもクエリを実行して、必要に応じてデータをフィルタリングできます。 [スキーマの構成]セクション(図G )、クエリの粒度を指定したり、ディメンションと指標を追加したりすることもできます。
図G
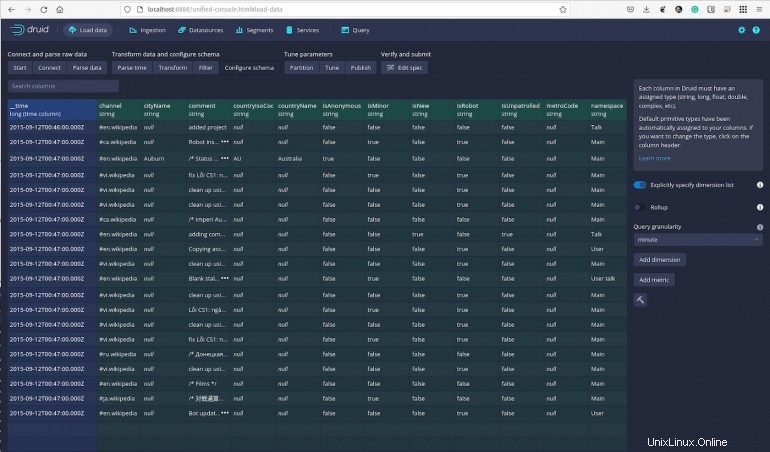
これがApacheDruidの基本です。この強力なデータ分析プラットフォームでできることのほんの一部をざっと見ただけですが、サンプルデータを試してみると、その仕組みをかなりよく理解できるはずです。
作業が終了したら、必ずターミナルウィンドウに戻り、CTRL+CでApacheDruidサービスを停止してください。