Curlは、Linuxターミナルでファイルをダウンロードするための優れたツールです。
元のファイルと同じ名前のファイルをダウンロードするための通常の構文は非常に単純です:
curl -O URL_of_the_fileこれはほとんどの場合機能します。ただし、GitHubまたはSourceForgeからファイルをダウンロードしているときに、正しいファイルがフェッチされない場合があります。
たとえば、archinstallスクリプトをtargz形式でダウンロードしようとしていました。ファイルはリリースページにあります。
このソースコードリンクをブラウザで開くと、.tar.gz形式のソースコードが表示されます。
ただし、ターミナルを使用してcurlコマンドを使用して同じファイルをダウンロードすると、正しいアーカイブ形式ではない小さなファイルが表示されます。
tar -zxvf v2.4.2.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
正確なファイルタイプを知るためにfileコマンドを実行すると、それがHTMLドキュメントであることがわかります。
file v2.4.2.tar.gz
v2.4.2.tar.gz: HTML document, ASCII text, with no line terminators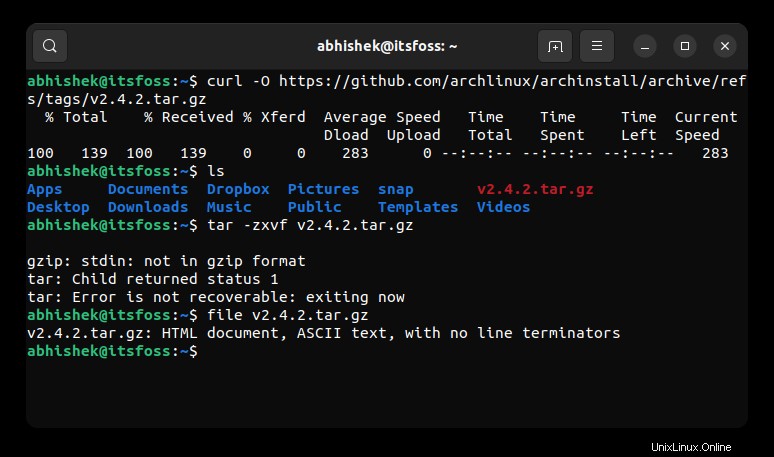
アーカイブzipまたはtarballの代わりにHTMLドキュメント?問題はどこにありますか?簡単な修正方法を紹介します。
ここでの問題は、使用しているURLが実際のアーカイブファイルにリダイレクトされることです。これを取得するには、追加のオプションを使用する必要があります。
curl -JLO URL_of_the_fileオプションは任意の順序にすることができます。 J LO(ジェニファー・ロペス)を覚えるのは簡単です。
curlコマンドのマニュアルページに基づいたオプションの簡単な説明は次のとおりです。
- J:このオプションは、URLからファイル名を抽出する代わりに、サーバー指定のContent-Dispositionファイル名を使用するように-O、-remote-nameオプションに指示します。
- L:リクエストされたページが別の場所(Location:ヘッダーと3XX応答コードで示される)に移動したことをサーバーが報告した場合、このオプションにより、curlは新しい場所でリクエストをやり直します。
- O:このオプションを使用すると、ダウンロード用の出力ファイル名を指定する必要はありません。
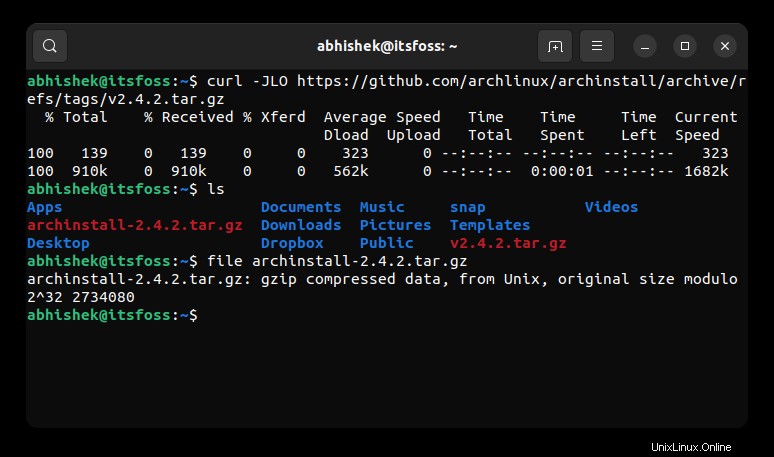
下のスクリーンショットでわかるように、今回はcurl-JLOオプションを使用して正しいファイルをダウンロードできました。
ボーナスのヒント:ログインする必要がありますか?
これは公開ファイルに対して機能します。ただし、プライベートリポジトリまたはGitLabからファイルをダウンロードしようとすると、ログインページへのリダイレクトに関するメッセージが表示される場合があります。
<html><body>You are being <a href="https://gitlab.com/users/sign_in">redirected</a>.</body></html>
このような場合は、APIトークンに-Hオプションを付けてください。
この簡単なヒントが、Curlでアーカイブファイルを正しくダウンロードするのに役立つことを願っています。それでもcurlのダウンロードで問題が発生する場合はお知らせください。