Linuxを通常の作業またはソフトウェアの開発と展開に使用している場合は、grepコマンドに出くわしたはずです。
この説明記事では、grepコマンドとは何で、どのように機能するかを説明します。
grepとは何ですか?
Grepは、UnixおよびLinuxシステムのコマンドラインユーティリティです。特定のファイルのコンテンツで検索パターンを見つけるために使用されます。
その珍しい名前で、grepは頭字語であると推測したかもしれません。これは少なくとも部分的には真実ですが、誰に尋ねるかによって異なります。
評判の良い情報源によると、この名前は実際にはedと呼ばれるUNIXテキストエディタのコマンドに由来しています。ここで、入力 g / re / p 正規表現のグローバル(g)検索を実行し(re)、続いて一致する行を出力しました(p)。
grepコマンドは、g / re/pコマンドがエディターで実行したことを実行します。正規表現のグローバル調査を行い、印刷します。大きなファイルの検索ははるかに高速です。

これは公式の物語ですが、 Gと記載されている場合もあります。 ローブR egular E 表現( P rocessor | P arser | P リンター)。正直なところ、それはすべてを行います。
grepの作成の背後にある興味深い話
ケントンプソンは、コンピュータサイエンスにいくつかの信じられないほどの貢献をしました。彼はUnixの作成を支援し、そのモジュラーアプローチを普及させ、grepを含む多くのプログラムを作成しました。
Thompsonは、ベル研究所の同僚の1人を支援するためにgrepを構築しました。この科学者の目標は、言語パターンを調べて、フェデラリストペーパーの著者(アレクサンダーハミルトンを含む)を特定することでした。この広範な作品は、合衆国憲法を擁護するために起草された85の匿名の記事とエッセイのコレクションでした。しかし、これらの記事は匿名であったため、科学者は言語パターンに基づいて著者を特定しようとしていました。
オリジナルのUnixテキストエディタed(これもThompsonによって作成されました)は、当時のハードウェアの制限を考えると、このような大量のテキストを検索することはできませんでした。そのため、Thompsonは、検索機能をedエディターから独立したスタンドアロンユーティリティに変換しました。
あなたがそれについて考えるならば、それはアレクサンダーハミルトンが技術的にgrepの作成を助けたことを意味します。ハミルトンのウォッチパーティーで、この楽しい事実を友達と気軽に共有してください。 🤓
正規表現とは何ですか?
正規表現(または正規表現)は、検索クエリのようなものと考えることができます。正規表現は、テキストの識別、照合、またはその他の方法で管理するために使用されます。
ただし、正規表現はキーワード検索以上の機能を備えています。考えられるあらゆる種類のパターンを見つけるために使用できます。メタ文字を使用すると、パターンを簡単に見つけることができます。この検索ツールをはるかに強力にするこれらの特殊文字。

grepは正規表現を使用するツールの1つにすぎないことに注意してください。ツールの範囲全体で同様の機能がありますが、メタ文字と構文は異なる場合があります。これは、特定の正規表現プロセッサのルールを知ることが重要であることを意味します。
grepの実用的な例:電話番号の照合
このツールは、初心者にも経験豊富なLinuxユーザーにも同様に威圧的です。残念ながら、電話番号のような比較的単純なパターンでも、「怖い」正規表現文字列になる可能性があります。
このような表現を見ても慌てる必要はありませんので、ご安心ください。正規表現の基本に慣れると、コンピューティングの可能性の新しい世界を開くことができます。
文化的なメモ :この例では、電話番号に米国(NANP)の規則を使用しています。これらは、市外局番(3桁)に分割された10桁のIDであり、最初の3桁が中央通信局(プレフィックスと呼ばれる)に対応し、最後の4桁が回線と呼ばれる一意の7桁の組み合わせです。番号。したがって、パターンはAAA-PPP-LLLLです。
phone.txtというファイルを作成しました 同じ電話番号の4つの一般的なバリエーションを書き留めます。形式に関係なく、grepを使用して数値パターンを認識します。
また、コントロールとして使用する式に準拠しない行を1行追加しました。最終行555!123!1234 は標準の電話番号パターンではなく、grep式によって返されることはありません。
phone.txtの内容 ファイルは次のとおりです:
example@unixlinux.online:~$ cat phone.txt
5551231234
555 123 1234
555-123-1234
(555)-123-1234
555!123!1234
電話番号を「grep」するために、メタ文字を使用して正規表現を記述し、関連するデータを分離して、不要なものを無視します。
完全なコマンドは次のようになります:
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
少し強烈に見えますよね?何が起こっているのかをよりよく理解するために、それをチャンクに分割しましょう。
一度に1つのセグメントで、正規表現を理解する
まず、電話番号で「市外局番」を探す正規表現のセクションを分離しましょう。
同様のパターンが部分的に繰り返され、残りの数字も取得されます。市外局番が括弧で囲まれている場合があることに注意することが重要です。そのため、ここでの式でそれを説明する必要があります。
市外局番セクション全体のロジックは、エスケープされた丸括弧のセットにカプセル化されています。私のコードが\(で始まることがわかります \)で終わります 。
角かっこを使用する場合[0-9] 、0から9までの数字を探していることをgrepに通知します。同様に、 [a-z]を使用できます。 アルファベットの文字と一致します。
中括弧内の数字{3\} 、は、中括弧内の項目が正確に3回一致することを意味します。
まだ混乱していますか?ストレスを感じないでください。自信を持って前進できるように、この例をいくつかの方法で見ていきます。
擬似コードの市外局番セクションのロジックを見てみましょう。式の各セグメントを分離しました。
- \(
- (3桁の数字)
- |
- 3桁の数字
- \)
うまくいけば、このように見ると正規表現がより簡単になります。平易な言葉であなたは3桁の数字を探しています。各桁は0〜9で、またはがあります。 市外局番を括弧で囲まない場合があります。
次に、最初のセクションの最後にこの奇妙な部分があります。
- [-] \?
どういう意味ですか? \? 記号は「0または前の文字の1つに一致する」ことを意味します。ここでは、角括弧内にあるものを参照しています [-] 。
つまり、数字の後にハイフンがある場合とない場合があります。
それでは、実際のコードを使用して同じブロックを再構築しましょう。次に、式の他の部分を追加します。
- \(
- ([0-9] \ {3 \})
- |
- [0-9] \ {3 \}
- \)
- [-] \?
電話番号のパターンを完成させるには、既存のコードの一部を再利用するだけです。
[0-9]\{3\}[ -]\?
プレフィックスを囲む括弧について心配する必要はありませんが、-がある場合とない場合があります。 電話番号のプレフィックスと回線番号の間。
電話番号の最後のセクションでは、他の文字を探す必要はありませんが、余分な数字を反映するように式を更新する必要があります。
[0-9]\{4\}
それでおしまい。次に、予期しない動作を最小限に抑えるために、式が引用符で囲まれていることを確認しましょう。
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
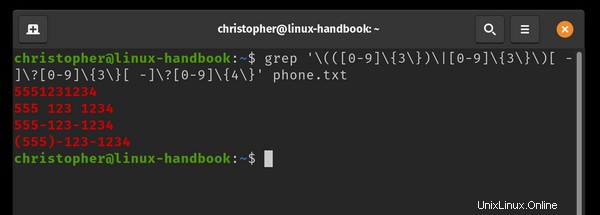
結果がカラーで強調表示されていることがわかります。これは、Linuxディストリビューションのデフォルトの動作ではない可能性があります。
結果を強調表示したい場合は、-color =autoを追加できます。 あなたの命令に。 grep と入力するたびに、これをエイリアスとしてシェルプロファイルに追加することもできます。 grep --color =autoとして実行されます 。
これで、grepコマンドについて理解を深めていただければ幸いです。私は物事を説明するためにほんの一例を示しました。興味がある場合は、この記事でgrepコマンドのより実用的な例を確認してください。
コメントを残して、記事に関する提案を提供してください。