ワードプロセッサを使用する場合、行がターゲットデバイスの使用可能なスペースに収まるようにテキストをフォーマットすることは問題にはなりません。しかし、ターミナルで作業するとき、物事はそれほど簡単ではありません。
もちろん、お気に入りのテキストエディタを使用していつでも手作業で線を切ることができますが、これが望ましいことはめったになく、自動処理の問題から外れています。
うまくいけば、POSIXのfold ユーティリティとGNU/BSD fmt コマンドは、行が指定された長さを超えないようにテキストをリフローするのに役立ちます。
Unixの行は何ですか?
foldの詳細に入る前に およびfmt コマンド、最初に私たちが話していることを定義しましょう。テキストファイルでは、1行は任意の数の文字で構成され、その後に特別な改行制御シーケンス( 行末の場合はEOLと呼ばれることもあります)が続きます。 )
Unixライクなシステムでは、行末制御シーケンスは(唯一の)文字改行で構成されます。 、LFと省略されることもあれば、\nと書かれることもあります C言語から継承された規則に従います。バイナリレベルでは、改行文字は0aを保持するバイトとして表されます。 16進値。
hexdumpを使用して簡単に確認できます この記事では、ユーティリティを頻繁に使用します。そのため、そのツールに慣れるための良い機会かもしれません。たとえば、以下の16進ダンプを調べて、各echoコマンドによって送信された改行文字の数を見つけることができます。解決策があると思ったら、| hexdump -C 正しく推測したかどうかを確認するための一部です。
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007
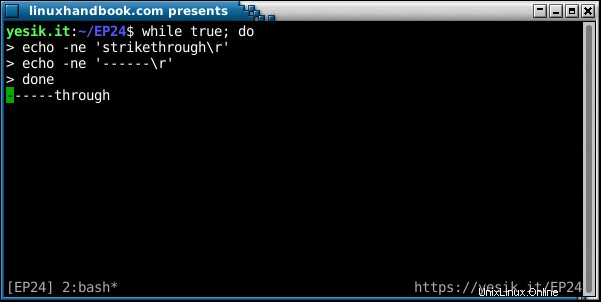
この時点で言及する価値があるのは、異なるオペレーティングシステムが改行シーケンスに関して異なる規則に従う可能性があるということです。上で見たように、Unixライクなオペレーティングシステムはラインフィードを使用しています。 文字ですが、Windowsは、ほとんどのインターネットプロトコルと同様に、2つの文字を使用しています。キャリッジリターン+ラインフィード ペア(CRLF、または0d 0a 、または\r\n )。 「クラシック」MacOS(2000年代初頭のMacOS 9.2まで)では、Appleコンピュータは改行文字としてCRのみを使用していました。他のレガシーコンピュータもLFCRペアを使用しており、古いASCII互換システムの場合は完全に異なるバイトシーケンスを使用していました。幸いなことに、後者は過去の遺物であり、今日使用されているEBCDICコンピューターが表示されることはないと思います。
歴史について言えば、興味があれば、「キャリッジリターン」と「ラインフィード」の制御文字の使用は、テレタイプ時代に使用されたBaudotコードにまでさかのぼります。古い映画に描かれているテレタイプを、部屋サイズのコンピューターへのインターフェースとして見たことがあるかもしれません。しかし、それ以前でも、テレタイプはポイントツーポイントまたはマルチポイント通信に「スタンドアロン」で使用されていました。当時、典型的な端末は、メカニカルキーボード、紙、およびプリントヘッドを保持する移動式キャリッジを備えた重いタイプライターのように見えました。新しいラインを開始するには、キャリッジを左端に戻す必要があり、プラテン(「シリンダー」と呼ばれることもあります)を回転させて用紙を上に移動する必要があります。これらの2つの動きは、2つの独立した電気機械システムによって制御され、ラインフィードとキャリッジリターンの制御文字は、デバイスのこれら2つの部分に直接配線されています。プラテンを回転させるよりもキャリッジの移動に時間がかかるため、最初にキャリッジリターンを開始するのが論理的でした。 2つの機能を分離すると、オーバープリント(CRのみを送信することによる)や「ダブルインターライン」(1つのCR + 2つのLF)の効率的な送信を可能にするなど、いくつかの興味深い副作用もありました。
このセクションの冒頭の定義は、主に論理的 行はです。ただし、ほとんどの場合、その「任意に長い」論理線は物理的で送信する必要があります。 利用可能なスペースが限られている、画面やプリンターなどのデバイス。より大きな物理ラインを持つデバイスに短い論理ラインを表示することは問題ではありません。単にテキストの右側に未使用のスペースがあります。しかし、デバイスの使用可能なスペースよりも大きいテキスト行を表示しようとするとどうなりますか?実際には、2つの解決策があり、それぞれに欠点があります。
- まず、デバイスは切り捨てできます 物理的なサイズの行。したがって、コンテンツの一部がユーザーに表示されません。一部のプリンタ、特にダムプリンタはこれを実行します(もちろん、特に過酷な環境や汚れた環境では、現在でも基本的なドットマトリックスプリンタが使用されています!)
- 長い論理行を表示する2番目のオプションは、それらを複数の物理行に分割することです。これは行の折り返しと呼ばれます 線が使用可能なスペースを包み込むように見えるため、ターミナルエミュレータを使用する場合のように、ディスプレイのサイズを変更できる場合に特に効果が見られます。
これらの自動動作は非常に便利ですが、デバイスの物理的なサイズに関係なく、特定の位置で長い行を分割したい場合があります。たとえば、画面とプリンタの両方の同じ位置で改行を発生させたい場合に便利です。または、行の折り返しを実行しないアプリケーションでテキストを使用する必要があるため(たとえば、プログラムでテキストをSVGファイルに埋め込む場合)。最後に、信じられないかもしれませんが、IRCやSMTPなどの一般的なものを含め、送信に最大線幅を課す通信プロトコルはまだたくさんあります(エラー550最大線長を超えた場合は私が何であるかを知っていますについて話す)。そのため、長い行を小さなチャンクに分割する必要がある場合がたくさんあります。これはPOSIXのfoldの仕事です コマンド。
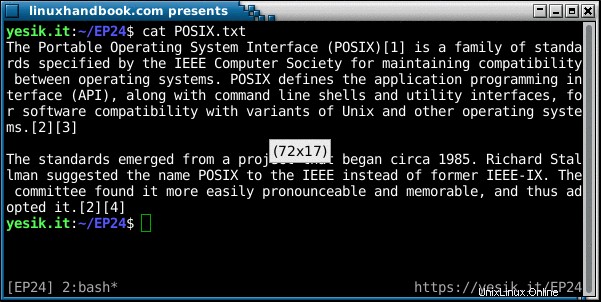
オプションなしで使用すると、fold コマンドは、80文字の制限を超える行がないように、改行制御シーケンスを追加します。明確にするために、1行には最大で80文字と改行シーケンスが含まれます。
その記事のサポート資料をダウンロードした場合は、自分で試すことができます:
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]
-wを使用して、最大出力行長を変更できます。 オプション。もっと興味深いのは、おそらく-sの使用です。 単語の境界で行が途切れるのを確実にするオプション。 -sを使用した場合と使用しない場合の結果を比較してみましょう サンプルテキストの2番目の段落に適用する場合のオプション:
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]
明らかに、テキストに最大行長より長い単語が含まれている場合、foldコマンドは-sを尊重できません。 国旗。その場合、fold ユーティリティは、最大の位置で特大の単語を分割し、常に最大許容幅を超える行がないことを確認します。
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!
すべてではないにしても、ほとんどのコアユーティリティと同様に、fold コマンドは一度に1文字が1バイトに相当するように設計されました。ただし、これは、特にUTF-8が広く採用されている現代のコンピューティングでは、もはや当てはまりません。不幸な問題につながる何か:
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
「élève」(フランス語で「学生」を意味する)という単語には、2つのアクセント付き文字が含まれています。é (ラテン語の小さな文字E、ACUTE付き)およびè (ラテン語の小さな文字EとGRAVE)。 UTF-8文字セットを使用して、これらの文字はそれぞれ2バイトを使用してエンコードされます(それぞれ、c3 a9 およびc3 a8 )、アクセントのないラテン文字の場合のように1バイトだけではなく。 hexdumpを使用して生のバイトを調べることで、それを確認できます。 効用。 éに対応するバイトシーケンスを正確に特定できるはずです。 およびè 文字。ちなみに、そのダンプには、16進コードが前述したラインフィード文字が含まれていることもわかります。
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008次に、foldコマンドによって生成された出力を調べてみましょう。
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
明らかに、foldによって生成された結果 コマンドは、余分な改行があるため、元の文字列よりもわずかに長くなります。それぞれ、改行を含めて11バイト長と8バイト長です。そういえば、foldの出力で 改行を見たことがあるかもしれないコマンド(0a )2バイトごとに表示される文字。そして、これはまさに問題です。foldコマンドは byteで行を壊しました 文字ではなく位置 位置。そのブレークがマルチバイト文字の途中で発生したとしても!結果の出力が有効なUTF-8バイトストリームではなくなったことを言及する必要はありません。したがって、Unicode置換文字(� )無効なバイトシーケンスのプレースホルダーとしての私の端末による。
cutのように 数週間前に書いたコマンドですが、これはfoldのGNU実装の制限です。 ユーティリティであり、これは、「文字の途中で線を壊してはならない」と明示的に述べているPOSIX仕様とは明らかに反対です。
したがって、GNU foldのように見えます 実装は、固定長の1バイト文字エンコーディング(US-ASCII、Latin1など)のみを適切に処理します。回避策として、適切な文字セットが存在する場合は、テキストを処理する前に1バイトの文字エンコードにトランスコードし、後でUTF-8にトランスコードして戻すことができます。ただし、控えめに言っても、これは面倒です。
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
e
非常に残念だったので、他の実装の動作を確認することにしました。よくあることですが、foldのOpenBSD実装 ユーティリティはPOSIXに準拠しており、LC_CTYPEを尊重するため、この点ではるかに優れています。 マルチバイト文字を適切に処理するためのロケール設定:
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aご覧のとおり、OpenBSDの実装は文字で適切に行をカットします。 それらをエンコードするために必要なバイト数に関係なく、位置。圧倒的多数のユースケースでは、これが必要です。ただし、1バイトを1文字と見なすレガシー(つまりGNUスタイル)の動作が必要な場合は、現在のロケールをいわゆるPOSIXロケール(定数「POSIX」または歴史的な理由で「C」で識別される)に一時的に変更できます。 ”):
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
最後に、POSIXは-bを指定します foldを指示するフラグ バイトで行の長さを測定するユーティリティ 、ただし、それでもマルチバイト文字が保証されます(現在のLC_CTYPEによると) ロケール設定)はしない 壊れます。
演習として、現在のロケールを「C」(上記)に変更して得られた結果と-b 代わりにフラグを立てます(下)。微妙かもしれません。しかし、 違い:
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bそれで、違いを見つけましたか?
ロケールを「C」に変更すると、fold ユーティリティはマルチバイトシーケンスを処理しませんでした。定義上、ロケールが「C」の場合、ツールは1文字が1バイトであると想定する必要があるためです。 。したがって、 である一連のバイトの途中であっても、どこにでも改行を追加できます。 別の文字エンコードではマルチバイト文字と見なされています。これは、ツールがc3 0a a8を生成したときに起こったこととまったく同じです。 バイトシーケンス:2バイト c3 a8 1文字として理解されます LC_CTYPEの場合 文字エンコードをUTF-8として定義します。ただし、同じバイトシーケンスは2文字と見なされます。 「C」ロケールの場合:
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 chars
一方、-bでは オプションの場合でも、ツールはマルチバイト対応である必要があります。このオプションが変更されるのは、位置のカウント方法だけです。 、今回はデフォルトの文字ではなく、バイト単位で。その場合、マルチバイトシーケンスは分割されないため、結果の出力は有効な文字ストリームのままになります(現在のLC_CTYPEによる) ロケール設定):
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
ve
ご覧のとおり、Unicode置換文字(�)はもう発生していません )、そしてその過程で意味のある文字を失うことはありませんでした。今回は、可変数の文字を含む行で終わることを犠牲にしておよび 可変バイト数。最後に、すべてのツールは、-wで要求されたよりも多くのバイトが1行にないことを確認します オプション。 wcを使用して確認できるもの ツール:
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars ve
もう一度、上記の例を研究するために必要な時間を取ってください。 printfを利用します およびwc 以前は詳しく説明しなかったコマンド。したがって、状況が十分に明確でない場合は、コメントセクションを使用して説明を求めることを躊躇しないでください!
好奇心から-bをチェックしました GNU foldを使用してDebianボックスにフラグを立てる 実装:
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
-bの違いを見つけるために時間を費やさないでください および非-b その例のバージョン:GNU foldの実装はマルチバイトに対応していないため、両方の結果は同じです。確信が持てない場合は、diff -sを使用できます。 コンピュータに確認させるコマンド。その場合は、コメントセクションを使用して、使用したコマンドを他のリーダーと共有してください。
とにかく、それは-bを意味しますか foldのGNU実装では役に立たないオプション 効用?さて、foldのGNUCoreutilsドキュメントをもっと注意深く読むことによって コマンド、-bを見つけました オプションは特殊文字のみを扱います 通常モードではそれぞれ1〜8(1〜8)または-1(マイナス1)の位置をカウントするタブまたはバックスペースのようですが、バイトモードでは常に1の位置をカウントします。紛らわしい?ですから、それについてもっと詳しく説明するのに少し時間がかかるかもしれません。
扱うテキストファイルのほとんどには、印刷可能な文字と行末シーケンスのみが含まれています。ただし、場合によっては、一部の制御文字がデータに侵入することがあります。タブ文字(\t )はそのうちの1つです。ごくまれに、バックスペース(\b )も発生する可能性があります。名前が示すように、カーソルを1つの位置だけ後方に移動させるのは制御文字であるため、ここでまだ言及します。 (左に向かって)一方、他のほとんどのキャラクターはそれを前進させています (右に向かって)
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]
これはブラウザに表示されない場合があるため、端末でテストすることを強くお勧めします。ただし、タブ文字(\t )出力のいくつかの位置を占めます。そして、バックスペース?出力に何かおかしなことがあるようですね。したがって、テキスト文字列をいくつかの部分に分割し、sleepを挿入して、少し速度を落としましょう。 それらの間:
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''わかった?今回は見ましたか?イベントのシーケンスを分解してみましょう:
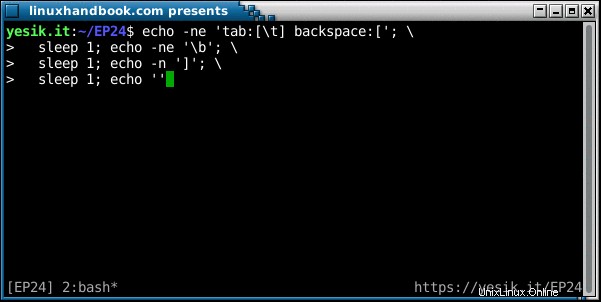
- 最初の文字列は、2番目の角かっこまで「通常」表示されます。
-nのため フラグ、echoコマンドはしない 改行文字を送信して、カーソルが同じ行に留まるようにします。 - 最初の睡眠。
- バックスペースが発行され、カーソルが1つ後ろに移動します。まだ改行がないため、カーソルは同じ行に残ります。
- 2回目の睡眠。
- 閉じ角かっこが表示されます。上書き 冒頭のもの。
- 3回目の睡眠。
-
-nがない場合 オプション、最後のechoコマンドは最終的に改行文字を送信し、カーソルは次の行に移動し、シェルプロンプトが表示されます。
もちろん、覚えていれば、キャリッジリターンを使用して同様のクールな効果を得ることができます:
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good bye
curlのようなコマンドラインユーティリティはすでに見たことがあると思います。 、wget またはffmpeg プログレスバーを表示します。彼らは\bの組み合わせを使って魔法をかけます および/または\r 。
興味深いことに、議論はそれ自体である可能性がありますが、ここでのポイントは、これらの文字の処理がfoldにとって困難な場合があることを理解することでした。 効用。うまくいけば、POSIX標準はルールを定義します:
-bを使用すると、これらの特別な処理はすべて無効になります オプション。その場合、とりわけ制御文字は1 バイトで(正しく)カウントされます。 したがって、他のキャラクターと同じように、位置カウンターを1つだけ増やします。
理解を深めるために、次の2つの例を自分で調べてみましょう(おそらくhexdumpを使用します) 効用)。これで、「hello」が「hell」になった理由と、出力の「i」が正確にどこにあるかを見つけることができるはずです(表示されていない場合でも、そこにあるので!)いつものように、助けが必要な場合、または単に調査結果を共有したい場合は、コメントセクションがあなたのものです。
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
ye
fold これまでに調査したコマンドは、特にフォーマットの目的で、長い論理行を小さな物理行に分割するように設計されています。
つまり、各入力行は自己完結型であり、他の行とは独立して分割できると想定しています。ただし、これが常に当てはまるとは限りません。たとえば、私が受け取った非常に重要なメールについて考えてみましょう。
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81
明らかに、線はすでに一定の幅に分割されています。 awk コマンドによると、ここでの最大行幅は…81文字で、改行シーケンスを除きます。はい、それは十分に奇妙だったので、私はそれを再確認しました。実際、最長の行には80の印刷可能な文字と、81番目の位置に1つの余分なスペースがあり、その後に改行文字があります。おそらく、この椅子の「メーカー」を代表して作業しているIT担当者は、この記事を読むことで利益を得ることができます。
とにかく、そのメールのフォーマットを変更したいとすると、foldで問題が発生します 既存の改行のためにコマンド。必要に応じて、以下の2つのコマンドを自分で確認できますが、いずれも期待どおりに機能しません。
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtすべての行がすでに100文字より短いため、最初の行は単に何もしません。 2番目のコマンドに関しては、60番目の位置で行を分割しますが、結果がギザギザになるように、既存の改行文字を保持します。特に3番目の段落で表示されます:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.3番目の段落の最初の行は53の位置で途切れていました。これは、1行あたり最大60文字の幅と一致しています。ただし、その改行文字がすでにだったため、2行目は位置25で壊れました。 入力ファイルに存在します。つまり、段落のサイズを適切に変更するには、新しいターゲット位置で段落を分割する前に、まず行を再結合する必要があります。
sedを使用できます またはawk 行に再参加します。そして実際のところ、紹介ビデオで述べたように、それはあなたにとって良い挑戦になるでしょう。したがって、コメントセクションにソリューションを投稿することを躊躇しないでください。
私自身は、fmtを見て、より簡単な方法をたどります。 指図。 POSIX標準コマンドではありませんが、GNUとBSDの両方の世界で利用できます。したがって、システムで使用できる可能性が高くなります。残念ながら、標準化の欠如は、後で見るように、いくつかの否定的な影響を及ぼします。しかし、とりあえず、良い部分に集中しましょう。
fmtコマンド
fmt コマンドはfoldよりも進化しています コマンドとより多くのフォーマットオプションがあります。最も興味深い部分は、空の行に基づいて入力ファイル内の段落を識別できることです。つまり、次の空の行(またはファイルの終わり)までのすべての行が最初に結合されて、以前にテキストの「論理行」と呼んだものが形成されます。その後、fmt コマンドは、要求された位置でテキストを分割します。
例のメールの2番目の段落に適用するとどうなるか見てみましょう:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.
ちなみに、fmt 最初の行にもう1つの単語をパックするコマンドが受け入れられました。しかし、さらに興味深いことに、2行目が埋められました。つまり、「chiavari」(これは何ですか?)という単語が破棄された後、入力ファイルにすでに存在する改行文字です。もちろん、物事は完璧ではなく、fmt 段落検出アルゴリズムは、メールの最後の挨拶(出力の14行目)のように、誤検知をトリガーすることがあります:
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards Doris
先ほどfmt コマンドは、foldよりも進化したテキストフォーマットツールでした 効用。確かにそうです。一見わかりにくいかもしれませんが、10〜11行目を注意深く見ると、 2 ドットの後のスペース—文の終わりに2つのスペースを使用するという最も議論されている慣習を強制します。文の間に2つのスペースを使用する必要があるかどうかを知るためにその議論に入るつもりはありませんが、ここでは実際の選択はありません。私の知る限り、fmtの一般的な実装はありません。 コマンドは、文の後のダブルスペースを無効にするフラグを提供します。そのようなオプションがどこかに存在し、私がそれを逃した場合を除いて?その場合は、コメントセクションを使用してそのことを知らせていただければ幸いです。フランスの作家として、私は文の後に「ダブルスペース」を使用したことはありません…
fmt ユーティリティは、foldコマンドよりも多くのフォーマット機能を使用して設計されています。ただし、POSIXで定義されていないため、GNUオプションとBSDオプションの間には大きな非互換性があります。
たとえば、-c オプションは、BSDの世界ではテキストを中央揃えにするために使用されますが、GNUCoreutilsのfmtでは これにより、クラウンマージンモードが有効になります。 「段落内の最初の2行のインデントを維持し、後続の各行の左マージンを2行目の左マージンに揃えます。 「
GNU fmt -cを使って自分で実験してみましょう お望みならば。個人的には、BSDのテキストセンタリング機能は、奇妙な点があるため、研究するのがより興味深いと思います。実際、OpenBSDでは、fmt -c will center the text according to the target width— but without reflowing it! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
If you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt コマンド:
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards Doris
I will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w オプション。 Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN 。 Moreover you can use that shortcut both with the fold and fmt commands:so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
As the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!