Webロボットの主な仕事は、Webサイトやページをクロールまたはスキャンして情報を探すことです。彼らは検索エンジンや他のアプリケーションのデータを収集するためにたゆまぬ努力をしています。一部の人にとっては、ページを検索エンジンから遠ざけるのには十分な理由があります。サイトへのアクセスを微調整する場合でも、Googleの結果に表示せずに開発サイトで作業する場合でも、robots.txtファイルを実装すると、ウェブクローラーとボットは収集できる情報を知ることができます。
Robots.txtファイルとは何ですか?
robots.txtは、RobotsExclusionStandardに準拠したサイトのルートにあるプレーンテキストのウェブサイトファイルです。たとえば、www.yourdomain.comには、www.yourdomain.com/robots.txtにrobots.txtファイルがあります。このファイルは、クローラーへのアクセスを許可またはブロックする1つ以上のルールで構成されており、クローラーをWebサイトの指定されたファイルパスに制限します。デフォルトでは、特に指定がない限り、すべてのファイルが完全にクロールを許可されています。
robots.txtファイルは、クローラーによって分析される最初の側面の1つです。サイトに含めることができるrobots.txtファイルは1つだけであることに注意してください。ファイルは1つまたは複数のページまたはサイト全体に実装され、検索エンジンがWebサイトの詳細を表示しないようにします。
この記事では、robots.txtファイルを作成するための5つの手順と、ボットを寄せ付けないために必要な構文について説明します。
Robots.txtファイルを設定する方法
1。 Robots.txtファイルを作成する
ドメインのルートにアクセスできる必要があります。あなたのウェブホスティングプロバイダーは、あなたが適切なアクセス権を持っているかどうかについてあなたを支援することができます。
ファイルの最も重要な部分は、その作成と場所です。任意のテキストエディタを使用してrobots.txtファイルを作成し、次の場所にあります:
- ドメインのルート:www.yourdomain.com/robots.txt。
- サブドメイン:page.yourdomain.com/robots.txt。
- 非標準ポート:www.yourdomain.com:881/robots.txt。
最後に、robots.txtファイルがUTF-8でエンコードされたテキストファイルであることを確認する必要があります。 Googleやその他の一般的な検索エンジンやクローラーは、UTF-8の範囲外の文字を無視する可能性があり、robots.txtルールが無効になる可能性があります。
2。 Robots.txtユーザーエージェントを設定する
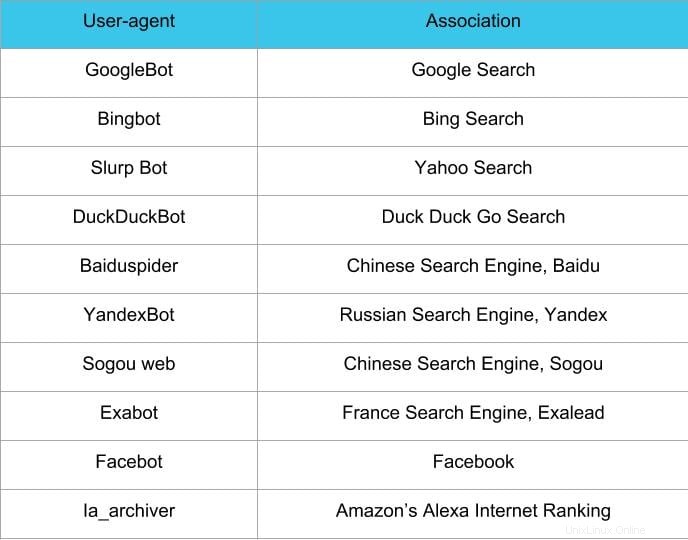
robots.txtファイルを作成する方法の次のステップは、 user-agentを設定することです 。 ユーザーエージェント 許可またはブロックするWebクローラーまたは検索エンジンに関連します。いくつかのエンティティがuser-agentである可能性があります 。以下に、いくつかのクローラーとその関連付けを示します。
ユーザーエージェントを確立するには、3つの異なる方法があります。 robots.txtファイル内。
1つのユーザーエージェントの作成
ユーザーエージェントの設定に使用する構文は、 User-agent:NameOfBotです。 。以下では、DuckDuckBotが唯一のユーザーエージェント 確立されました。
# Example of how to set user-agent
User-agent: DuckDuckBot複数のユーザーエージェントの作成
複数追加する必要がある場合は、DuckDuckBot user-agentの場合と同じプロセスに従います。 次の行で、追加の user-agentの名前を入力します 。この例では、Facebotを使用しました。
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebotすべてのクローラーをユーザーエージェントとして設定する
すべてのボットまたはクローラーをブロックするには、ボットの名前をアスタリスク(*)に置き換えます。
#Example of how to set all crawlers as user-agent
User-agent: *3。 Robots.txtファイルにルールを設定する
robots.txtファイルはグループで読み込まれます。グループは、 user-agentが誰であるかを指定します user-agentがどのファイルまたはディレクトリを示すかを示す1つのルールまたはディレクティブがあります。 アクセスできるかできないか。
使用されるディレクティブは次のとおりです。
- 許可しない :指定されたユーザーエージェントを必要としないルートドメインに関連するページまたはディレクトリを参照するディレクティブ クロールをすること。スラッシュ(/)で始まり、その後にフルページのURLが続きます。ページ全体ではなくディレクトリを参照している場合にのみ、スラッシュで終了します。 1つ以上の禁止を使用できます ルールごとの設定。
- 許可 :ディレクティブは、名前付きの user-agentが必要なルートドメインに関連するページまたはディレクトリを参照します。 クロールをすること。たとえば、 allowを使用します disallowをオーバーライドするディレクティブ ルール。また、スラッシュ(/)で始まり、その後にフルページのURLが続きます。ページ全体ではなくディレクトリを参照している場合にのみ、スラッシュで終了します。 1つ以上のallowを使用できます ルールごとの設定。
- サイトマップ :sitemapディレクティブはオプションであり、Webサイトのサイトマップの場所を示します。唯一の条件は、完全修飾URLでなければならないということです。必要に応じて、ゼロ以上を使用できます。
Webクローラーは、グループを上から下に処理します。前述のように、 disallowに明示的に設定されていないページまたはディレクトリにアクセスします。 。したがって、 Disallow:/を追加します user-agentの下 これらの特定のユーザーエージェントがWebサイトをクロールするのをブロックするための各グループの情報。
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /すべてのクローラーから特定のサブドメインをブロックするには、禁止ルールにスラッシュと完全なサブドメインURLを追加します。
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtディレクトリをブロックする場合は、スラッシュとディレクトリ名を追加して同じプロセスに従いますが、最後に別のスラッシュで終了します。
# Example
User-agent: *
Disallow: /images/最後に、すべての検索エンジンですべてのサイトページの情報を収集する場合は、許可のいずれかを作成できます。 または禁止 ただし、 allow を使用する場合は、必ずスラッシュを追加してください。 ルール。両方のルールの例を以下に示します。
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4。 Robots.txtファイルをアップロードする
必須ではないため、Webサイトにrobots.txtファイルが自動的に付属することはありません。作成することに決めたら、ファイルをWebサイトのルートディレクトリにアップロードします。アップロードは、サイトのファイル構造とウェブホスティング環境によって異なります。 robots.txtファイルをアップロードする方法については、ホスティングプロバイダーにお問い合わせください。
5。 Robots.txtファイルが正しく機能していることを確認します
robots.txtファイルが正しく機能することをテストおよび確認する方法はいくつかあります。これらのいずれかを使用すると、構文またはロジックにエラーが表示されます。それらのいくつかを次に示します。
- 検索コンソールにあるGoogleのrobots.txtテスター。
- Merkle、Inc.のrobots.txtバリデーターとTestingTool
- Ryteのrobots.txtテストツール。
ボーナス:WordPressでRobots.txtを使用する
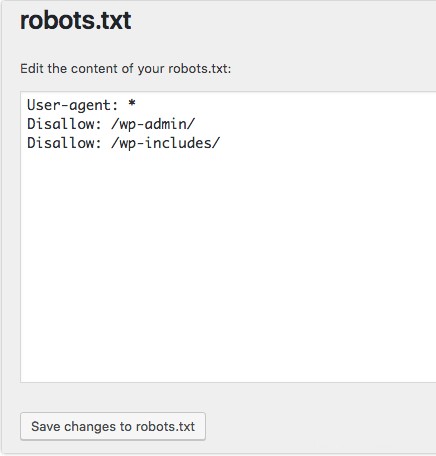
WordPressのYoastSEOプラグインを使用している場合は、管理ウィンドウ内にrobots.txtファイルを作成するためのセクションが表示されます。
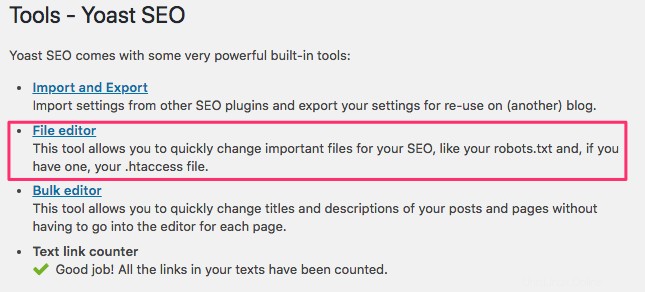
WordPress Webサイトのバックエンドにログインし、ツールにアクセスします SEOの下 セクションをクリックし、ファイルエディタをクリックします 。
前と同じ手順に従って、ユーザーエージェントとルールを確立します。以下では、WordPressのwp-adminおよびwp-includesディレクトリからWebクローラーをブロックしましたが、ユーザーとボットは他のサイトページを表示できます。終了したら、[robots.txtへの変更を保存]をクリックします robots.txtファイルをアクティブ化します。