Linuxオペレーティングシステムドメインに入ると、Linuxコマンドライン環境を介したコンピューティングの可能性のリストは終わりがないように見えます。 Linuxを使用すればするほど、学びたいと思うようになり、この渇望が無数の学習機会をもたらすからです。
このチュートリアルでは、Linuxオペレーティングシステム環境でテキストファイルの重複行をカウントして印刷する方法について説明します。このチュートリアルモジュールは、Linuxファイル管理の一部です。
Linuxコマンドラインまたはターミナル環境は、入力テキストファイルの処理に慣れていません。このような操作は非常に熟練しているため、テキストファイルの処理ではまだ価値のある課題に直面していません。
このチュートリアルでは、Linuxでランダムなテキストファイル内の重複行を識別/処理する方法について説明します。
問題の説明
このチュートリアルをより簡単で面白くするために、重複行の存在を確認するランダムファイルとして機能するサンプルテキストファイルを作成します。
$ sudo nano sample_file.txt
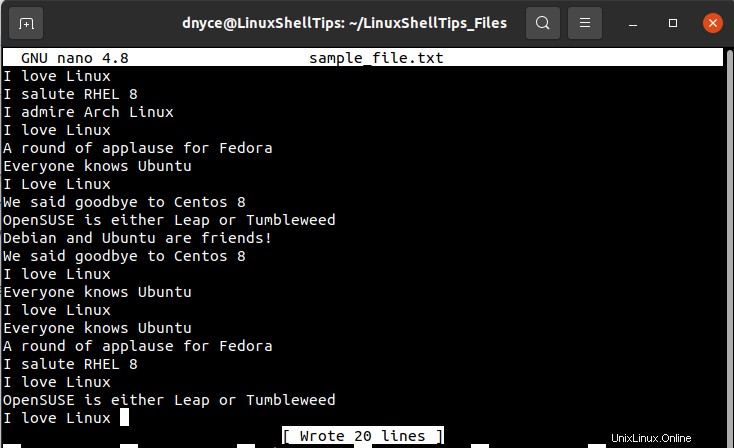
上記のテキストファイルのスクリーンキャプチャをスキャンするだけで、重複した行の存在を確認できるはずですが、正確な出現回数を確認することはできません。
発生する重複行の数を確認するために、次のLinuxコマンドライン/ターミナルベースのアプローチからソリューションを見つけます。
sortおよびuniqコマンドを使用してファイル内の重複行を検索する
uniqを使用する便利さ コマンドは、-cが付属していることです コマンドオプション。ただし、このコマンドオプションは、ターゲット/スキャンするテキストファイルに隣接する行が重複している場合にのみ有効です。
uniqの使用中にこの不便を回避するため 重複した行を印刷するコマンドターゲットのテキストファイル内で繰り返される/重複する行をグループ化するsortコマンドアプローチを借用する必要があります。
つまり、最初にターゲットのテキストファイルをソート経由で渡します。 コマンドを実行し、後でそれを uniqにパイプします -cを伴うコマンド 以下に示すコマンドオプション:
$ sort sample_file.txt | uniq -c
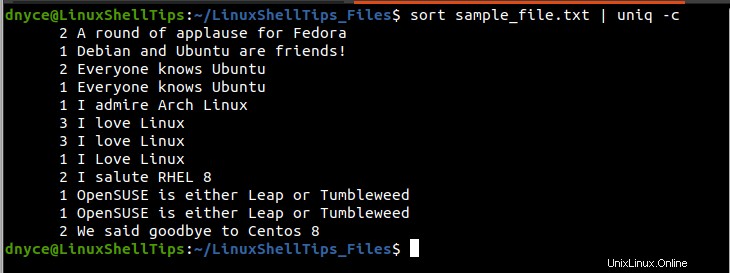
上記の出力の最初の列(左側)は、右側の列に印刷された行が sample_file.txt内に表示される回数を示します。 テキストファイル。たとえば、「IloveLinux」という行 テキストファイル内で合計7回複製/繰り返されます(3 + 3 + 1)。
Awkコマンドを使用してファイルに重複行を印刷する
awk この「テキストファイルに重複した行を印刷する」を解決するコマンド 」問題は単純なワンライナーです。それがどのように機能するかを理解するには、最初に以下に示すように実装する必要があります:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
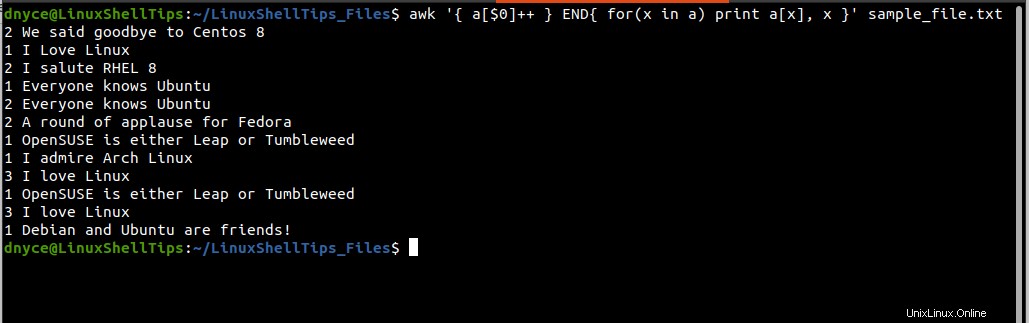
上記のコマンドを実行すると、2つの列が出力されます。最初の列は、テキストファイル内に繰り返される/重複する行が表示される回数をカウントし、2番目の列は問題の行を指します。
ただし、上記のコマンドの出力は、 sortの出力ほど整理されていません。 およびuniq コマンド。
Linuxオペレーティングシステム環境でテキストファイルに重複した行を印刷する方法については、正常に説明しました。