Linux管理者または上級ユーザーとして、使用しているLinuxオペレーティングシステムディストリビューションでファイル管理をマスターすることが最も重要です。ファイル管理はLinuxオペレーティングシステム管理のコアな側面であり、ファイル管理がなければ、ファイル暗号化、ファイルユーザー管理、ファイルコンプライアンス、ファイル更新とメンテナンス、ファイルライフサイクル管理などのファイル関連機能を採用することはできません。
>この記事では、大きなファイルを特定の行番号の部分に分割するLinuxファイル管理の重要な側面について説明します。この記事の目的が、ファイルの行番号を考慮せずに大きなファイルを管理可能な小さなファイルに分割することだけだった場合、必要なのは分割の利便性だけです。 コマンド。
サンプル参照ファイル
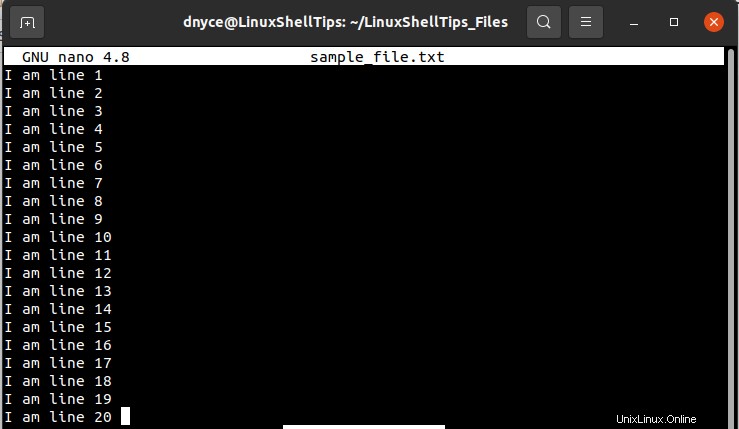
このチュートリアルを理解するために、指定された行番号から分割したい大きなファイルとして機能するサンプルテキストファイルを紹介します。サンプルテキストファイルを作成し、図のように入力します。
$ sudo nano sample_file.txt
catコマンドでこのファイルを開き、関連する行番号をメモします。
$ cat -n sample_text.txt
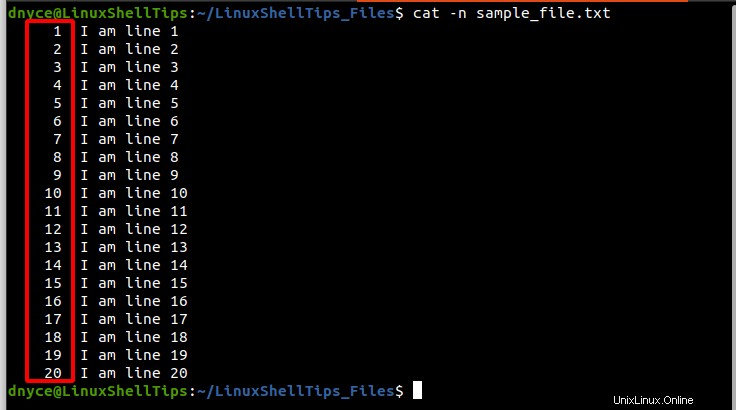
お気づきのとおり、上記のファイルには 1があります 〜 20 行番号。ここで、このファイルを 4に分割するとします。 行番号5のパーツ 、 11 、および 17 。
結果として次のファイルが作成されます:
- sample_file.txtの1行目から5行目を含むfile_1。
- sample_file.txtの6行目から11行目を含むfile_2。
- sample_file.txtの12行目から17行目を含むfile_3。
- sample_file.txtの18行目から20行目を含むfile_4。
問題の説明を理解したので、実行可能なソリューションに必要な方法論を見てみましょう。
1。ヘッドコマンドとテールコマンドの使用
これらの2つのコマンドを組み合わせて、提供された行番号から大きなファイルを部分に分割するには、-nを含める必要があります。 コマンド実行の一部としてのオプション。
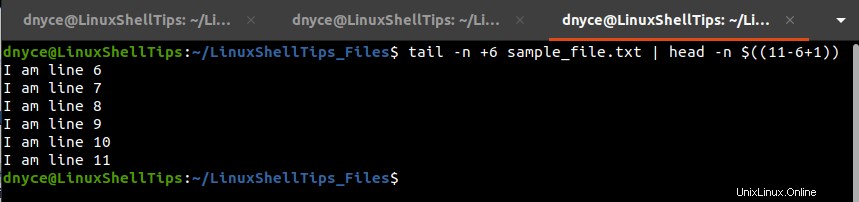
行番号を抽出するには6 〜 11 、次のコマンドを実行します。
$ tail -n +3 sample_file.txt | head -n $(( 11-6+1 ))
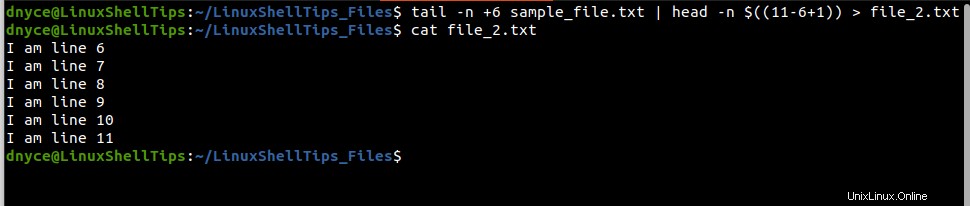
この出力をfile_2.txtに保存するには :
$ tail -n +6 sample_file.txt | head -n $((11-6+1)) > file_2.txt $ cat file_2.txt
2。 sedコマンドの使用
sed以降 コマンドは2つの指定されたアドレス範囲をサポートし、 12の行を抽出できます 〜 17 次のように。
$ sed -n '12,17p; 18q' sample_file.txt

コマンドを変更して、上記の出力を file_3.txtに保存できます。 。
$ sed -n '12,17p; 18q' sample_file.txt > file_3.txt $ cat file_3.txt

3。 awkコマンドの使用
awk コマンドは、リダイレクト、ループ、配列などの多数の機能をサポートします。したがって、これを使用して、必要なすべてのファイルパーツ( file_1.txt )を作成できます。 、 file_2.txt 、 file_3.txt 、および file_4.txt )大きなファイル( sample_file.txt )以下に示すように、1つのコマンドフレーズを使用します。
awk コマンドにはキーライン番号( 5 )が付属しています 、 11 、および 17 ) sample_file.txtの分割に必要 4つの部分に分けられます( file_1.txt 、 file_2.txt 、 file_3.txt 、および file_4.txt 。
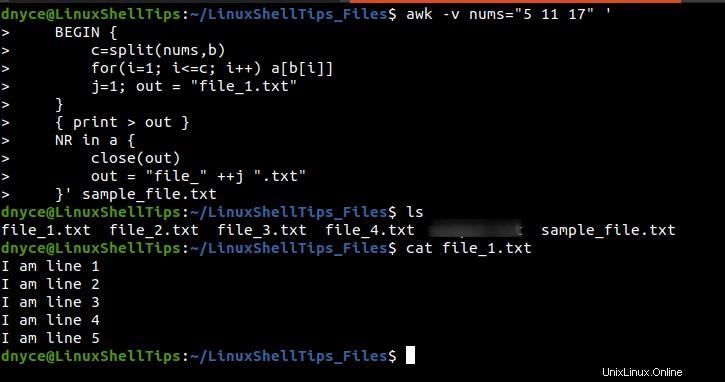
$ awk -v nums="5 11 17" '
BEGIN {
c=split(nums,b)
for(i=1; i<=c; i++) a[b[i]] j=1; out = "file_1.txt" } { print > out }
NR in a {
close(out)
out = "file_" ++j ".txt"
}' sample_file.txt
上記のawkを実行した結果 コマンドは、次のスクリーンキャプチャで明らかです。
このチュートリアルの記事で説明されているように、さまざまなアプローチを通じて、提供された行番号に基づいて大きなファイルを快適にパーツに分割できるようになりました。
次の関連記事もお読みください。
- Linuxで大きな(100GB以上)ファイルを高速にGzip圧縮する方法
- Linuxで1GBまたは10GBの大きなファイルを作成する方法
- Linuxで多数のファイルをコピーする方法