[編集者注:一部の環境ではCPUの固定に既知の制限があるため、このチュートリアルを実行する前に、環境の詳細を必ずお読みください。 ]
CPUはすべてのアプリケーションを実行します。CPUがどのように機能するか、およびCPU使用率を調整してアプリケーションのパフォーマンスを向上させる方法を理解していることが最善です。
最近のシステムには通常、複数のCPUとコアがあり、それらはカーネルスケジューラによって実行中のすべてのソフトウェア間で共有されます。したがって、通常は、アプリケーションまたはプロセスが実行されている限り、どのCPU/コアを実行するかについて気にする必要はありません。
より多くのCPUを取得し、アプリケーションをより適切に動作させ、より効率的に実行する方法は複数あります。 1つの方法は、nice を使用して優先度調整を使用することです。 / renice コマンド。
[次のこともお勧めします:中央処理装置(CPU):そのコンポーネントと機能]
2番目の方法は、「CPUピニング」または「CPUアフィニティ」と呼ばれる、アプリケーションを1つ以上のCPUにバインドすることです。アプリケーションを特定のCPUにバインドすると、アプリケーションに関連するすべてのスレッドまたは子プロセスが、定義されたCPU/CPUで実行されます。このように、プロセス/アプリケーションを1つ以上のCPUに制限すると、「キャッシュウォーム」または「キャッシュヒット」が増え、全体的なパフォーマンスが向上します。 CPUアフィニティの最初の利点は、キャッシュパフォーマンスを最適化することです。 CPUアフィニティの2つ目の利点は、複数のスレッドが同じデータにアクセスしている場合、それらすべてを同じプロセッサで実行することが理にかなっていることです。これにより、キャッシュミスを最小限に抑えることができます。
方法1-優先度の調整
nice を使用してプロセスの優先度を変更する 指図。これはおそらく、アプリケーション/プロセスのCPU使用率を改善するために知られている最も一般的な方法です。
Unixは常にnice()を提供してきました プロセスの優先度を調整するためのシステムコール。これにより、良さが設定されます。 価値。ポジティブなnice 値を指定すると、プロセスの優先度が低くなります(より良い )、および負の値(スーパーユーザー(root)のみが設定可能)を使用すると、優先度が高くなります。
nice 値は、プロセスの優先度を調整するために今日でも役立ちます。あなたの仕事は、優先度の低い作業を特定することです。これには、監視エージェントやスケジュールされたバックアップが含まれる場合があります。これらの作業は、nice で開始するように変更します。 価値。分析を実行して、チューニングが効果的であり、優先度の高い作業でスケジューラーのレイテンシーが低いままであることを確認することもできます。
どのように機能しますか?
すべてのプロセスには、CPUで実行するための指定された時間が与えられます。プロセスがCPUで実行されている実際の時間は、仮想ランタイムと呼ばれます。 プロセスの。ちなみに、CPUは父親のように振る舞う傾向があり、すべての子(プロセス)間で時間を均等に分割する習慣があります。
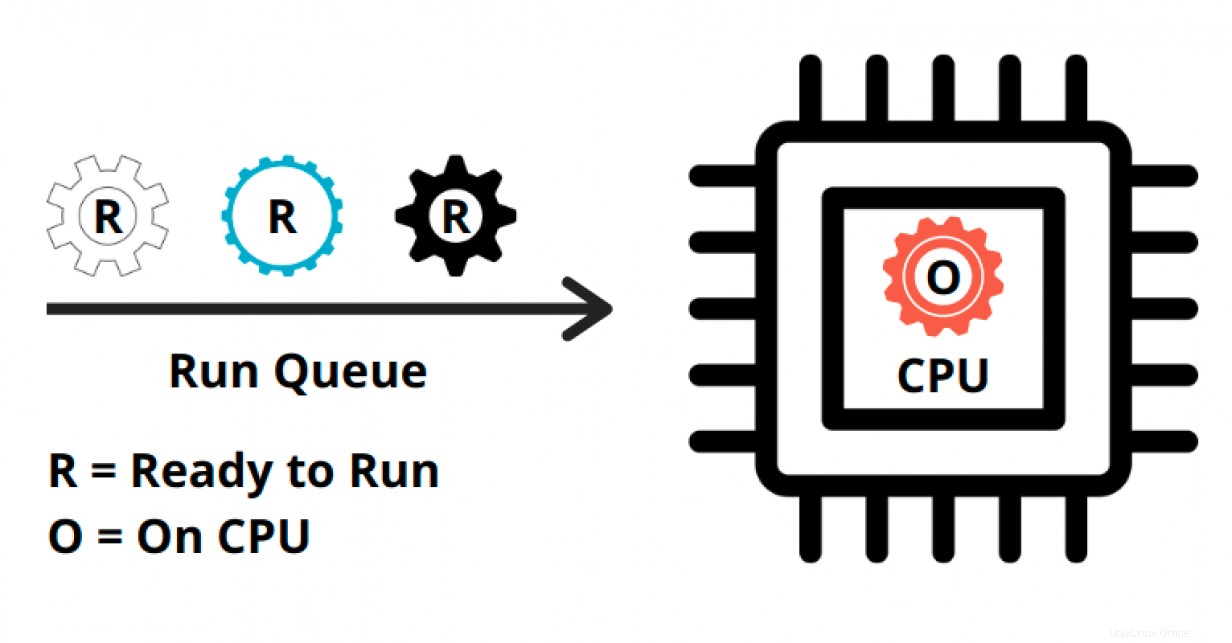
プロセスが「CPU上」で費やす合計時間は、プロセスの仮想ランタイムです。オペレーティングシステム(OS)は、この仮想ランタイムの記録を保持し、実行キュー内のすべてのプロセスに等しい時間を与えようとします。
nice およびrenice ユーティリティはこの仮想ランタイムを操作します。
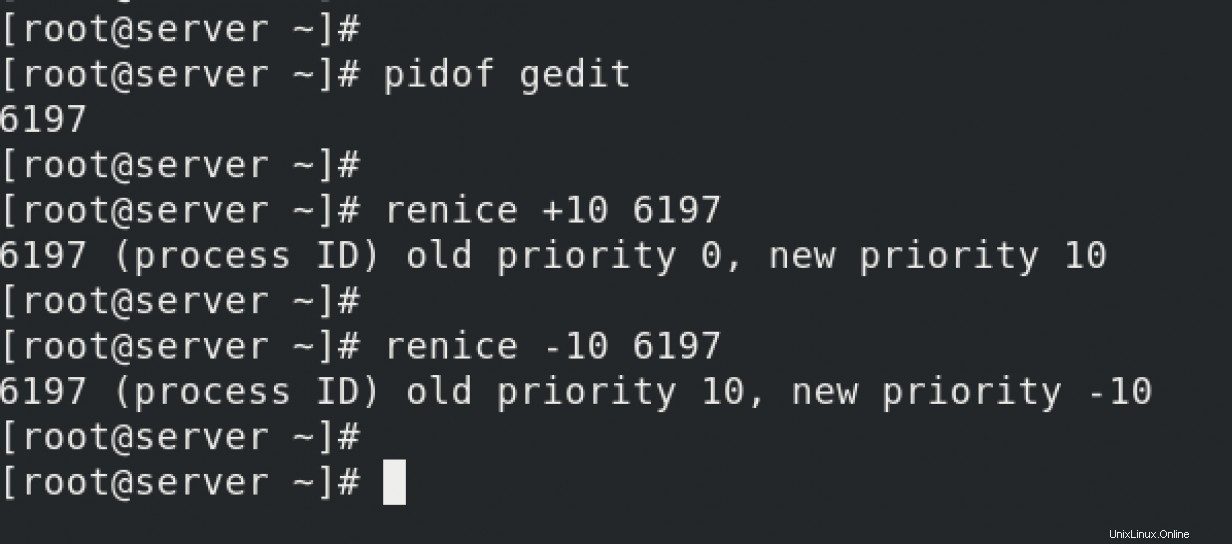
reniceで正の値をフィードする場合 /nice コマンド、たとえば- renice +10 PID 、 プロセスに仮想ランタイムを手動で追加しています。 OSは、プロセスが実行キュー内の他のプロセスよりも多くの仮想ランタイム時間を費やしたと見なします。したがって、次のサイクルでは、CPUがプロセスに与える時間が少なくなります。 reniceの後、「CPUで」時間が少なくなっているため、プロセスは遅く終了します。 コマンド。
ただし、reniceで負の値をフィードする場合 /nice コマンド、たとえば- renice -10 PID 、プロセスの仮想ランタイムを手動で削減しています。 OSは、プロセスが実行キュー内の他のプロセスよりも十分な「CPU上」時間を持っていないと見なします。したがって、次のサイクルでは、CPUは、実行キュー内の他のプロセスと比較して、そのプロセスにより多くの「CPU上」時間を与えます。プロセスは迅速に終了します。
方法2-プロセスバインディング
プロセスは1つ以上のCPUにバインドされる場合があり、キャッシュの暖かさを改善することでパフォーマンスが向上する場合があります。 またはキャッシュヒット およびメモリの局所性 。 Linuxでは、これはtasksetを使用して実行されます CPUマスクを使用できるコマンド または範囲 CPUアフィニティを設定します。
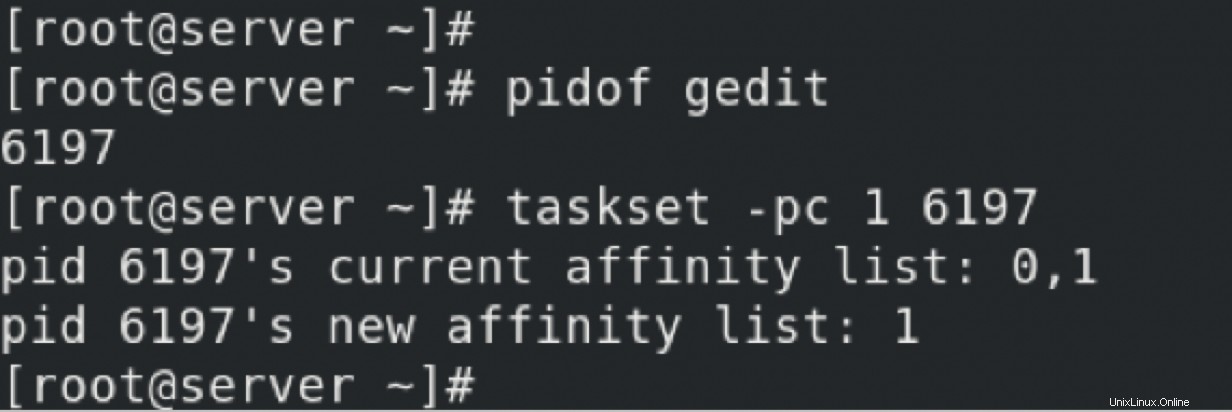
tasksetを使用する 、プロセス6197をCPU 1でのみ実行するようにバインドしました。これにより、キャッシュウォーム/キャッシュヒットが増加します。他のプロセスもCPU1で実行できますが、プロセスはCPU1とCPU2でのみ実行されます。この構成は永続的ではありません。サーバーが再起動するか、プロセスが再起動されると、PIDが変更されます。したがって、この構成は失われます。
より良い方法は、「ドロップイン」ファイルを使用することです。
方法3-ドロップインファイルを介したCPUアフィニティ
ウィキペディアによると、プロセッサ親和性 、またはCPUの固定 または「キャッシュアフィニティ」は、プロセスまたはスレッドを中央処理装置(CPU)または一連のCPUにバインドおよびバインド解除できるようにします。これにより、プロセスまたはスレッドは、CPUではなく指定されたCPUでのみ実行されます。 。
通常、プロセスが実行するCPUを決定するのはカーネルです。スケジューラーがプロセスを再スケジュールするたびに、使用可能なCPUのいずれかに移動できます。これはほとんどのワークロードで問題ありませんが、プロセスの実行を許可するCPUを制限することが望ましい場合があります。たとえば、メモリを大量に消費するプロセスを1つまたは2つのCPUに制限すると、キャッシュヒットの可能性が高くなり、全体的なパフォーマンスが向上します。
どのように機能しますか?
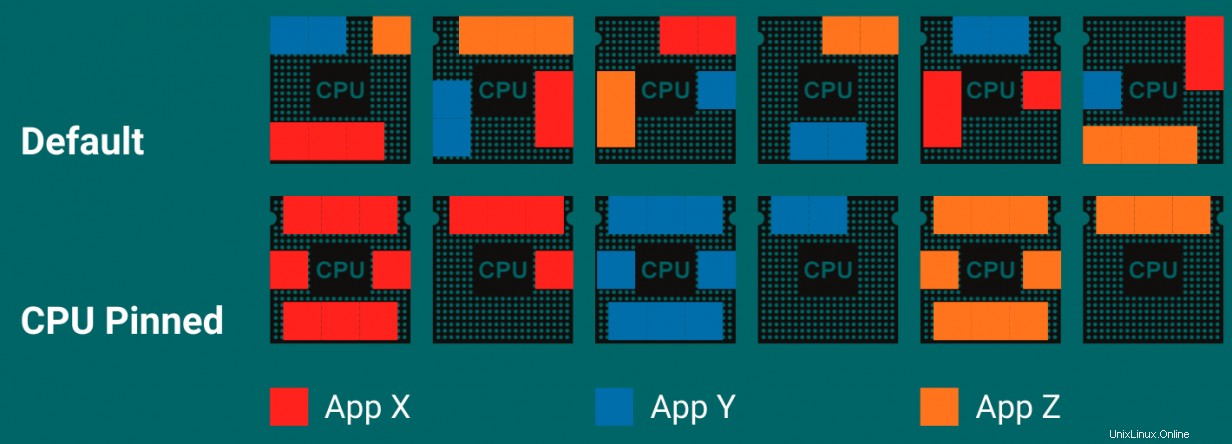
ここに示すように、X、Y、Zの3つのアプリケーションがあります。スケジューラのデフォルトの動作は、使用可能なすべてのCPUを使用して、アプリケーションX、Y、Zのスレッドを実行することです。デフォルト設定を使用すると、次のことがわかります。アプリケーションがすべてのCPUに分散しているため、かなりの数のキャッシュミスが発生します。これにより、キャッシュヒットが少なくなり、キャッシュミスが多くなります。
アプリケーションが特定のCPUに固定されると、アプリケーションは特定のCPUで実行されるように強制されるため、CPUキャッシュをより効果的に使用し、同じCPUでより多くのコードを使用できます。そうすることで、キャッシュウォーム/キャッシュヒットが増え、アプリケーションのパフォーマンスが向上します。
CPU固定/CPUアフィニティを使用してプロセスを特定のプロセッサにバインドする方法を調べるには、sshdを固定します。 CPU0へのプロセス。
sshdの現在のステータスを確認します サービス。バインドするCPUを確認しています。
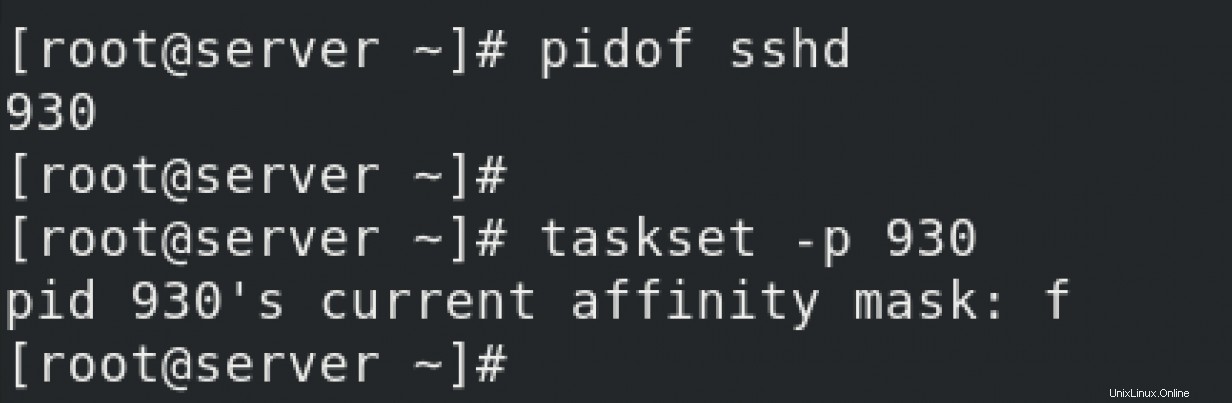
tasksetによると コマンドのマニュアルページ、値f 「任意のCPU」を意味します。したがって、sshd用に構成されたCPUの固定またはバインドはありません。 サービス。
sshdをバインドします CPU0へのサービス-ドロップインの作成 sshdの動作を制御するために使用するファイル サービス。ドロップインファイルは、プロセスに関連する多くのことを制御しますが、現在、CPUの固定/アフィニティに制限されています。
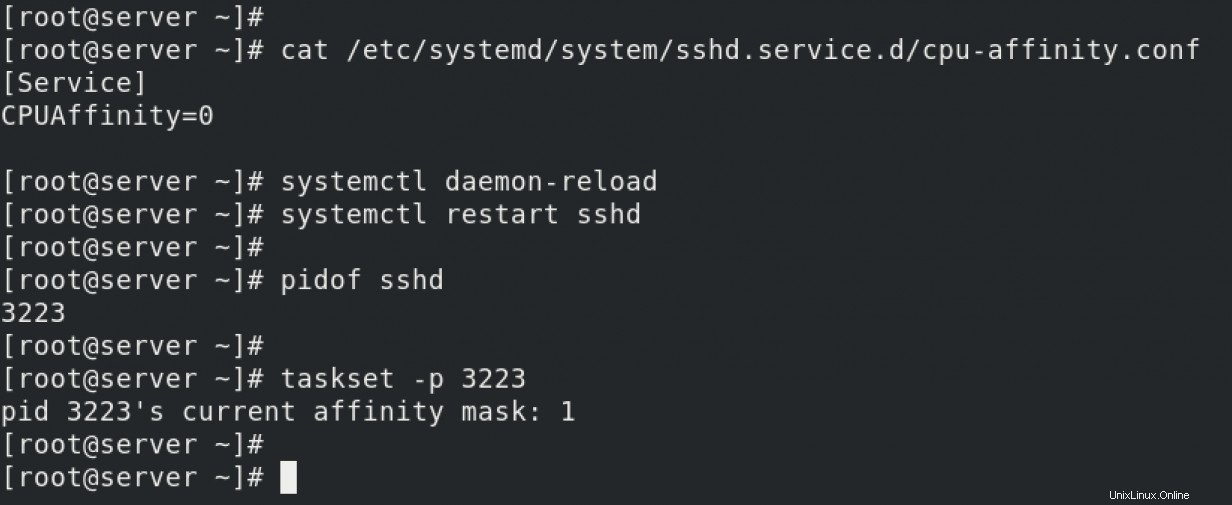
tasksetがどのようになっているのかがわかります コマンドはCPUを「1」として表示しています。これはtasksetによると、 マニュアルページは、利用可能な最初のCPUです。
sshdのステータスを確認することで、ドロップインファイルをさらに確認できます。 サービス。
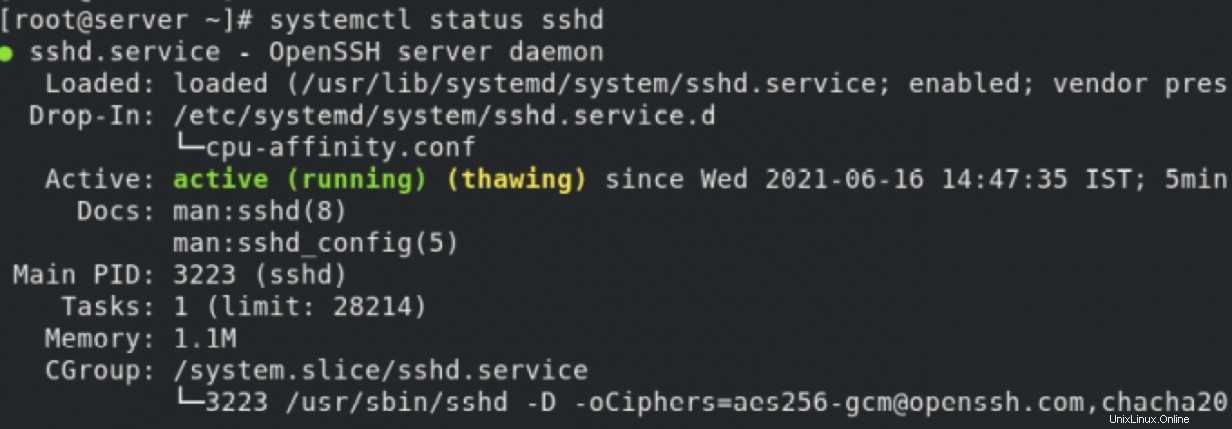
まとめ
どちらのnice も使用できます またはrenice プロセスの優先度を変更します。両方のnice およびrenice コマンドは、プロセスの「仮想ランタイム」を操作できます。したがって、値に基づいて、プロセスはCPUに多かれ少なかれ時間を費やします。
プロセスを1つ以上のCPUにバインド/固定できます。これにより、キャッシュウォーム/キャッシュヒットが増える可能性が高くなり、パフォーマンスが大幅に向上します。 tasksetを使用できます この目的のためのコマンドラインツール。ただし、その影響は一時的なものにすぎません。構成を永続的にする場合は、「ドロップイン」ファイルを使用する必要があります。
[無料のオンラインコース:Red HatEnterpriseLinuxの技術概要。 ]