この記事では、Red Hat Enterprise Linux(RHEL)仮想マシン(VM)に格納されているデータのバックアップについて学んだことについて説明します。 Linuxを使用して最初の年に、クラウドにデプロイされたLinuxVMにデータをバックアップすることを思いつきました。
データのバックアップはビジネス上の大きな問題です。サイバー脅威、ユーザーエラー、システム障害の数が増えるにつれ、データは安全ではなくなります。データをバックアップすることで、セキュリティ違反、誤った削除、またはシステム障害が発生した場合に重要なファイルやフォルダが失われるのを防ぐことができます。個人および中小企業は、データを外部ハードディスクまたはバックアップサーバーにバックアップできますが、データ量が膨大な(ペタバイト規模)大企業の場合、データのバックアップは複雑であり、少なくとも多くの場合実行されます。部分的には、何らかの形のクラウドアーキテクチャで。
[次のこともお勧めします:tarコマンドを使いこなす:Linuxでバックアップを管理するためのヒント]
オンプレミスのデータセンターへのバックアップなど、データをバックアップする方法はたくさんありますが、ストレージを最適化するための複数の方法を提供するため、バックアップにクラウドを選択する企業もあります。クラウド機能を使用すると、データをバックアップするために世界中から任意の場所を選択できます。単一の地域でシステムのクラッシュや局地的な自然災害が発生した場合でも、データは別の場所に正常にバックアップされるため、この機能は不可欠です。
RHEL仮想マシンの作成
まず、RHEL仮想マシンを作成する必要があります。そのために任意のクラウドプラットフォームを選択できます。この記事の目的は、特定のクラウドプロバイダーに固有の詳細ではなく、一般的な手法を示すことです。この仮想マシンにはすべてのデータが含まれています。
VMを作成した後、別のゾーン(地理的な場所)に別のRedHat仮想マシンを作成します。この仮想マシンを使用して、バックアップされたデータを保存します。
1つのゾーンで障害や災害が発生した場合、そのゾーンの仮想マシンは使用できなくなりますが、リモートの複製VMは使用できるため、異なるゾーンに2つの仮想マシンを作成しました。
ボリュームの作成
インスタンスを作成したら、ボリュームを作成して、バックアップする必要のあるインスタンスにアタッチします。ボリュームは、パフォーマンスを向上させ、遅延を減らすために仮想マシン(VM)に接続された仮想ハードディスクです。通常、ボリュームは、VMに保存されているデータのバックアップを取る必要があるときに接続されます。
クラウドプラットフォーム自体でボリュームを作成できます。
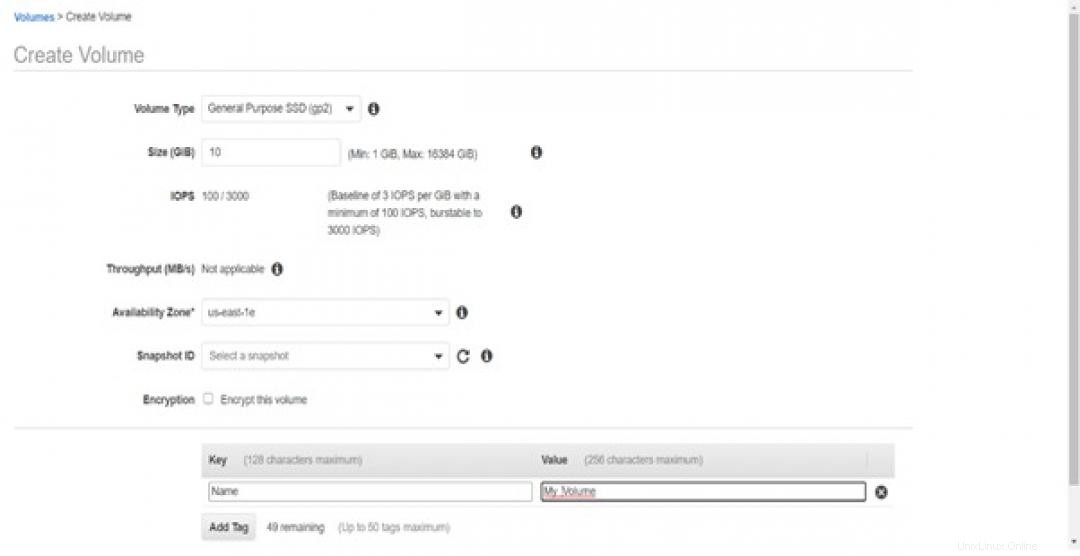
ボリュームを作成するには、必要なボリュームのサイズなどの詳細を指定し、バックアップを作成しているRedHatインスタンスのゾーンを選択する必要があります。
ボリュームをRedHatインスタンスに接続する
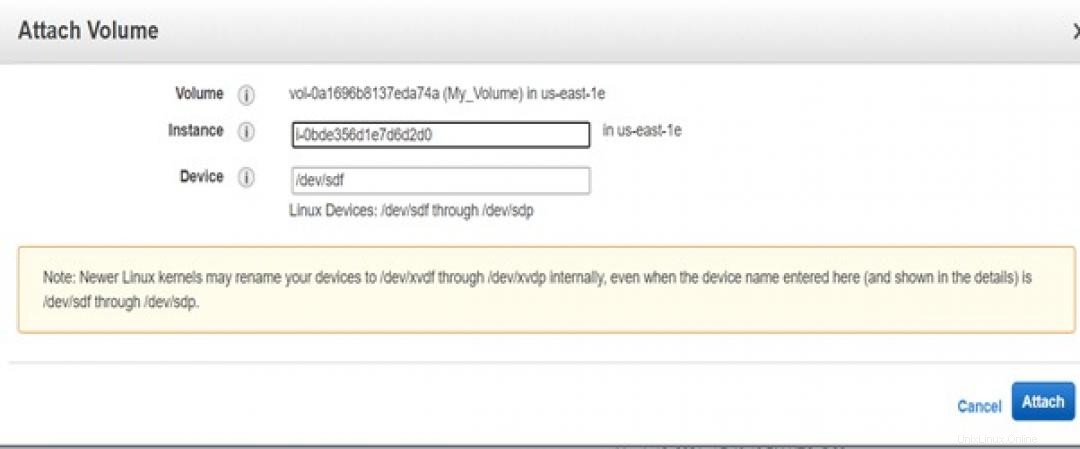
ボリュームが正常に作成されたら、ボリュームをRedHat仮想マシンに接続します。
PuTTYを使用したSSH接続の作成
次に、PuTTYを使用して、RedHatインスタンスとローカルシステムの安全な接続を作成します。 PuTTYは、SCP、Telnet、SSHなどのさまざまなネットワークプロトコルをサポートするオープンソースソフトウェアです。接続は、RedHatインスタンスのパブリックIPアドレスを使用して確立されます。
VMへのボリュームのマウント
作成したボリュームは添付されたばかりで、 RedHat仮想マシンにマウントされています。
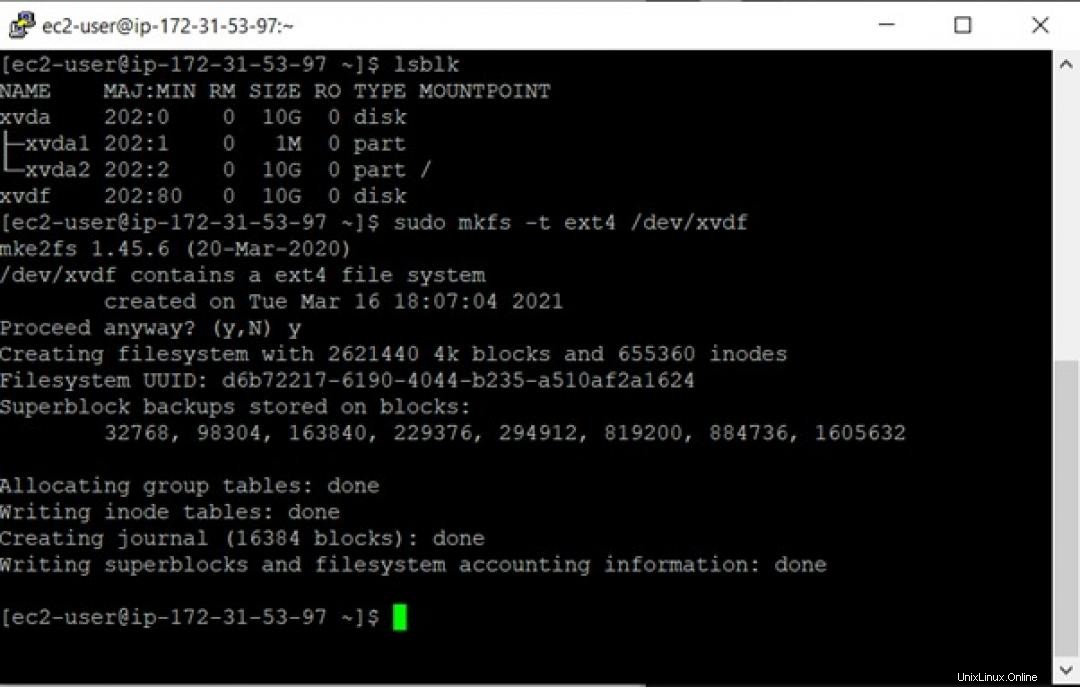
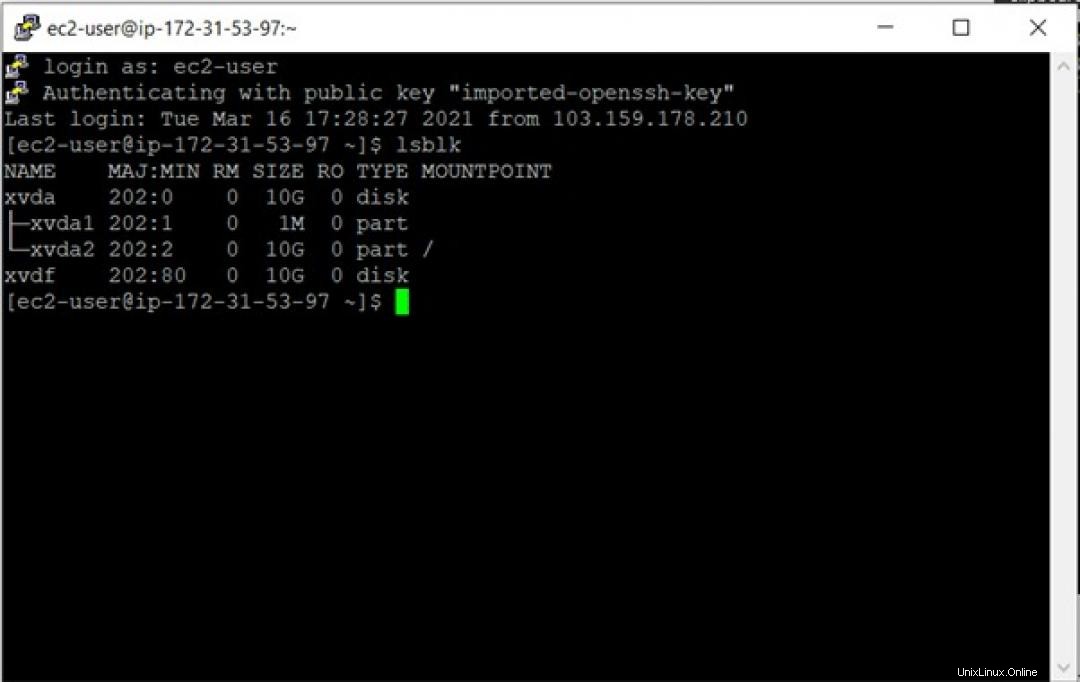
接続されているボリュームの名前を確認するには、コマンドlsblkを使用できます。 。 lsblk コマンドは、存在するすべてのブロックデバイスの情報を一覧表示します。
ここで、コマンドsudo mkfs -t ext4 /dev/xvdfを使用してボリュームをフォーマットします。 、ここで xvdf ボリュームの名前です。
ボリュームをフォーマットした後、RedHat仮想マシンにボリュームをマウントします。
まず、インスタンスにディレクトリを作成します。これを行うには、次のコマンドを使用します。
$ sudo mkdir /mnt/mydisk
ここで、mydiskという名前のディレクトリにボリュームをマウントします。 このコマンドの使用:
$ sudo mount /dev/xvdf /mnt/mydisk 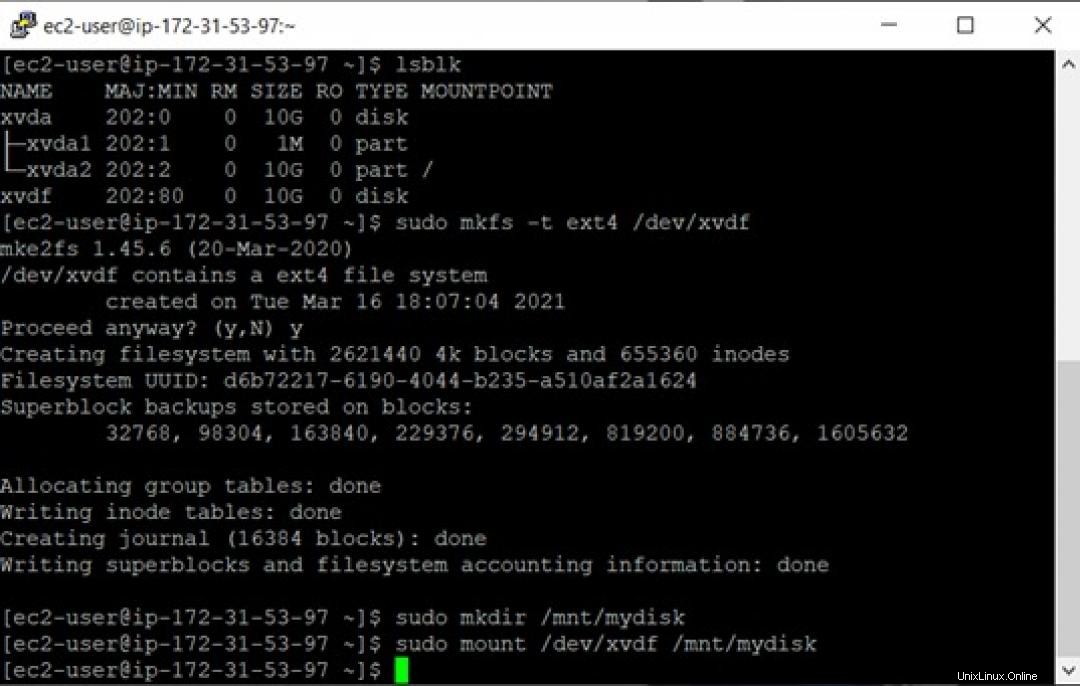
ボリューム内でのファイルの作成
ディレクトリmydiskにあるボリュームにサンプルファイルを作成します 。
ボリュームにファイルを作成するコマンドはsudo vim testです。 、ここでtest ファイルの名前です。ファイルに何かを書き込んで、バックアップしたいデータとして保存します。
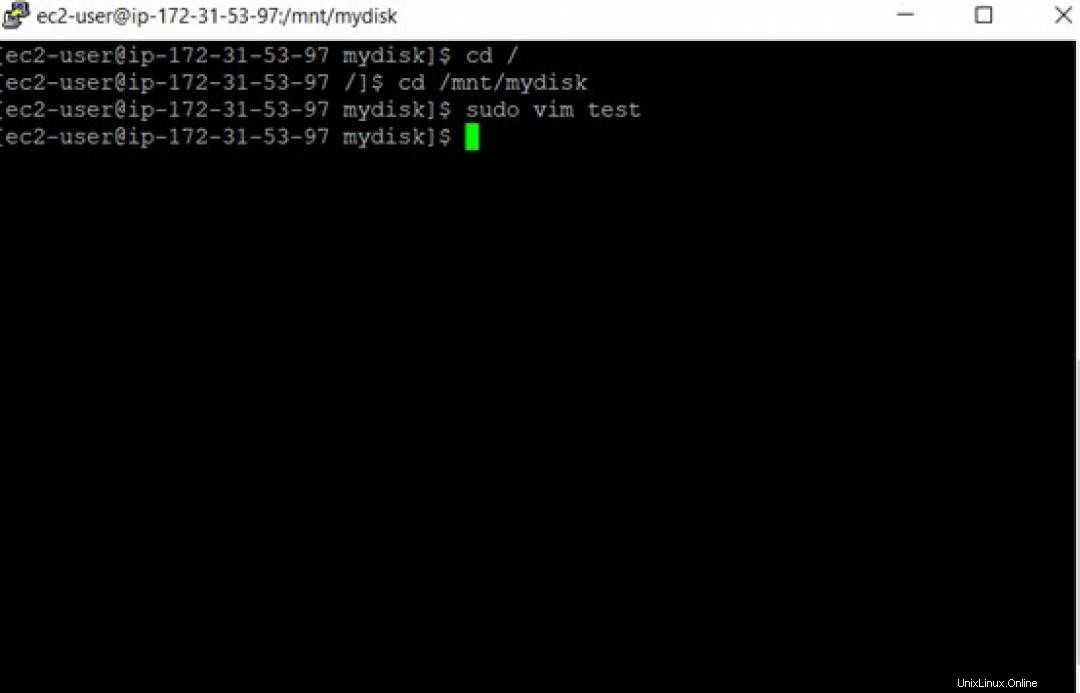
要約すると、ボリュームが作成され、インスタンスにアタッチされました。次に、ボリュームをインスタンスにマウントしました。次に、データを含むボリュームにサンプルファイルを作成しました。
次に、インスタンスからボリュームをアンマウントします。
インスタンスからボリュームをアンマウントするコマンドは次のとおりです。
$ sudo umount /mnt/mydisk データバックアップの作成
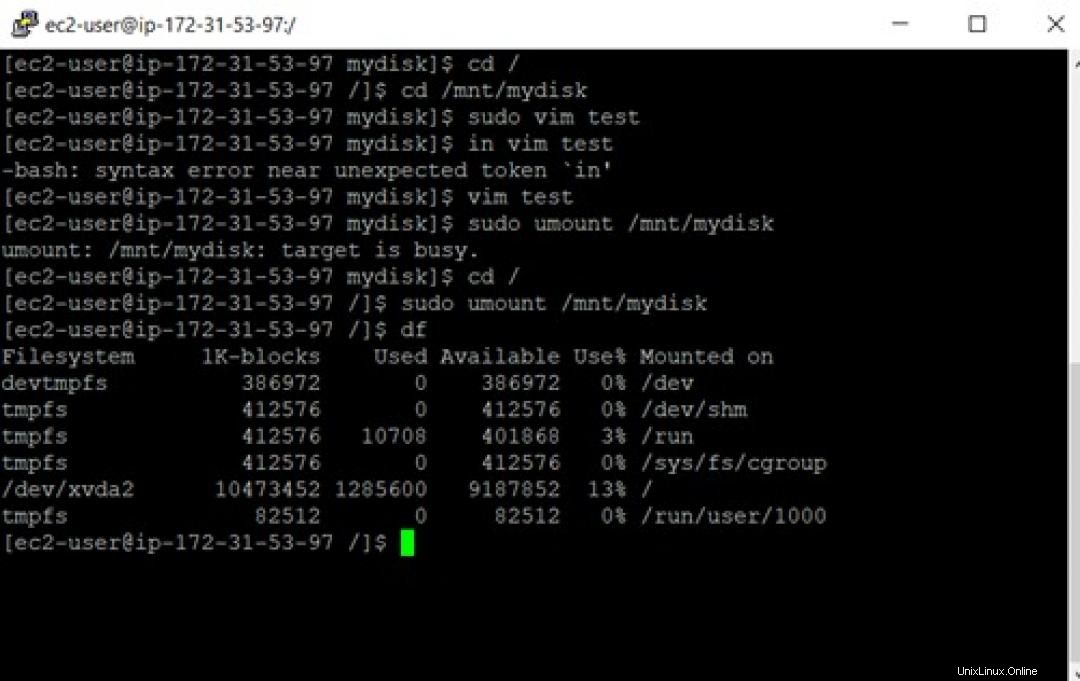
ここで注意すべき主な点は、ボリュームはまだインスタンスに接続されていますが、は接続されていないということです。 インスタンスにマウントされています。
次のタスクは、ボリュームをバックアップインスタンスに接続することです。ただし、両方の仮想マシンが異なるゾーンに存在するため、ボリュームを現在のインスタンスから直接デタッチしてバックアップインスタンスに接続することはできません。
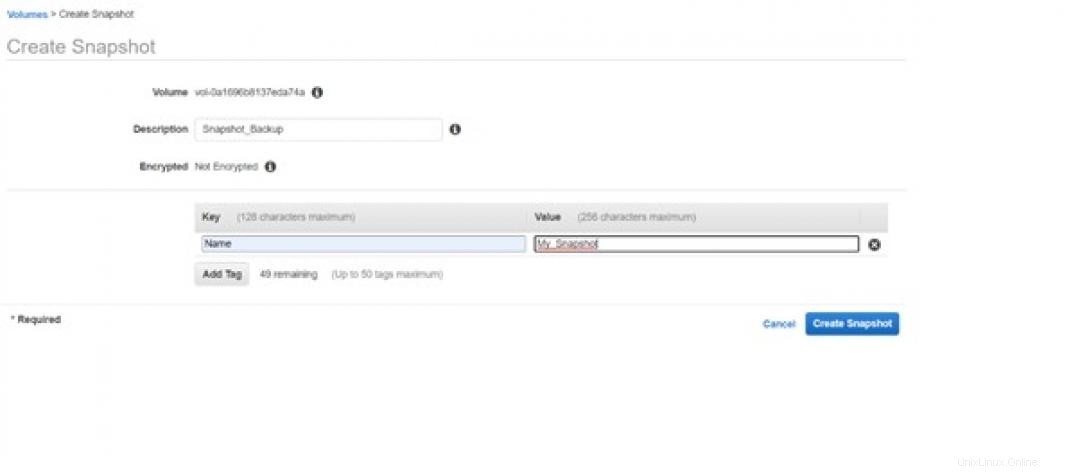
まず、以前に作成したボリュームに関連付けられるスナップショットを作成します。
スナップショットは、ボリュームに保存されているデータをバックアップするために使用されるストレージです。ユーザーが使用するクラウドポータルからスナップショットを作成できます。
スナップショットを作成したら、ボリュームを切り離します。その後、ボリュームはスナップショットよりもはるかにコストがかかるため、インスタンスから削除されます。これは、スナップショットが単純なストレージサービスであるためです。また、必要なときにいつでもスナップショットからボリュームを簡単に作成できます。
次に、前に作成したスナップショットからボリュームを作成します。このボリュームを、データをバックアップするインスタンスに接続します。
ボリュームを作成してインスタンスにアタッチする手順は、上記と同じです。
次に、インスタンスのパブリックIPを使用してPuTTYをバックアップインスタンスに接続します。
lsblkを使用する コマンドを使用すると、ボリュームがインスタンスに接続されているが、インスタンスにマウントされていないことを確認できます。
ボリュームをインスタンスにマウントする前に、ファイルシステムがないため、フォーマットする必要があります。ボリュームはすでにファイルシステムを備えているスナップショットから作成されるため、フォーマットする必要があります。
最後に、ボリュームをインスタンスにマウントします。
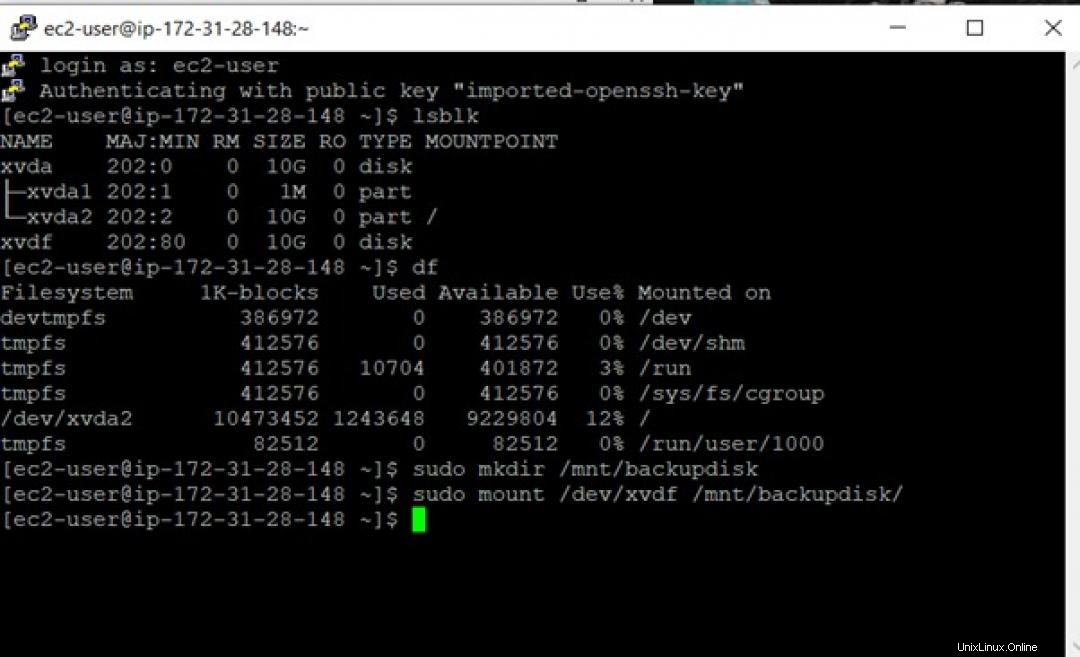
このボリュームは、backupdiskという名前のディレクトリにマウントされます 。
backupdiskの内部に移動します ディレクトリを作成し、テストファイルが存在するかどうかを確認します。これは、RedHatインスタンスに接続されたボリュームで以前に作成したファイルです。
サンプルのtestかどうかを確認する必要があります Red Hatインスタンスに接続されたボリュームで以前に作成したファイルは、backupdiskに正常にバックアップされました。 バックアップインスタンスに存在するディレクトリ。そのためのコマンドは次のとおりです。
$ ls -ltr 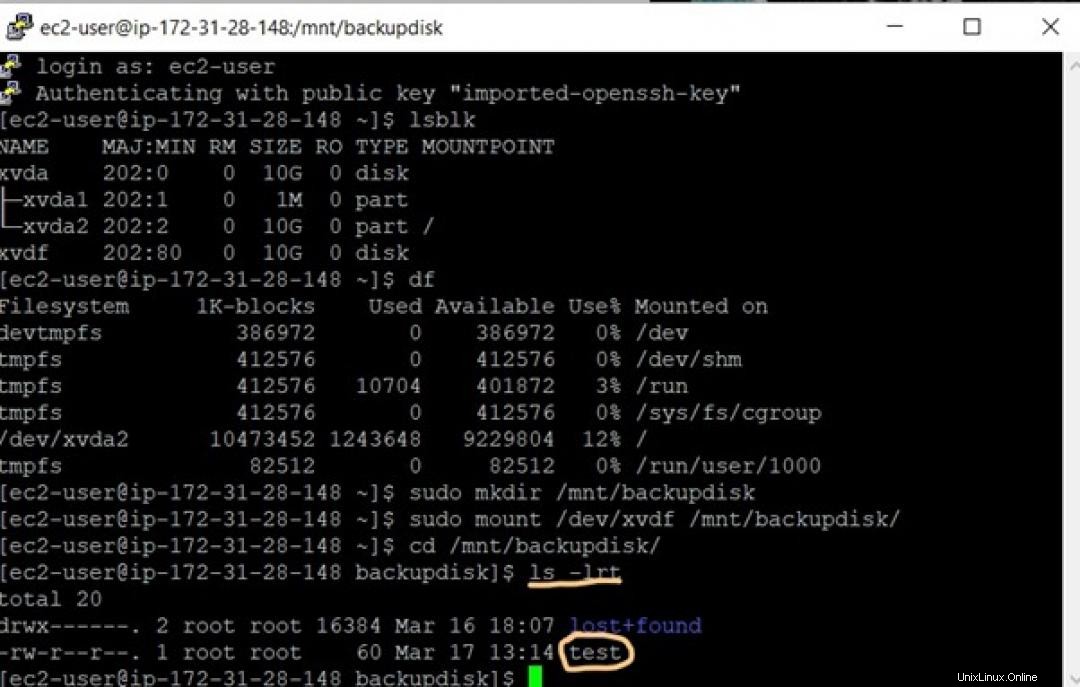
したがって、テストファイルがまだ存在し、正常にバックアップされていることがわかります。
ファイルの内容も正常にバックアップされたかどうかを確認するには、次のコマンドを入力してファイルの内容を表示します。
$ cat test 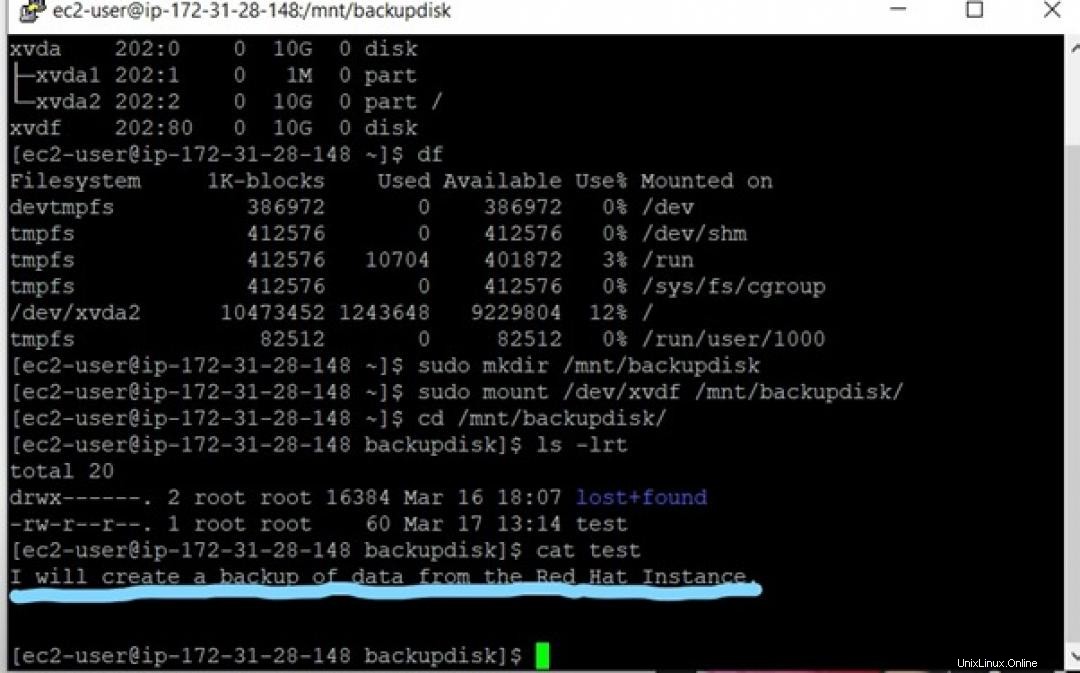
データもバックアップされました。
[コンテナを使い始めますか?この無料コースをチェックしてください。コンテナ化されたアプリケーションのデプロイ:技術的な概要。
まとめ
この記事では、データのバックアップがビジネスの継続性に不可欠である理由について説明します。大量のデータを扱う一部の企業や組織は、重複排除、圧縮、暗号化、地理的多様性などの最適化のための複数のオプションを提供するため、データをクラウドプラットフォームにバックアップします。
あるゾーンのVMに保存されているデータを、別のゾーンの2番目のインスタンスにバックアップする手順を提供しました。これにより、データの冗長性が確保され、一方のシステムに障害が発生したり、一方のゾーンで災害が発生した場合でも、ユーザーのデータは安全で、もう一方のゾーンで利用できます。