この記事では、マウントについて説明します。 名前空間であり、LinuxNamespaceシリーズの3番目です。最初の記事では、最も一般的に使用される7つの名前空間を紹介し、ユーザーの名前空間の記事で開始された実践的な作業の基礎を築きました。私の目標は、Linuxコンテナーの基盤がどのように機能するかについての基本的な知識を構築することです。 Linuxがシステム上のリソースをどのように制御するかに興味がある場合は、先ほど書いたCGroupシリーズをチェックしてください。うまくいけば、名前空間の実践的な作業が完了するまでに、CGroupsと名前空間を意味のある方法で結び付けて全体像を完成させることができます。
ただし、現時点では、この記事では、マウント名前空間と、Linuxコンテナーがシステム管理者、ひいてはOpenShiftやKubernetesなどのプラットフォームにもたらす分離を理解するのにどのように役立つかについて説明します。
[次のこともお勧めします:Podmanコンテナで補足グループを共有する]
マウント名前空間
新しいユーザー名前空間を作成した後、マウント名前空間が期待どおりに動作しません。デフォルトでは、unshare -mを使用して新しいマウント名前空間を作成する場合 、システムに対するあなたの見方はほとんど変わらず、制限されません。これは、新しいマウント名前空間を作成するたびに、コピーが実行されるためです。 親名前空間からのマウントポイントの数は、新しいマウント名前空間に作成されます。つまり、適切に構成されていないマウント名前空間内のファイルに対して実行されるアクションはすべて ホストに影響を与えます。
マウント名前空間のセットアップ手順
では、マウント名前空間はどのように使用されますか?これを実証するために、AlpineLinuxのtarballを使用します。
要約すると、ダウンロードして解凍し、新しいディレクトリに移動して、権限のないユーザーに最上位のディレクトリ権限を付与します。
[root@localhost ~] export CONTAINER_ROOT_FOLDER=/container_practice
[root@localhost ~] mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
[root@localhost ~] cd ${CONTAINER_ROOT_FOLDER}
[root@localhost ~] wget https://dl-cdn.alpinelinux.org/alpine/v3.13/releases/x86_64/alpine-minirootfs-3.13.1-x86_64.tar.gz
[root@localhost ~] tar xvf alpine-minirootfs-3.13.1-x86_64.tar.gz -C fakeroot
[root@localhost ~] chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakeroot
fakeroot ディレクトリはユーザーcontainer-userが所有する必要があります 新しいユーザー名前空間を作成すると、ルート 新しい名前空間のユーザーは、 container-userにマップされます 名前空間の外。これは、新しい名前空間内のプロセスが、ファイルを変更するために必要な機能を備えていると見なすことを意味します。それでも、ホストのファイルシステムのアクセス許可により、 container-userが阻止されます。 tarball( root を持つ)からAlpineファイルを変更することからのアカウント 所有者として)。
では、単に新しいマウント名前空間を開始するとどうなりますか?
PS1='\u@new-mnt$ ' unshare -Umr 新しい名前空間内にいるので、ホストからの元のマウントポイントが表示されない可能性があります。ただし、そうではありません:
root@new-mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cs-root 36G 5.2G 31G 15% /
tmpfs 737M 0 737M 0% /sys/fs/cgroup
devtmpfs 720M 0 720M 0% /dev
tmpfs 737M 0 737M 0% /dev/shm
tmpfs 737M 8.6M 728M 2% /run
tmpfs 148M 0 148M 0% /run/user/0
/dev/vda1 976M 197M 713M 22% /boot
root@new-mnt$ ls /
bin container_practice etc lib media opt root sbin sys usr
boot dev home lib64 mnt proc run srv tmp var
この理由は、systemd デフォルトでは、すべての新しい名前空間とマウントポイントを再帰的に共有します。 tmpfsをマウントした場合 ファイルシステム(例:/mnt) 新しいマウント名前空間内で、ホストはそれを見ることができますか?
root@new-mnt$ mount -t tmpfs tmpfs /mnt
root@new-mnt$ findmnt |grep mnt
└─/mnt tmpfs tmpfs rw,relatime,seclabel,uid=1000,gid=1000 ただし、ホストはこれを認識しません:
[root@localhost ~]# findmnt |grep mnt したがって、少なくとも、マウント名前空間が正しく機能していることがわかります。これは、マウントポイントの伝播について話し合うために少し回り道をする良い機会です。簡単に要約しますが、理解を深めたい場合は、MichaelKerriskのLWNの記事とmount名前空間のマニュアルページをご覧ください。私は通常、manページにあまり依存しないので、簡単に消化できないことがよくあります。ただし、この場合、それらは例でいっぱいで、(ほとんど)平易な英語です。
マウントポイントの理論
共有サブツリーと呼ばれるカーネルの機能により、マウントはデフォルトで伝播します 。これにより、すべてのマウントポイントに独自の伝播タイプを関連付けることができます。このメタデータは、特定のパスの下の新しいマウントが他のマウントポイントに伝播されるかどうかを決定します。マニュアルページに示されている例は、光ディスクの例です。光ディスクが/cdromの下に自動的にマウントされた場合 、適切な伝播タイプが設定されている場合、コンテンツは他の名前空間でのみ表示されます。
ピアグループとマウント状態
カーネルのドキュメントには、「ピアグループ は、イベントを相互に伝播するvfsmountのグループとして定義されます。」イベントとは、ネットワーク共有のマウントや光デバイスのアンマウントなどです。なぜこれが重要なのか、質問します。マウント名前空間に関しては、ピアグループです。 多くの場合、マウントが表示され、相互作用できるかどうかを決定する要因になります。 マウント状態 ピアグループのメンバーがイベントを受信できるかどうかを決定します。同じカーネルのドキュメントによると、5つのマウント状態があります:
- 共有 -ピアグループに属するマウント。発生した変更はすべて、ピアグループのすべてのメンバーに伝播されます。
- スレーブ -一方向の伝播。マスターマウントポイントはイベントをスレーブに伝播しますが、マスターはスレーブが実行するアクションを認識しません。
- 共有およびスレーブ -マウントポイントにマスターがあるが、独自のピアグループもあることを示します。マスターにはマウントポイントの変更は通知されませんが、ダウンストリームのピアグループメンバーには通知されます。
- プライベート -伝播イベントを受信または転送しません。
- バインド不可 -伝播イベントを受信または転送せず、できません バインドマウントされます。
マウントポイントの状態はマウントポイントごとであることに注意してください。 。これは、/がある場合を意味します および/boot たとえば、各マウントポイントに目的の状態を個別に適用する必要があります。
コンテナについて疑問がある場合、ほとんどのコンテナエンジンは、コンテナ内にボリュームをマウントするときにプライベートマウント状態を使用します。今のところ、これについてはあまり心配しないでください。コンテキストを提供したいだけです。特定のマウントシナリオを試したい場合は、例が非常に優れているため、マニュアルページを参照してください。
マウント名前空間の作成
GoやCなどのプログラミング言語を使用している場合は、生のシステムカーネル呼び出しを使用して、新しい名前空間に適切な環境を作成できます。ただし、この背後にある目的は、既存のコンテナとの対話方法を理解するのに役立つため、新しいマウント名前空間を目的の状態にするために、bashのトリックを実行する必要があります。
まず、通常のユーザーとして新しいマウント名前空間を作成します。
unshare -Urm
名前空間に入ったら、findmntを見てください。 ルートファイルシステムを含むマッパーデバイスの例(簡潔にするために、出力からほとんどのマウントオプションを削除しました):
findmnt |grep mapper
/ /dev/mapper/cs-root xfs rw,relatime,[...] ルートデバイスマッパーを持つマウントポイントは1つだけです。マッパーデバイスをAlpineディレクトリにバインドする必要があるため、これは重要です。
export CONTAINER_ROOT_FOLDER=/container_practice
mount --bind ${CONTAINER_ROOT_FOLDER}/fakeroot ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}/fakeroot
これは、pivot_rootというユーティリティを使用しているためです。 chrootを実行するには -アクションのように。 pivot_root 2つの引数を取ります:new_root およびold_root (put_oldと呼ばれることもあります )。 pivot_root 現在のプロセスのルートファイルシステムをディレクトリput_oldに移動します new_rootを作成します 新しいルートファイルシステム。
重要 :chrootに関するメモ 。 chroot 多くの場合、追加のセキュリティ上の利点があると考えられています。ある程度、これは真実です。それから抜け出すには、より多くの専門知識が必要だからです。慎重に構築されたchroot 非常に安全です。ただし、chroot 以前の名前空間の記事で触れたLinux機能を変更または制限しません。また、カーネルへのシステムコールを制限することもありません。これは、十分に熟練した攻撃者がchrootから逃れる可能性があることを意味します。 それはよく考えられていません。マウントとユーザーの名前空間は、この問題の解決に役立ちます。
pivot_rootを使用する場合 バインドマウントがない場合、コマンドは次のように応答します:
pivot_root: failed to change root from `.' to `old_root/': Invalid argument
アルパインルートファイルシステムに切り替えるには、まず、old_rootのディレクトリを作成します 次に、目的の(アルパイン)ルートファイルシステムにピボットします。 AlpineLinuxのルートファイルシステムには/binのシンボリックリンクがないため および/sbin 、パスにそれらを追加してから、最後にold_rootをアンマウントする必要があります :
mkdir old_root
pivot_root . old_root
PATH=/bin:/sbin:$PATH
umount -l /old_root
これで、ユーザーがいる素晴らしい環境ができました。 およびマウント 名前空間は連携して、ホストからの分離層を提供します。ホスト上のバイナリにアクセスできなくなります。 findmntを発行してみてください 以前に使用したコマンド:
root@new-mnt$ findmnt
-bash: findmnt: command not found ルートファイルシステムを確認したり、マウントされているものを確認したりすることもできます。
root@new-mnt$ ls -l /
total 12
drwxr-xr-x 2 root root 4096 Jan 28 21:51 bin
drwxr-xr-x 2 root root 18 Feb 17 22:53 dev
drwxr-xr-x 15 root root 4096 Jan 28 21:51 etc
drwxr-xr-x 2 root root 6 Jan 28 21:51 home
drwxr-xr-x 7 root root 247 Jan 28 21:51 lib
drwxr-xr-x 5 root root 44 Jan 28 21:51 media
drwxr-xr-x 2 root root 6 Jan 28 21:51 mnt
drwxrwxr-x 2 root root 6 Feb 17 23:09 old_root
drwxr-xr-x 2 root root 6 Jan 28 21:51 opt
drwxr-xr-x 2 root root 6 Jan 28 21:51 proc
drwxr-xr-x 2 root root 6 Feb 17 22:53 put_old
drwx------ 2 root root 27 Feb 17 22:53 root
drwxr-xr-x 2 root root 6 Jan 28 21:51 run
drwxr-xr-x 2 root root 4096 Jan 28 21:51 sbin
drwxr-xr-x 2 root root 6 Jan 28 21:51 srv
drwxr-xr-x 2 root root 6 Jan 28 21:51 sys
drwxrwxrwt 2 root root 6 Feb 19 16:38 tmp
drwxr-xr-x 7 root root 66 Jan 28 21:51 usr
drwxr-xr-x 12 root root 137 Jan 28 21:51 var
root@new-mnt$ mount
mount: no /proc/mounts
興味深いことに、procはありません デフォルトでマウントされたファイルシステム。マウントしてみてください:
root@new-mnt$ mount -t proc proc /proc
mount: permission denied (are you root?)
root@new-mnt$ whoami
root
proc は、PID名前空間に関連する特殊なタイプのマウントであり、独自のマウント名前空間にいる場合でもマウントできません。これは、前に説明した機能の継承に戻ります。この議論は、次の記事でPID名前空間について説明するときに取り上げます。ただし、継承についての注意として、下の図をご覧ください。
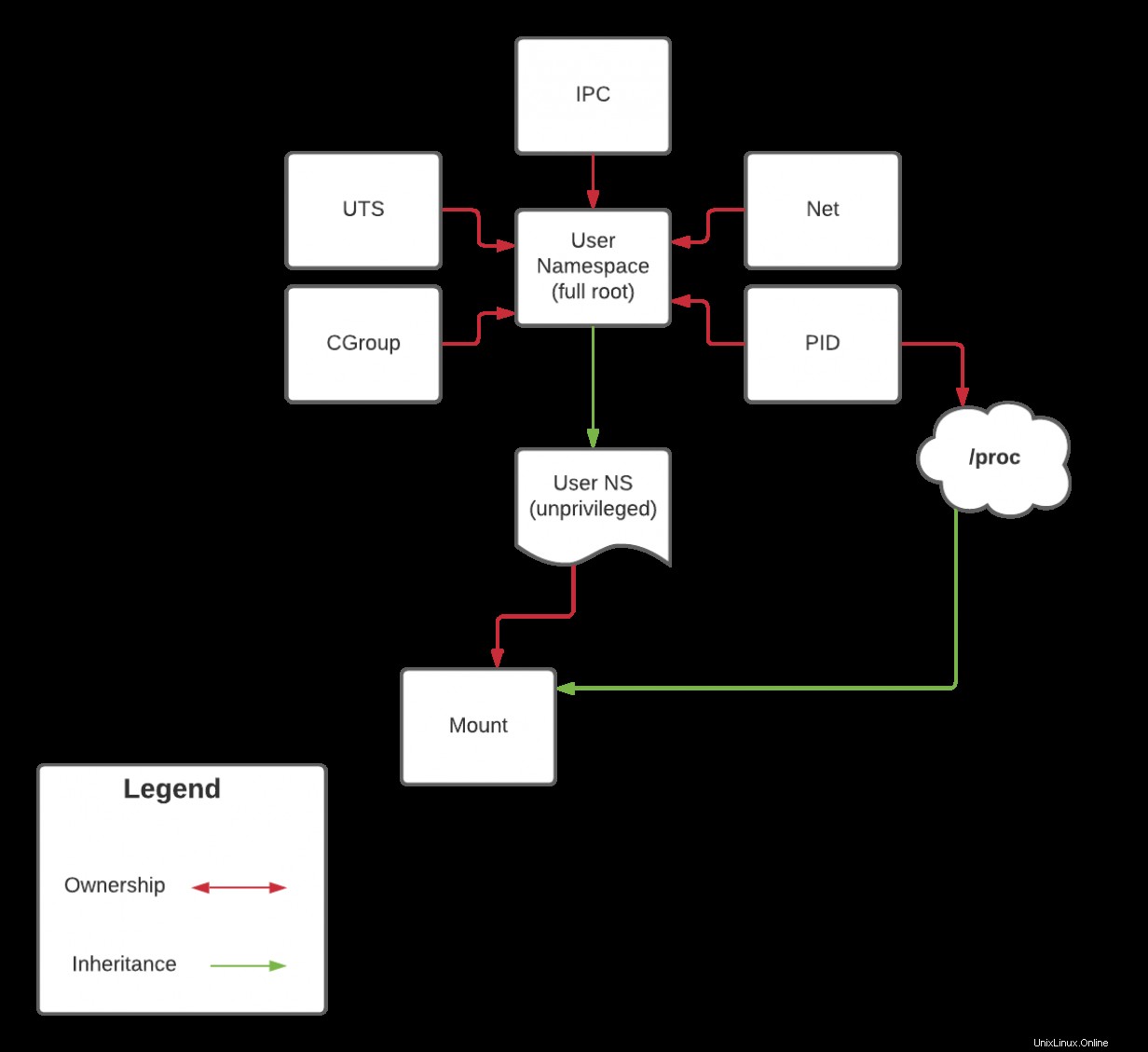
次の記事では、この図を再ハッシュしますが、最初から続けていれば、それまでにいくつかの推論を行うことができるはずです。
[APIオーナーズマニュアル:効果的なAPIプログラムの7つのベストプラクティス]
まとめ
この記事では、マウント名前空間に関するより深い理論について説明しました。ピアグループと、それらがシステムの各マウントポイントに適用されるマウント状態にどのように関連するかについて説明しました。実践的な部分として、最小限のAlpine Linuxファイルシステムをダウンロードしてから、ユーザーとマウントの名前空間を使用して、chrootによく似た環境を作成する方法を説明しました。 潜在的により安全なことを除いて。
今のところ、新しい名前空間の内外でファイルシステムのマウントをテストします。 共有を使用する新しいマウントポイントを作成してみてください 、プライベート 、およびスレーブ マウント状態。次の記事では、PID名前空間を使用して、プリミティブコンテナを構築し続け、procにアクセスします。 ファイルシステムとプロセスの分離。